استخراج ویژگی (Feature extraction) فرایندی است که در آن با انجام عملیاتی بر روی دادهها، ویژگیهای بارز و تعیینکننده آن داده ها استخراج میشود. هدف استخراج ویژگی این است که دادههای خام به شکل قابل استفادهتری برای پردازشهای آماری بعدی درآیند.
در تکنیک های استخراج ویژگی، با ایجاد ترکیب های خطی از ویژگی های اولیه، فضای n بعدی داده ها به فضای کوچکتری نگاشت داده میشود، بطوریکه ویژگی های ساخته شده جدید نماینده خوبی از داده های اولیه باشد.

به علت تغییر در ماهیت و مقادیر ویژگی های اولیه، اغلب در مسائلی همچون پردازش تصویر، سیگنال و یا مسائلی که به تفسیر پذیری نتایج نیازی ندارند استفاده میشود.
نرمال سازی داده ها (Normalization) – هم مقیاس سازی
تحلیل مؤلفههای اصلی (Principal Component Analysis – PCA) :
تبدیلی در فضای برداری است، که بیشتر برای کاهش ابعاد مجموعهٔ دادهها مورد استفاده قرار میگیرد.
تحلیل مؤلفههای اصلی در سال ۱۹۰۱ توسط کارل پیرسون ارائه شد. این تحلیل شامل تجزیه مقدارهای ویژه ماتریس کواریانس میباشد.

تحلیل مؤلفه های اصلی در تعریف ریاضی یک تبدیل خطی متعامد است که داده را به دستگاه مختصات جدید می برد به طوری که بزرگترین واریانس داده بر روی اولین محور مختصات، دومین بزرگترین واریانس بر روی دومین محور مختصات قرار می گیرد و همین طور برای بقیه.
فرض کنید یک فروشگاه میخواهد ببیند که رفتار مشتریانش در خریدِ یک محصول خاص (مثلا یک کفش خاص) چطور بوده است. این فروشگاه، اطلاعات زیادی از هر فرد دارد (همان ویژگیهای آن فرد). برای مثال این فروشگاه، از هر مشتری ویژگیهای زیر را جمعآوری کرده است:
سن، قد، جنسیت، محل تولد شخص (غرب ایران، شمال ایران، شرق ایران یا جنوب ایران)، میانگین تعداد افراد خانواده، میانگین درآمد، اتومبیل شخصی دارد یا خیر و در نهایت اینکه این شخص بعد از بازدید کفش خریده است یا خیر. ۷ویژگیِ اول ابعاد مسئله ما را میساختند و ویژگیِ آخر هدف (Target) میباشد (در این باره در درس طبقهبندی صحبت کردهایم)
اگر درس ویژگی چیست را خوانده باشید میدانید که ویژگیهای بالا را میتوان برای مجموعهی داده (در اینجا مجموعه مشتریان فروشگاه) در ۷بُعد رسم کرد. حال به PCA بازمیگردیم. PCA میتواند آن مولفههایی را انتخاب کند که نقش مهمتری در خرید دارند.
برای مثال، مدیرِ فروش به ما گفته است که به جای اینکه هر ۷بُعد را در تصمیمگیری دخالت دهیم، نیاز به ۳بُعد (۳ویژگی) داریم تا بتوانیم آنها را بر روی یک رابطِ گرافیکی ۳بُعدی به نمایش در بیاوریم.
پس در واقع نیاز داریم ۷بُعد را به ۳بُعد کاهش دهیم. به این کار در اصطلاح کاهش ابعاد یا Dimensionality Reduction میگویند. PCA میتواند این کار را برای ما انجام دهد. PCA با توجه دادهها و دامنهی تغییراتِ هر کدام از آنها، میتواند ویژگیهایی را انتخاب کند که تاثیر حداکثری در نتیجه نهایی داشته باشند.
در مثال بالا (فروشگاه)، فرض کنید ویژگی قد، تاثیر زیادی در اینکه یک فرد از فروشگاه خرید کند نداشته باشد. PCA این قضیه را متوجه میشود و در الگوریتمِ خود ویژگیِ قد را تا جای ممکن حذف میکند.
در واقع در فرآیند تبدیلِ ۷ویژگی به ۳ویژگیِ نهایی (که با توجه به درخواست مدیرِ فروش به دنبال آن هستیم) PCA ویژگیِ قد را کمتر دخالت میدهد. اینگونه است که ویژگیهای مهمتر از نظر PCA وزن بیشتری در تولیدِ ویژگیهای کاهش یافته پیدا میکنند.
البته این بدان معنا نیست که در فرآیند کاهش ابعاد، PCA دقیقا همان ویژگی را حذف میکند. بلکه PCA توان این را دارد که به یک سری ویژگی جدید برسد. مثلا این الگوریتم ممکن است به این نتیجه برسد که افرادی که در شمال و غرب ایران زندگی میکنند و سنِ آنها بالای ۴۰سال است، احتمال خرید بالایی دارند در حالی که برعکس این قضیه احتمال خرید را بسیار کمتر میکند.
در واقع اینجا PCA به یک ویژگی ترکیبی از محل تولد شخص و سن رسیده است. این دقیقا یکی از قدرتهای الگوریتم PCA در کار بر روی دادهها است.
حال بگذارید کمی ریاضیتر به قضیه نگاه کنیم. برای سادگی فرض کنید دادههای مشتریان ما کلا ۲بُعد دارند. سن و قد. حال (همانطور که در درس ویژگی چیست خواندید) آنها را بر روی محور مختصات نمایش میدهیم. فرض کنید شکلی مانند شکل زیر تشکیل میشود:

هر کدام از نقاط آبی رنگ، در مثال ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. همانطور که از درس بردار ویژه (Eigen Vector) به یاد دارید، بردار ویژه میتواند کمک کند تا در میان دادههای ما خطی کشیده شود که بیشترین دامنه تغییرات در امتداد آن خط رخ داده باشد. حال به تصویر زیر نگاه کنید:

همانطور که گفتیم هر کدام از نقاط آبی رنگ، در مثالِ ما یک مشتری است که با توجه به ویژگی سن (محور افقی) و ویژگی قد (محور عمودی) در صفحه مختصات رسم شده است. فاصله هر نقطه آبی تا خط قرمز را میتوان به عنوان یک خطا (Error) در نظر گرفت و به تبعِ آن مجموعِ خطا برابر است با جمع فاصله تک تکِ نقاط آبی تا خط قرمز. به شکل زیر نگاه کنید، کدام تصویر (الف، ب یا ج) مجموع خطاهای کمتری دارند؟

کمی دقت کنید. فاصله نقاط نسبت به خط قرمز با خط با رنگ سبز مشخص شدهاند. اگر جمع این فاصله (خطا – Error) را برای هر نمودار برابر خطای کلی دادهها نسبت به خط قرمز در نظر بگیریم، تصویرِ الف بیشترین میزان خطا را دارد و بعد از آن تصویر ب و در نهایت تصویر ج کمترین خطا را دارد.
PCA به دنبال ساختنِ خطی مانند خط ج است (که در واقع همان بردار ویژه ماست) که کمترین خطا (Least Error) را داشته باشد. با اینکار هر کدام از نقاط بر روی خط قرمز نگاشت میشوند و در تصویرِ بالا که ۲بُعدی است میتوان این ۲بُعد را به ۱بُعد (که همان خط قرمز رنگ است) نگاشت کرد. در نهایت میتواند چیزی مانند شکل زیر رخ دهد:

در این مثال آخر ما ۲بُعد را به ۱بُعد کاهش دادیم. البته در مثالهای واقعی ممکن است ۱۰۰۰بُعد را به ۲بُعد کاهش دهند تا بتوان آن را بر روی یک نمودار به نمایش درآورد و این کار با با PCA انجام دهند که هم از سرعتِ معقولی برخوردار است و هم کیفیت قابل قبولی دارد.
مراحل محاسبه مولفه های اصلی
نرمال سازی داده ها ( Z-Score)
 محاسبه ماتریس کوواریانس A
محاسبه ماتریس کوواریانس A

محاسبه مقادیر ویژه (𝜆) ماتریس کوواریانس
مروری سریع بر مفاهیم جبر خطی مورد نیاز:

و حالا بریم سراغ محاسبه مقدار ویژه

مرتب سازی بزرگ به کوچک مقادیر ویژه و انتخاب مقادیر ویژه منتخب

محاسبه بردارهای ویژه (𝑣) متناظر با مقادیر ویژه منتخب (𝜆𝑣 = 𝐴𝑣)

محاسبه مقادیر بردار مولفه اصلی با رابطه (Transpose of Eigen vector) X (Feature vector)

فرضیات تحلیل مولفه های اصلی

- این روش ذاتا برای داده های کمی قابل استفاده است
- بین داده های ورودی همبستگی خطی وجود دارد
خصوصیات تحلیل مولفه های اصلی
بردارهای ویژه جهت محورهای جدید را با طول ثابت یک تعیین میکنند.
مقادیر ویژه اندازه و بزرگی واریانس داده ها رو در جهت تعیین شده مشخص میکند.
- مولفه های ایجاد شده با هدف حفظ بیشترین اطلاعات و پوشش حداکثر واریانس ایجاد می شود.
- مولفه های ایجاد شده متعامد و ناهمبسته هستند. (استقلال مولفه ها تضمین نمیشود)
محدودیت های روش PCA

چه زمانی باید از PCA استفاده کنیم؟
- آیا می خواهید تعداد متغیر ها را کاهش دهید، اما قادر به شناسایی متغیر ها برای حذف کامل از معادلات نیستید؟
- آیا می خواهید مطمئن شوید که متغیر ها مستقل از یکدیگر هستند؟
- آیا مایل هستید که متغیر های مستقل خود را کم تر تفسیر پذیر کنید؟
اگر پاسخ شما به هر سه سوال مثبت است،PCA روش خوبی برای استفاده است. اگر به سوال ۳ ”نه” پاسخ دهید، نباید از PCA استفاده کنید.

چرخش تحلیل مولفه های اصلی (Rotated PCA)
با چرخش محورهای مختصات می توان وزن ویژگی ها در ترکیب خطی مولفه ها را تغییر داد و از این طریق تفسیر پذیری بهتری از مولفه های خطی داشت.
انواع چرخش های رایج در PCA
● چرخش Varimax
واریانس بین مقادیر وزن ویژگی ها را بیشینه میکند و در نتیجه یک مولفه با تعداد کمی از ویژگی های مهم توضیح داده می شود.
● چرخش Quartimax
بر عکس روش قبلی، تعداد فاکتورهای لازم برای توضیح هر ویژگی را کم می کند.

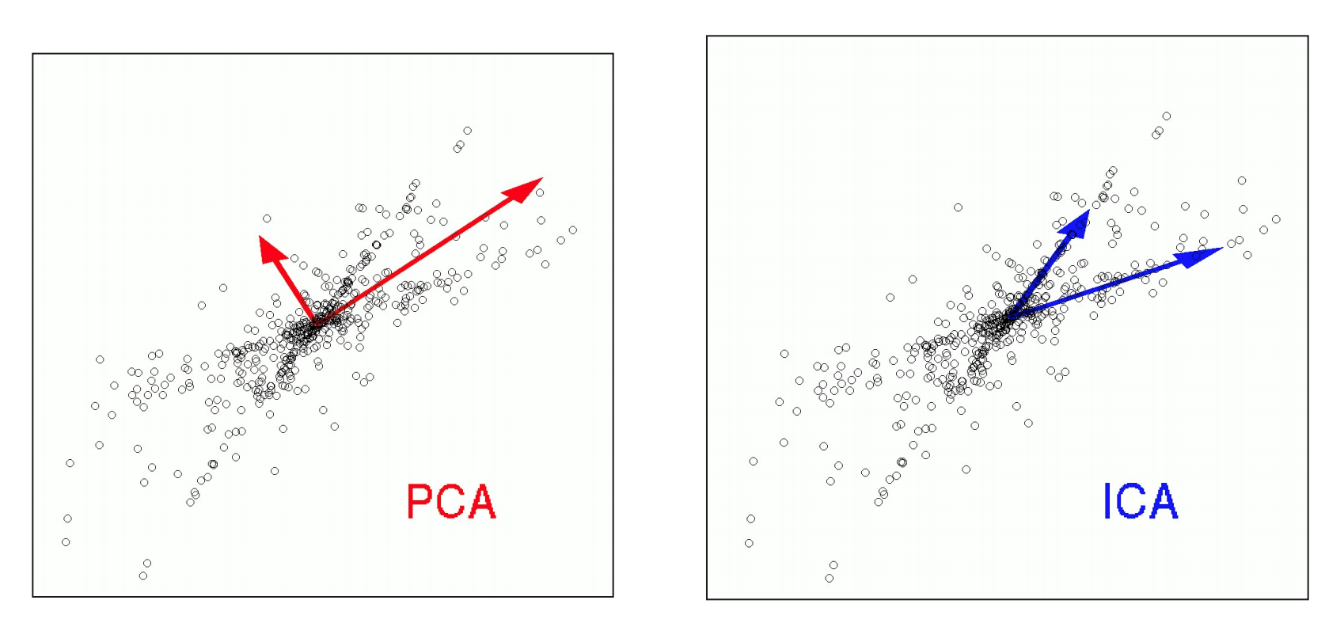
تحلیل مولفه های مستقل (Independent Component Analysis)
تحلیل مؤلفه های مستقل در تعریف ریاضی یک تبدیل خطی غیر متعامد است که داده را به دستگاه مختصات جدید می برد به طوری که ترکیب های خطی ایجاد شده، مستقل از هم باشند.
در بسیاری از مسائل مانند تشخیص نویز در سیگنال های صوتی و یا تفکیک صداهای مختلف در فایلهای صوتی و … که جداسازی منابع و سورس های مستقل اهمیت بالایی دارد، استفاده از روش ICA برای استخراج ویژگی مناسب هست.
تحلیل مولفه های اصلی غیرخطی (Kernel PCA)
در صورتی که ارتباط بین ویژگی ها غیرخطی باشد، با نقض فرض مهم خطی بودن ویژگی ها، عملکرد PCA دچار اختلال خواهد شد و امکان بیشینه کردن مقدار واریانس در ابعاد کوچکتر از بین میرود.
راهکار: استفاده از توابع تبدیل کرنل جهت نگاشت داده های غیرخطی به فضای متفاوت به منظور برقراری ارتباط خطی در فضای جدید

تحلیل مولفه های اصلی غیرخطی (Kernel PCA)
مشکل دیگری که در روابط غیر خطی فضای داده های اصلی امکان وقوع دارد این است که، به علت ماهیت غیر نظارتی روش PCA و عدم اطلاع از وضعیت برچسب های فیلد هدف، در نگاشت داده ها به ابعاد جدید، منجر به همسان سازی داده های با کلاسهای متفاوت شده و در نتیجه باعث کاهش عملکرد مدل های رده بندی شود.
راهکار: استفاده از توابع تبدیل کرنل جهت نگاشت داده های غیرخطی به فضای متفاوت به منظور برقراری ارتباط خطی در فضای جدید

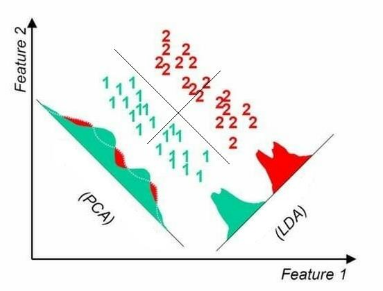
تحلیل ممیزی خطی (Linear Discriminative Analysis)
روش LDA از نوع یادگیری با نظارت بوده و بر خلاف روش PCA این روش کاهش بعد را در جهتی انجام می دهد که نگاشت داده ها روی آنها بیشترین تفکیک پذیری بین کلاسهای هدف ایجاد نماید. از این روش به نام آنالیز خطی فیشر نیز نام برده می شود.
در صورتی که رابطه غیرخطی بین ویژگی ها برقرار باشد راهکار این است که از توابع تبدیل کرنل جهت نگاشت داده های غیرخطی به فضای متفاوت به منظور برقراری ارتباط خطی در فضای جدید استفاده شود.
آنالیز تشخیصی خطی یا تحلیل خطی فیشر روشهای آماری هستند که در یادگیری ماشین و بازشناخت الگو برای پیدا کردن ترکیب خطی خصوصیاتی که به بهترین صورت دو یا چند کلاس از اشیا را از هم جدا میکند، استفاده میشوند.
آنالیز تشخیصی خطی بسیار به تحلیل واریانس و تحلیل رگرسیونی نزدیک است؛ در هر سه این روشهای آماری متغیر وابسته به صورت یک ترکیب خطی از متغیرهای دیگر مدلسازی میشود. با این حال دو روش آخر متغیر وابسته را از نوع فاصلهای در نظر میگیرند در حالی که آنالیز افتراقی خطی برای متغیرهای وابسته اسمی یا رتبهای به کار میرود. از این رو آنالیز افتراقی خطی به رگرسیون لجستیک شباهت بیشتری دارد.
آنالیز تشخیصی خطی همچنین با تحلیل مؤلفههای اصلی و تحلیل عاملی هم شباهت دارد؛ هر دوی این روشهای آماری برای ترکیب خطی متغیرها به شکلی که داده را به بهترین نحو توضیح بدهد به کار میروند یک کاربرد عمده هر دوی این روشها، کاستن تعداد بعدهای داده است.
با این حال این روشها تفاوت عمدهای با هم دارند: در آنالیز افتراقی خطی، تفاوت کلاسها مدلسازی میشود در حالی که در تحلیل مؤلفههای اصلی تفاوت کلاسها نادیده گرفته میشود.
LDA ارتباط نزدیکی با تحلیل واریانس و تحلیل رگرسیون دارد که سعی دارند یک متغیر مستقل را به عنوان ترکیبی خطی از ویژگیهای دیگر بیان کنند. این متغیر مستقل در LDA به شکل برچسب یک کلاس است. همچنین LDA ارتباطی تناتنگ با تحلیل مؤلفههای اصلی PCA دارد.
چرا که هر دو متد به دنبال ترکیبی خطی از متغیرهایی هستند که به بهترین نحو دادهها را توصیف میکنند. LDA همچنین سعی در مدلسازی تفاوت بین کلاسهای مختلف دادهها دارد. از LDA زمانی استفاده میشود که اندازههای مشاهدات، مقادیر پیوسته باشند.