
ارزیابی مدل ها بر مبنای طرح آزمون استفاده شده در فاز مدل سازی، به مقایسه مقادیر واقعی و مقادیر پیش بینی شده، توسط مدل می پردازد.
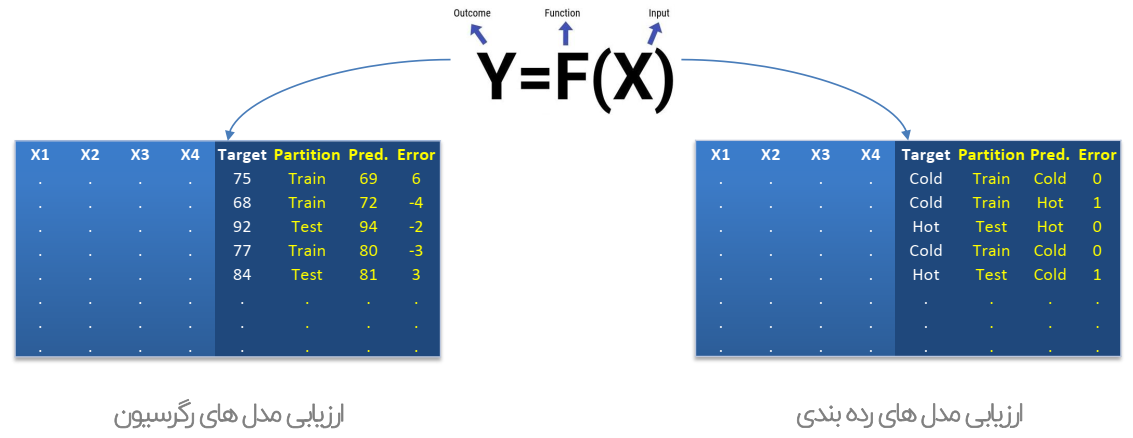
شاخص صحت (Accuracy):
به طور کلی، دقت به این معناست که مدل تا چه اندازه خروجی را درست پیشبینی میکند. با نگاه کردن به دقت ، بلافاصله میتوان دریافت که آیا مدل درست آموزش دیده است یا خیر و کارایی آن به طور کلی چگونه است. اما این معیار اطلاعات جزئی در مورد کارایی مدل ارائه نمیدهد.
شاخص ساده و پرکاربرد در ارزیابی مدل های رده بندی است که نسبت رکوردهای با پیش بینی صحیح به تمام رکوردها را محاسبه می کند.
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 1- 𝐶𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑐𝑎𝑡𝑖𝑜𝑛𝐸𝑟𝑟𝑜𝑟
Accuracy = (TP+TN) / (TP+FN+FP+TN)
سوال: در مسئله تشخیص یک بیماری نادر که شانس وقوع آن %2 می باشد، آیا شاخص صحت مدل (Accuracy) متر مناسبی برای ارزیابی مدل می باشد؟
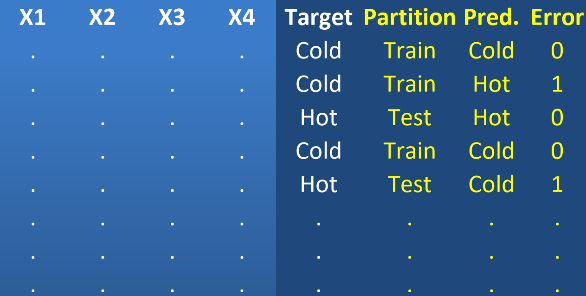
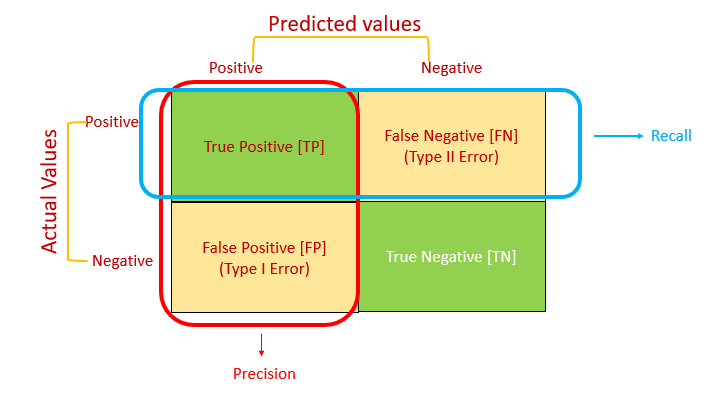
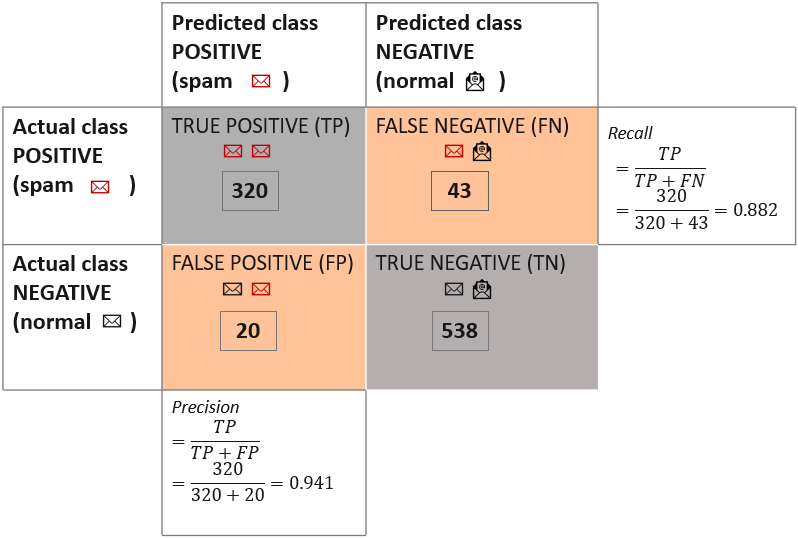
ماتریس در هم ریختگی (Confusion Matrix)
در ماتریس درهم ریختگی مقایسه مقادیر واقعی و مقادیر پیش بینی مدل، به تفکیک هر یک از کلاس های فیلد هدف توزیع می شود.
به ماتریسی گفته میشود که نتیجه ارزیابیِ عملکردِ الگوریتمها در آن نمایش داده میشود. معمولاً چنین نمایشی برای الگوریتمهای یادگیری با ناظر استفاده میشود، اگرچه در یادگیری بدون ناظر نیز کاربرد دارد. معمولاً به کاربرد این ماتریس در الگوریتم های بدون ناظر ماتریس تطابق می گویند.
هر ستون از ماتریس، نمونهای از مقدار پیشبینی شده را نشان میدهد. در صورتی که هر سطر نمونهای واقعی (درست) را در بر دارد. اسم این ماتریس نیز از آنجا بدست میآید که امکان اشتباه و تداخل بین نتایج را آسان تر قابل مشاهده می کند.
در حوزه الگوریتم های هوش مصنوعی، ماتریس در هم ریختگی به ماتریسی گفته میشود که در آن عملکرد الگوریتمها را نمایش میدهند. معمولاً چنین نمایشی برای الگوریتمهای یادگیری با ناظر استفاده میشود، اگرچه در یادگیری بدون ناظر نیز کاربرد دارد. همان طور که ذکر شد معمولاً به کاربرد این ماتریس در الگوریتمهای بدون ناظر ماتریس تطابق میگویند.
هر ستون از ماتریس، نمونهای از مقدار پیشبینیشده را نشان میدهد. درصورتیکه هر سطر نمونهای واقعی (درست) را در بر دارد. در خارج از دنیای هوش مصنوعی این ماتریس معمولاً ماتریس پیشایندی (contingency matrix) یا ماتریس خطا (error matrix) نامیده میشود.
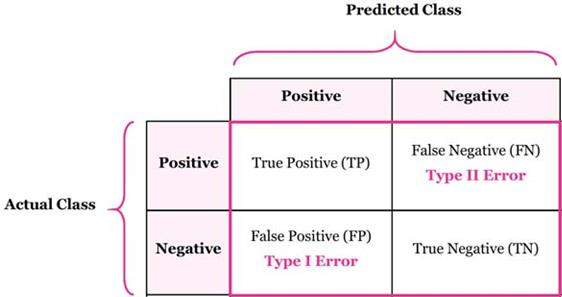
TP: مجموعه رکوردهایی که توسط مدل به درستی، کلاس مثبت پیش بینی شد.
TN: مجموعه رکوردهایی که توسط مدل به درستی، کلاس منفی پیش بینی شد.
FP: مجموعه رکوردهایی که توسط مدل به اشتباه، کلاس مثبت پیش بینی شد.
FN: مجموعه رکوردهایی که توسط مدل به اشتباه، کلاس منفی پیش بینی شد.
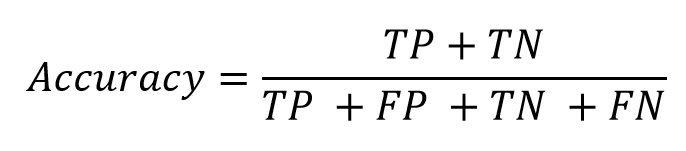
شاخص Recall:
در نقطه مقابل این پارامتر، ممکن است در مواقعی دقت تشخیص کلاس منفی حائز اهمیت باشد. از متداولترین پارامترها که معمولا در کنار حساسیت بررسی میشود، پارامتر خاصیت (Specificity)، است که به آن «نرخ پاسخهای منفی درست» (True Negative Rate) نیز میگویند. خاصیت به معنی نسبتی از موارد منفی است که آزمایش آنها را به درستی به عنوان نمونه منفی تشخیص داده است. این پارامتر به صورت زیر محاسبه میشود.
زمانی که ارزش false negatives بالا باشد، معیار Recall، معیار مناسبی خواهد بود. فرض کنیم مدلی برای تشخیص بیماری کشنده ابولا داشته باشیم. اگر این مدل Recall پایینی داشته باشد چه اتفاقی خواهد افتاد؟ این مدل افراد زیادی که آلوده به این بیماری کشنده هستند را سالم در نظر میگیرد و این فاجعه است. نسبت مقداری موارد صحیح طبقهبندی شده توسط الگوریتم از یک کلاس به تعداد موارد حاضر در کلاس مذکور که بهصورت زیر محاسبه میشود:
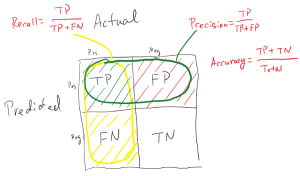
شاخص (Recall) بازیابی یا Sensitivity (حساسیت) نشان دهنده اینست که چه نسبتی از مقادیر واقعی کلاس مثبت به درستی توسط مدل شناسایی و پیش بینی شده است.
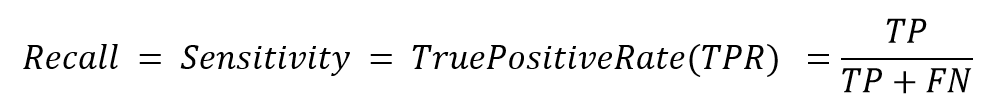
شاخص(Recall) برای کلاس منفی را به عنوان (Specificity) ویژگی می شناسند.
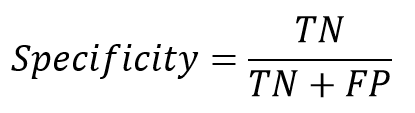
نرخ مثبت کاذب، نشان دهنده اینست که چه درصدی از کلاس های منفی به اشتباه کلاس مثبت در نظر گرفته می شوند. این شاخص به عنوان نرخ هشدار کاذب (False Alarm Rate) نیز شناخته می شود.
برای انتخاب مدل کدام یک از شاخص های Recall یا Precision اهمیت دارد؟
پاسخ به این سوال وابسته به اهمیت هریک از خطاهای نوع اول یا دوم می باشد.
 مثال1: فرض کنید کلاس مثبت تشخیص یک غده سرطانی بدخیم است؛ در این صورت انتظار داریم مقدار FN برابر با صفر باشد (یعنی مقدار Recall برابر با 100): بنابراین مدلی را انتخاب می کنیم که با دارا بودن این شرط، مقدار Precision را ماکزیمم کند.
مثال1: فرض کنید کلاس مثبت تشخیص یک غده سرطانی بدخیم است؛ در این صورت انتظار داریم مقدار FN برابر با صفر باشد (یعنی مقدار Recall برابر با 100): بنابراین مدلی را انتخاب می کنیم که با دارا بودن این شرط، مقدار Precision را ماکزیمم کند.
مثال2: فرض کنید کلاس مثبت وقوع زلزله شدید باشد؛ در اینصورت ترجیح می دهیم برای جلوگیری از وقوع آلارم های اشتباه، مقدار FP از یک مقدار تعیین شده بیشتر نباشد. (بطور مثال حداقل Precision % 90 ) و مدلی را انتخاب می کنیم که بادارا بودن این شرط مقدار Recall را ماکزیمم کند.
معیارهای ارزیابی F1 Score یا F-measure
معیار F1، یک معیار مناسب برای ارزیابی دقت یک آزمایش است. این معیار Precision و Recall را با هم در نظر میگیرد. معیار F1 در بهترین حالت، یک و در بدترین حالت صفر است.
در مواردی که چندین مدل ساخته شده، شرایط حداقلی میزان Recall و Precision را دارا می باشند، می توان از شاخص هیبریدی که براساس دو شاخص فوق بدست می آید، به عنوان معیار ارزیابی استفاده نمود.

معیارهای ارزیابی MCC
پارامتر دیگری است که برای ارزیابی کارایی الگوریتمهای یادگیری ماشین از آن استفاده میشود. این پارامتر بیانگر کیفیت کلاسبندی برای یک مجموعه باینری میباشدMCC -Matthews correlation coefficient، سنجهای است که بیانگر بستگی مابین مقادیر مشاهده شده از کلاس باینری و مقادیر پیشبینی شده از آن میباشد.
مقادیر مورد انتظار برای این کمیت در بازه 1- و 1 متغیر میباشد. مقدار 1+، نشان دهنده پیشبینی دقیق و بدون خطای الگوریتم یادگیر از کلاس باینری میباشد. مقدار 0، نشان دهنده پیشبینی تصادفی الگوریتم یادگیر از کلاس باینری میباشد.
مقدار 1-، نشان دهنده عدم تطابق کامل مابین موارد پیشبینی شده از کلاس باینری و موارد مشاهده شده از آن میباشد. مقدار این پارامتر را بهطور صریح، با توجه به مقادیر ماتریس آشفتگی به شرح زیر، میتوان محاسبه نمود:
![]()