
یکی از مسائل رایج در رده بندی، توزیع داده های نامتوازن در کلاس های فیلد هدف می باشد.
این مساله زمانی رخ میدهد که تعداد مشاهدات مربوط به یک کلاس به طور چشمگیری کمتر از مشاهداتی باشد که به کلاس دیگر تعلق دارند. این مشکل بیشتر در سناریوهایی که کشف ناهنجاری ها در آنها حیاتی است، مثل سرقت الکتریسیته، کشف تقلب در سیستم بانکی، تشخیص بیماریهای نادر و غیره اهمیت زیادی پیدا میکند.
در چنین وضعیتی، مدل پیشگویانه ای که با به کارگیری الگوریتم های یادگیری ماشین ایجاد شده است، جهت دار و یکطرفه شده و دقت آن بسیار پایین خواهد بود.
این اتفاق بدین خاطر میافتد که الگوریتمهای یادگیری ماشین معمولا طوری طراحی شدهاند که با کاهش خطا، دقت مدل را افزایش دهند. بنابراین، این الگوریتم ها توزیع/نسبت یک کلاس نسبت به کل کلاس ها، یا توازن کلاس ها را در محاسبات خود به حساب نمیآورند.
رویکردهای متنوعی برای حل مشکل دادههای نامتوازن وجود دارد که تکنیکهای نمونهبرداری مختلفی را بهکار میگیرند.
بطور کلی شدت نامتوازن بودن داده ها پیچیدگی مسئله را افزایش می دهد و اغلب الگوریتم ها به علت اینکه به دنبال افزایش صحت کلی مدل Accuracy یا کاهش خطا هستند عموما در داده های نامتوازن عملکرد خوبی نخواهند داشت.
به طور مثال فرض کنید برای حل مسئله تشخیص تخلف در یک شرکت بیمه، مجموعه داده ای در اختیار شما گذاشته شده است و پس از یک آماده سازی اولیه بر روی داده، الگوریتم درخت تصمیم را روی داده ها آموزش دادید و از نتیجه مدل شگفت زده شدید:%99.5 صحت مدل در پیشبینی!!
ولی با کمی دقت خواهید دید که مدل شما به همه رکوردها برچسب سالم داده، و %99.5 از داده های شما برچسب سالم داشته اند! در واقع مدلی با ارزش صفر.
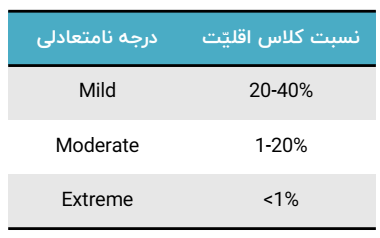
تراکنشهای تقلبی به طور چشمگیری کمتر از تراکنشهای معمولی و سالم هستند و به عبارتی، حدود 1 تا دو درصد از تعداد کل مشاهدات هستند. سوال این است که چگونه میتوانیم تشخیص کلاس اقلیت و نادری را که مانع دستیابی به دقت کلی بالاتر است، بهبود دهیم؟
الگوریتمهای یادگیری ماشین در مواجهه با دیتاست های نامتوازن ، طبقهبندیهای نامناسبی را ایجاد میکنند. در یک دیتاست نامتوازن اگر رویدادی که میخواهیم پیش بینی کنیم به کلاس اقلیت تعلق داشته باشد و نرخ آن رویداد کمتر از 5 درصد باشد، معمولا یک رویداد نادر محسوب میشود.
رویکردهای مختلفی برای مواجهه با داده های نامتوازن وجود دارند که در زیر فهرستی از آنها آورده شده است:
الف) رویکرد در سطح داده: تکنیکهای Resampling
● Random Under Sampling
● Random Over Sampling
● Cluster-Based Over Sampling
● Informed Over Sampling: Synthetic Minority Over Sampling Technique
● Modified synthetic minority oversampling technique (MSMOTE)
ب) تکنیک های الگوریتمی تجمعی (Algorithmic Ensemble Techniques)
● Bagging Based
● Boosting-Based
● Adaptive Boosting- Ada Boost
● Gradient Tree Boosting
● XG Boost
برای فائق آمدن بر چالش داده های نامتوازن، روش های متنوعی وجود دارد که در اجرای پروژه های داده کاوی سعی می شود از ساده ترین روشها برای حل آن استفاده شود و در صورت نیاز به سمت روش های پیچیده تر رفت.
مرحله اول: هیچ کار اضافه ای نکنید!
شاید خوش شانس باشیم و فارغ از شدت نامتوازن بودن داده ها، مدل های بدست آمده از ویژگی های در دسترس، به خوبی کلاس های نامتوازن را تفکیک کنند.
مرحله دوم: ویژگی موثر دیگری به داده ها اضافه کنید!
اگر به اندازه مرحله اول خوش شانس نبودیم، بررسی کنید آیا امکان اضافه کردن ویژگی موثری که تفکیک پذیری کلاس ها را ارتقا دهد وجود دارد.
مرحله سوم: به داده های کلاس حداقلی اضافه کنید!
شاید امکان دسترسی به داده های جدید باکلاس اقلیت وجود داشته باشد. در این صورت بهتر است ادامه حل مسئله پس از تکمیل داده ها و متعادل کردن آنها انجام پذیرد.
مرحله چهارم: رویکرد حل مسئله را می توان تغییر داد
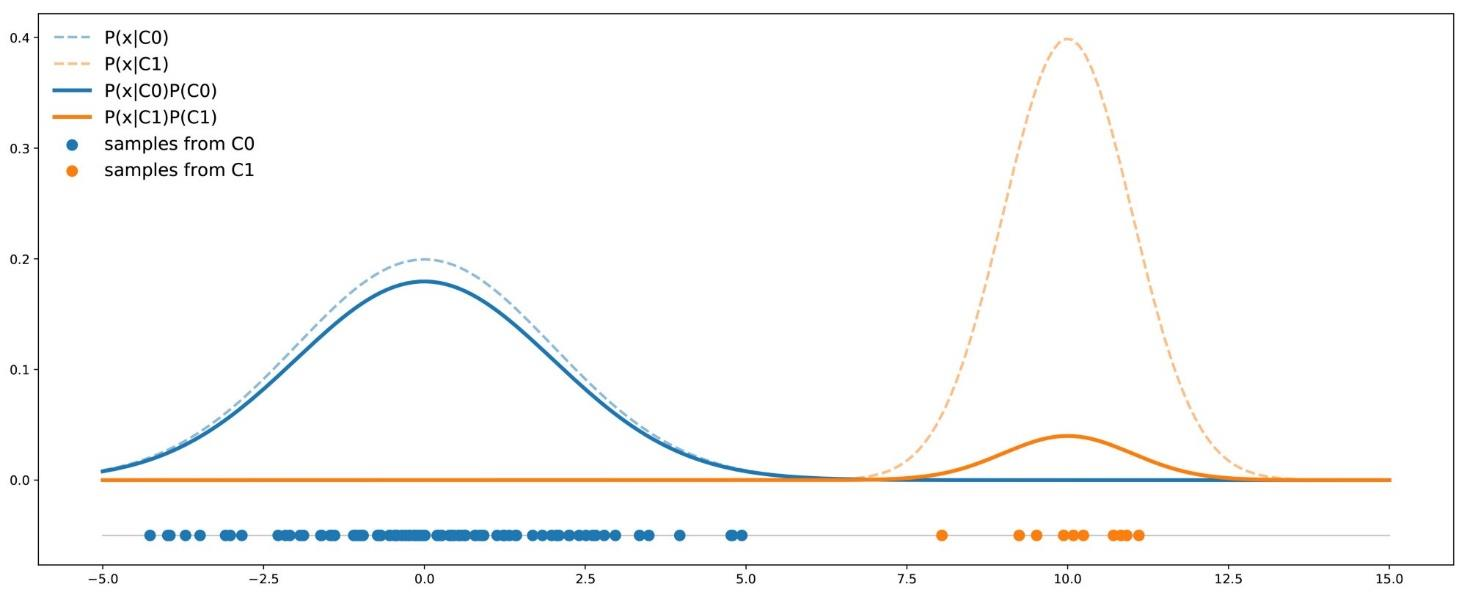
گاهی وقت ها باید واقعیت را پذیرفت و شرایط مسئله را از زاویه دیگری نگاه کرد. به طور مثال، تبدیل مسئله رده بندی به مسئله شناسایی انحرافات (یا Anomaly Detection) می تواند یکی از راهکارهای موجود برای مدلسازی و حل مسئله در نظر گرفته شود.
مرحله پنجم: استفاده از رویکردهای مواجهه با داده های نامتوازن
پس از بررسی چهار مرحله قبل و در صورت تداوم مشکل، سه رویکرد عمده در حل مسئله رده بندی داده های نامتوازن وجود دارد:

رویکردهای مواجهه با داده های نامتوازن
رویکرد مبتنی بر نمونه گیری
هدف از تکنیک های مورد استفاده در این رویکرد، متعادل سازی توزیع کلاسهای فیلد هدف می باشد.
نکته مهم: تغییر توزیع داده ها فقط و فقط در مجموعه داده های آموزشی برای ساخت مدل انجام می پذیرد.
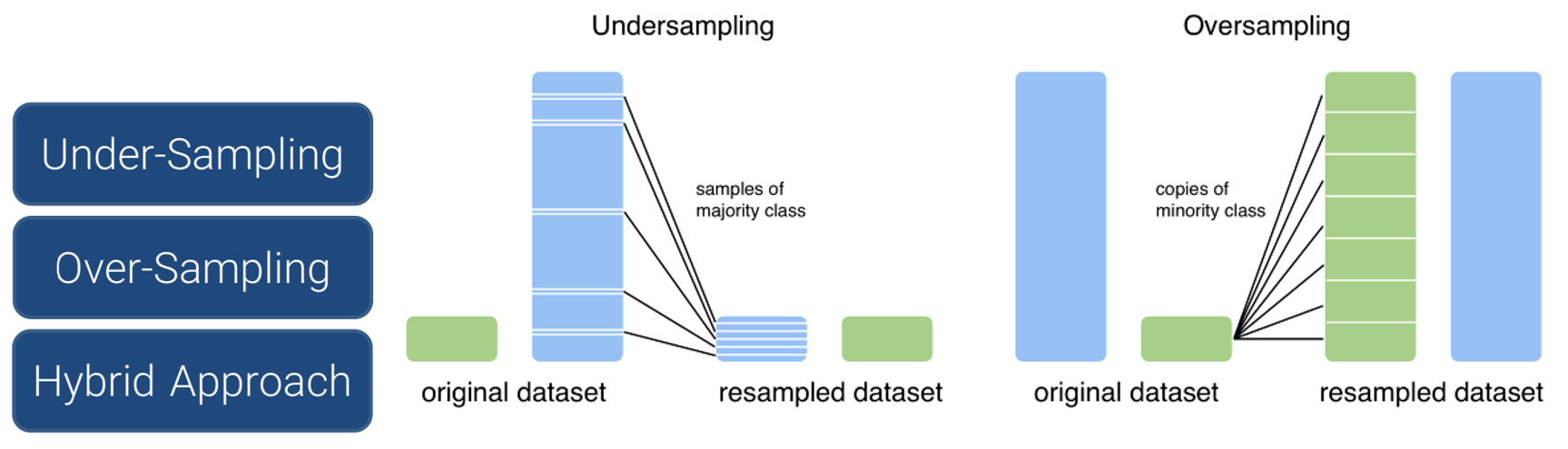
رویکرد مبتنی بر نمونه گیری Under-Sampling
کاهش رکوردهای کلاس اکثریت به روش های مختلفی قابل انجام است. سه روش رایج به شرح زیر است:
- روش حذف تصادفی (Random Under-Sampling)
در این روش، از طریق نمونه گیری تصادفی ساده، تعداد رکوردهای کلاس اکثریت به میزان (یا نزدیک به) تعداد رکوردهای کلاس اقلیت می رسد.
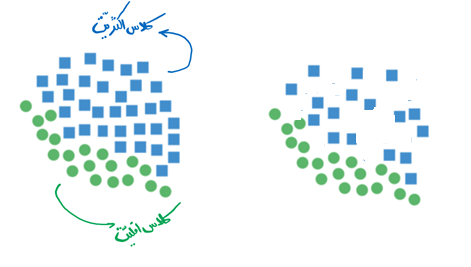
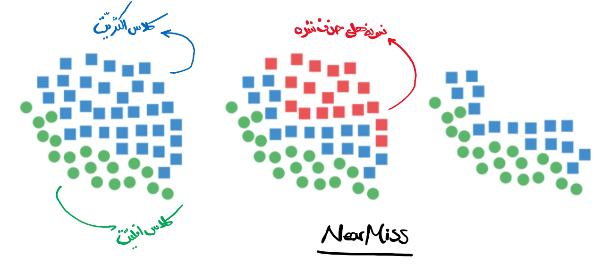
- روش انتخاب نزدیکترین همسایه ها (Near Miss Under-Sampling)
در این روش، به صورت غیر تصادفی و با الگوی زیر رکوردهای کلاس اکثریت کاهش می یابد:
– محاسبه فواصل بین تمام نمونه های کلاس اکثریت و کلاس اقلیت
– شناسایی و نگهداشت k نمونه کلاس اکثریت که کمترین فاصله را با نقاط کلاس اقلیت دارد.
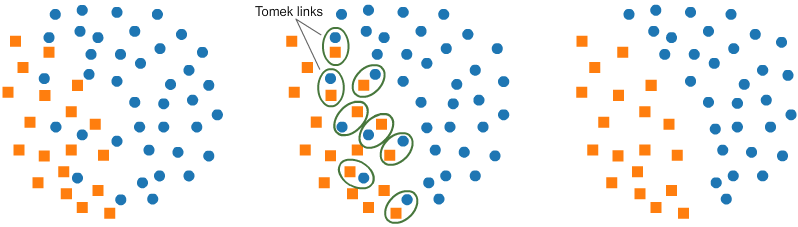
- روش حذف TomeKLinks
در این روش، به صورت غیر تصادفی و با الگوی زیر رکورد های کلاس اکثریت کاهش می یابد:
– شناسایی جفت نمونه هایی در داده ها که هر کدام به کلاس متفاوتی تعلق دارند.
این جفت نمونه ها در اصل در نزدیکی مرز بین دو کلاس قرار دارند)
– حذف نمونه های کلاس اکثریت در این جفت ها علاوه بر متعادل شدن تعداد نمونه ها، مرز بین دو کلاس هم افزایش می یابد.
رویکرد مبتنی بر نمونه گیری Over-Sampling
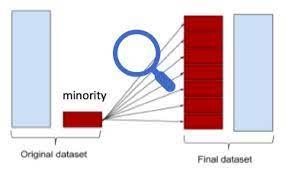
● روش افزایش تصادفی (Random Over-Sampling)
در این روش، از طریق نمونه گیری تصادفی با جایگذاری (بوت استرپ Bootstrap)، با تکرار رکوردهای کلاس اقلیت، تعداد آن ها به میزان (یا نزدیک به) تعداد رکوردهای کلاس اکثریت می رسد.
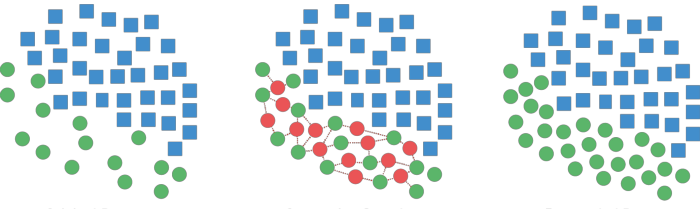
● روش نمونه سازی Synthetic Minority Oversampling Technique (SMOTE)
در این روش، از طریق ساخت نمونه های شبیه به کلاس اقلیت، تعداد آن افزایش می یابد تا توازن کلاس ها برقرار گردد.
- ابتدا -k نزدیک ترین همسایه نمونه های کلاس اقلیت برای هر نمونه از کلاس اقلیت مشخص می شوند.
- برای هر نمونه کلاس اقلیت به صورت تصادفی یکی از همسایه ها انتخاب می شود.
- با استفاده از درون یابی (Interpolation )یک نمونه جدید بین دو نمونه مذکور ایجاد می کنیم.
● روش نمونه سازی ADASYN
در این روش، با استفاده از محاسبه توزیع چگالی داده های اقلیت، عملیات نمونه سازی را برای نمونه هایی از کلاس اقلیت که برای یادگیری مدل سخت تر هستند، انجام می دهد.
محاسبه چگالی:
در همسایگی یک رکورد اقلیت
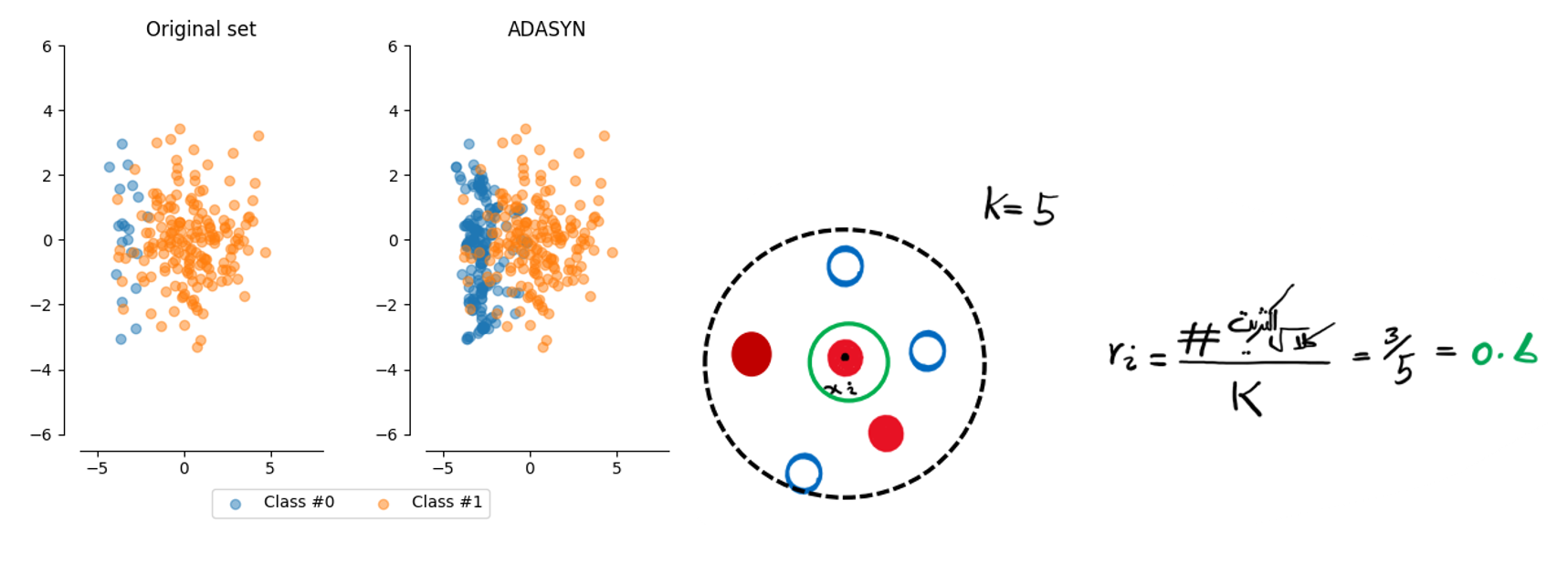
- در این روش -k نزدیکترین همسایه از کل داده ها برای هر نمونه از کلاس اقلیت مشخص می شود.
- سپس برای هر نمونه از کلاس اقلیت چگالی کلاس اکثریت در همسایگی آن (𝑖𝑟) محاسبه می شود.
- تنها روی نمونه های کلاس اقلیتی که یادگیری آن ها برای مدل سخت تر است (نمونه های مرزی)، نمونه جدید ساخته می شود.
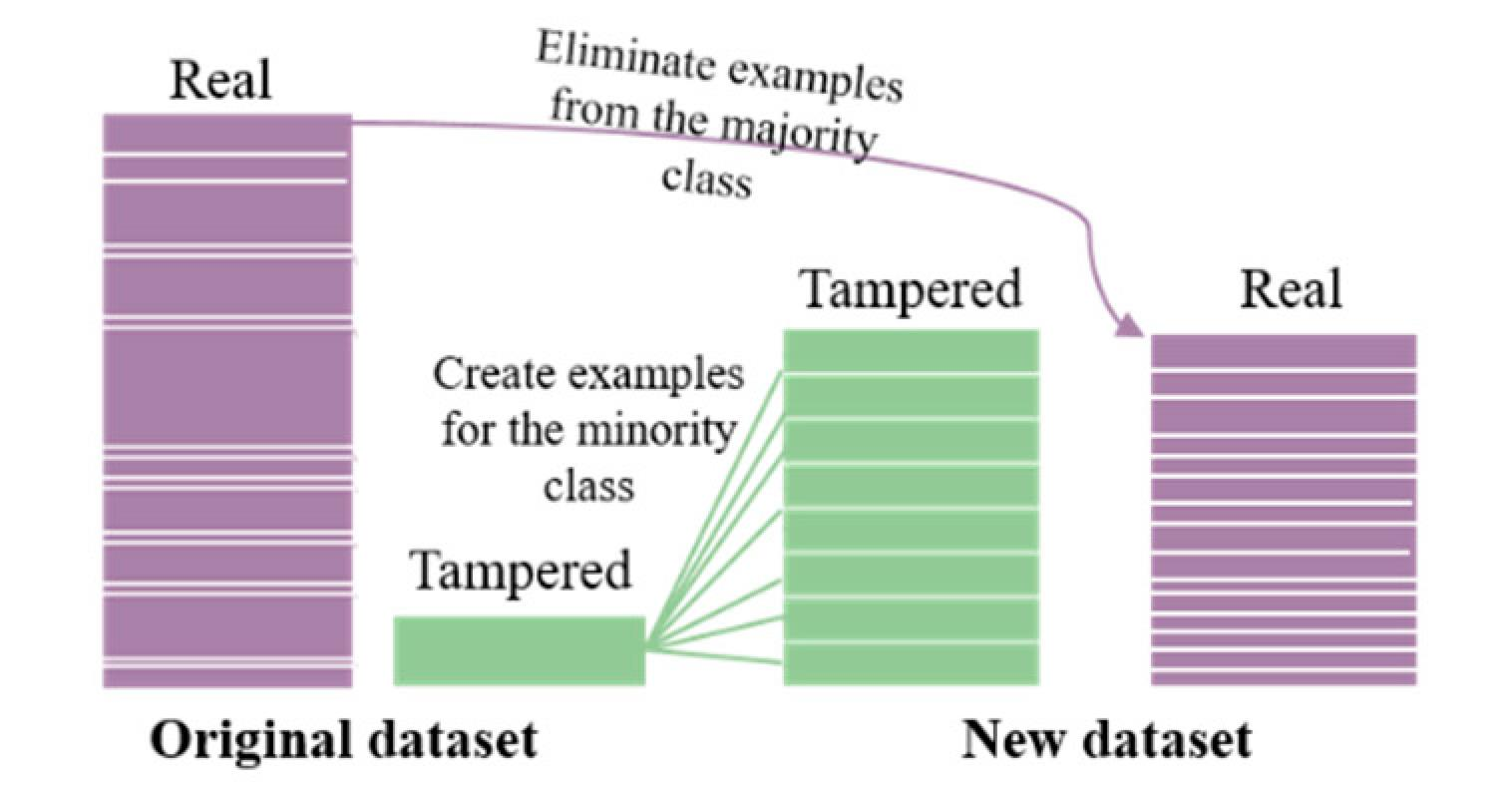
رویکرد مبتنی بر نمونه گیری Hybrid Approach
در بسیاری از مسائلی که شدت نامتوازن بودن داده ها زیاد باشد، استفاده از روش های ترکیبی از رویکردهای کاهش داده های اکثریت و افزایش دادههای اقلیت مورد استفاده قرار میگیرد.
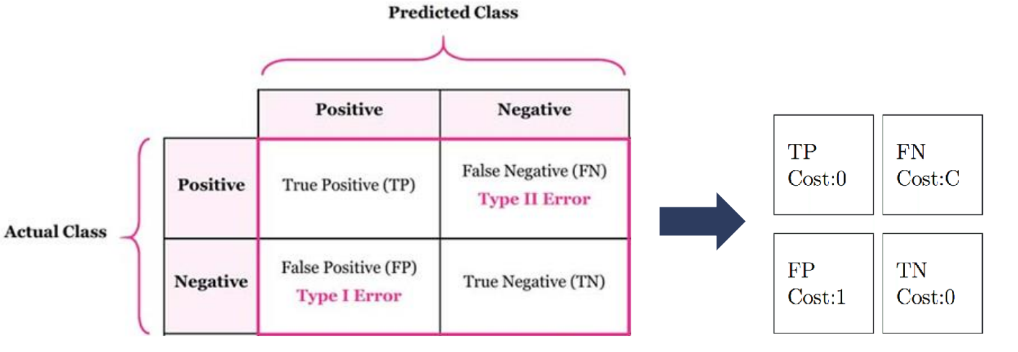
رویکرد مبتنی بر تابع هزینه
در این رویکرد با تغییر تابع هزینه خطاهای پیش بینی، روند یادگیری مدل به سمت پیش بینی کلاس اقلیت سوق داده می شود.
- در اکثر رده بند ها فرض بر این است که هزینه خطای رده بندی برای کلاس های متفاوت یکسان است. (آیا در دنیای واقعی این گونه است؟)
- اصل اولیه در این رویکرد، نابرابری هزینه خطاهای رده بندی است.
- در این روش به جای محاسبه ساده خطا برای هر نمونه، هزینه رده بندی اشتباه برای هر کلاس، متفاوت در نظر گرفته می شود.
- مدل به جای تلاش برای بیشینه سازی صحت Accuracy سعی در کمینه سازی کل هزینه های رده بندی اشتباه را دارد
با تعریف ماتریس هزینه، آموزش مدل براساس یادگیری حساس به هزینه Cost-Sensitive Learning خواهد بود.
انتخاب مقدار پارامتر هزینه:
- بر اساس تحلیل اقتصادی و محاسبه
- هزینه اقتصادی خطا در پیشبینی
- بر اساس نسبت عدم توازن داده ها
- به روش آزمون و خطا
رویکرد مبتنی بر معماری الگوریتم
الگوریتم های مختلف براساس ویژگی های ریاضیاتی، آماری و هندسی خود، می توانند نتایج متفاوتی در برخورد با داده های نامتوازن داشته باشند. بنابراین شناخت لازم و آگاهی از جزئیات الگوریتم ها می تواند در انتخاب الگوریتم های مناسب برای حل یک مسئله تعیین کننده باشد.
بطور مثال الگوریتم هایی مانند درخت تصمیم به علت ماهیت جستجو و افزاری که دارند، عموما در مقابل چالش نامتوازن بودن داده ها مقاومت بیشتری خواهند داشت.
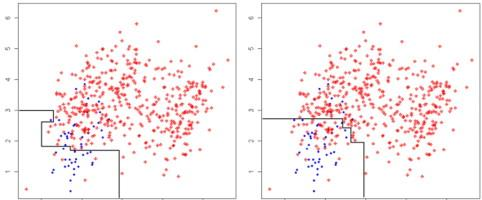
تعیین حد آستانه مدل رده بندی Classification Threshold برای برچسب گذاری کلاس های پیش بینی شده، یکی از روش های مناسب در مواجهه با داده های نامتوازن است.
اغلب الگوریتم ها بطور پیش فرض در مسائل رده بندی (باینری) مقدار 0.5را به عنوان حد آستانه ای در نظر می گیرند. در صورتی که مقدار احتمال کلاس مثبت در مدل برازش داده شده A یعنی (+|A)P بالای این حد باشد، برچسب کلاس مثبت و در غیر اینصورت برچسب کلاس منفی تخصیص داده می شود.
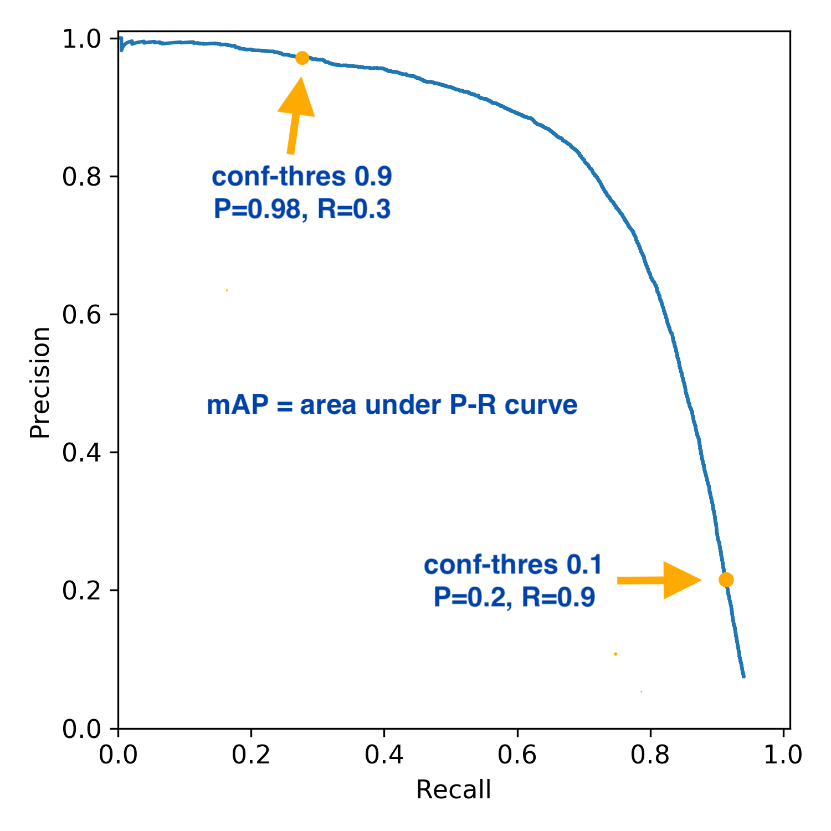
استفاده از نمودار Recall-Precision برای حدود آستانه ای متفاوت، ابزار رایجی در تعیین بهترین حد آستانه ای داده های نامتوازن می باشد.
یکی از روش های مناسب جهت مواجهه با داده های نامتوازن استفاده از قدرت چندین مدل رده بندی به جای استفاده از یک مدل است. در این روش حل مسئله، به جای تمرکز بر ساخت یک مدل بسیار خوب به سمت ساخت یک سیستم خرد جمعی مطمئن میرویم.
این رویکرد تحت عنوان مدل های تجمیعی (Ensemble Models) شناخته می شوند.
