
الگوریتم Apriori با هدف تولید قوانین انجمنی، در دو مرحله شناسایی مجموعه اقلام مکرر و تولید قوانین توسعه یافته است. در گام اول، به منظور شناسایی مجموعه اقلام مکرر، نیازمند دانستن پارامتر حداقل پشتیبانی (min Support) می باشد.
پشتیبانی (Support) : نسبتی از تمامی تراکنش ها که در آنها یک قلم یا ترکیبی از اقلام مورد نظر وجود داشته باشد.
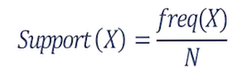
می توان معیار پشتیبانی را به صورت مطلق نیز بیان نمود. در این حالت فقط به تعداد تراکنش های شامل زیر مجموعه X اشاره می شود.
تعیین مقدار حداقل پشتیبانی، بر اساس تجربه افراد خبره و نیاز کسب و کار تعیین می گردد. بدیهی است با انتخاب مقادیر بزرگتر، مجموعه اقلام کمتری دارای شرایط تعریف شده می شوند و فضای جستجوی الگوریتم کوچکتر شده و در زمانی سریعتر به تعداد محدودتری از قوانین انجمنی خواهیم رسید.
اصل کلیدی در الگوریتم Apriori که منجر به کوچک شدن فضای جستجو و سرعت بالای شناسایی مجموعه اقلام مکرر می شود:
“هر زیرمجموعه غیرتهی از مجموعه اقلام مکرر، بایستی شرایط اقلام مکرر را داشته باشد.”
بنابراین الگوریتم Apriori، از بررسی اقلام تکی شروع کرده و با محاسبه پشتیبانی آنها، در لایه بعدی صرفا به بررسی ترکیب دوتایی اقلام مکرر قبلی می پردازد و سپس ترکیب سه تایی و به همین صورت تا جایی که ترکیب اقلام مکرر وجود داشته باشد، ادامه می دهد.
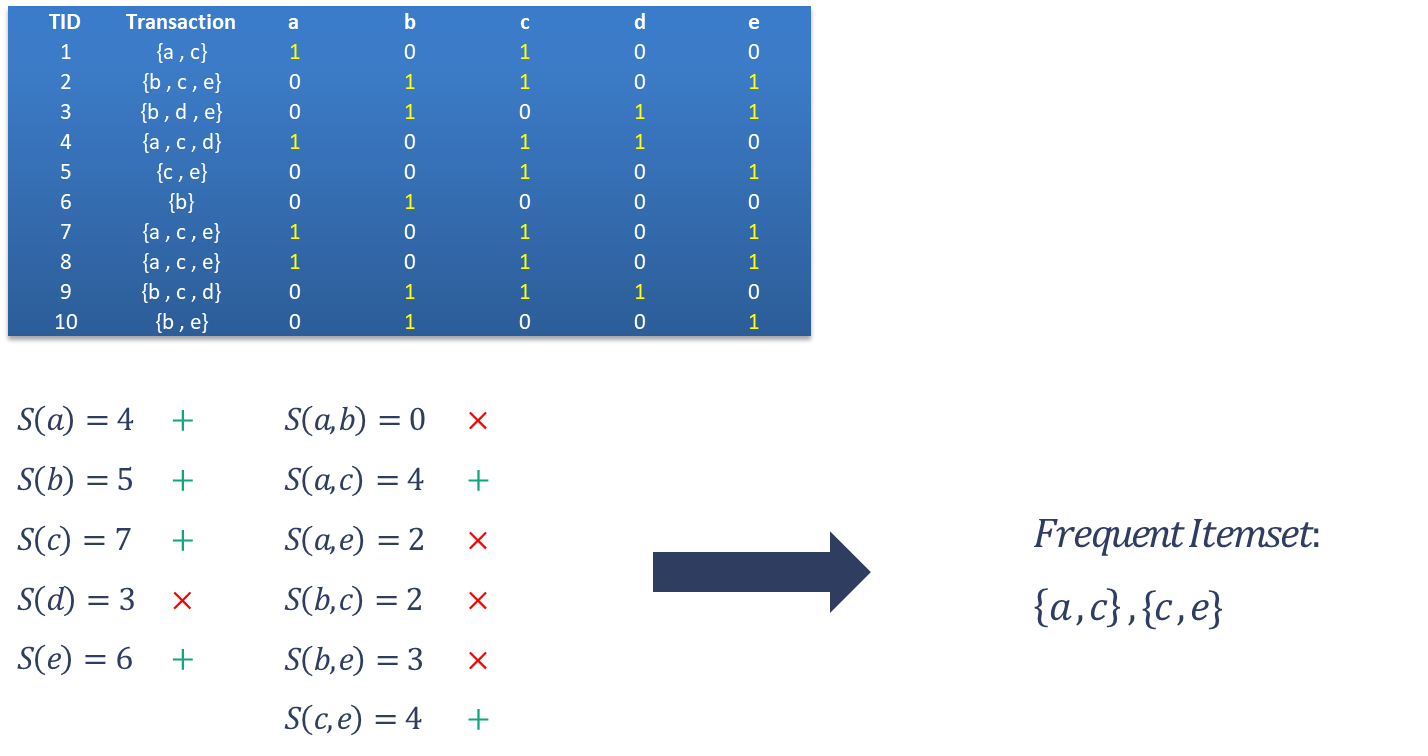
مثال:
در مجموعه داده های روبرو، با در نظر گرفتن حداقل پشتیبانی برابر با مقدار 4، مجموعه اقلام مکرر را بیابید:
در گام دوم پس از شناسایی مجموعه اقلام مکرر، قوانین انجمنی استخراج می گردد. قوانین به دست آمده، نوع وابستگی بین اقلام مکرر را نشان می دهد. قوانین انجمنی به شکل اگر – آنگاه (X —> Y) نشان داده می شود و به این معنی است که اگر X اتفاق بیفتد آنگاه Y نیز اتفاق خواهد افتاد. بدین منظور نیاز به تعیین مقدار پارامتر دوم الگوریتم یعنی حداقل اطمینان (min Confidence) می باشد.
اطمینان (Confidence): نسبتی از تراکنش های قسمت مقدم (X) که دارای اقلام قسمت موخر (Y) می باشد.
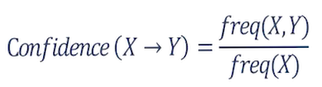
این معیار در واقع میزان اطمینان از درستی قانون را اندازه می گیرد.
تعیین مقدار حداقل اطمینان، بر اساس تجربه افراد خبره و نیاز کسب و کار تعیین می گردد. بدیهی است با انتخاب مقادیر بزرگتر، در زمانی سریعتر مجموعه قوانین کمتری استخراج خواهد شد.
مثال:
در مجموعه داده های روبرو، با در نظر گرفتن حداقل اطمینان برابر با مقدار 0.6 قوانین انجمنی را استخراج نمایید:
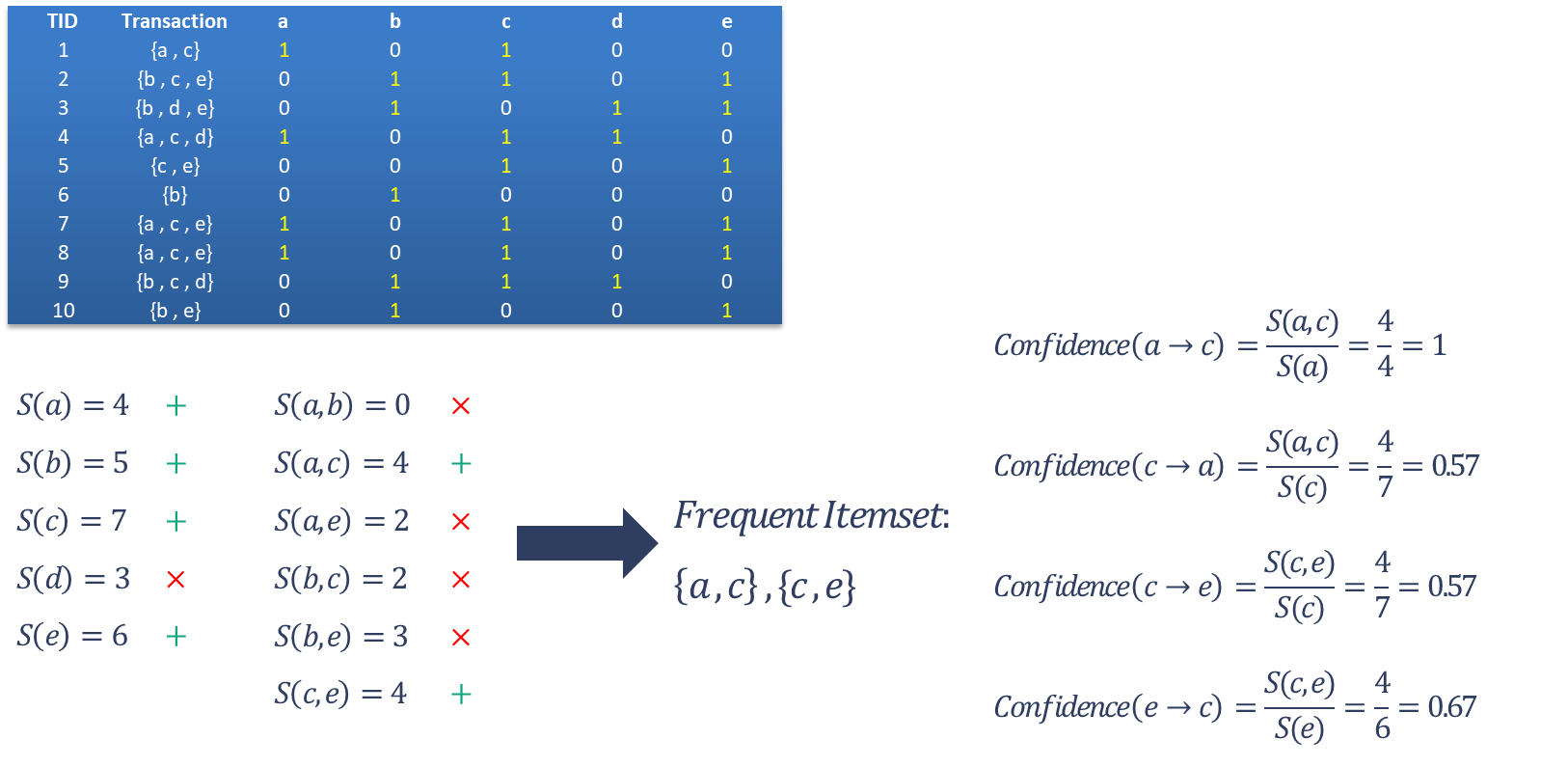
سوال: آیا هر قانون انجمنی قوی، جذابیت نیز دارد؟
استخراج قوانین انجمنی قوی با دارا بودن حداقل پشتیبانی و حداقل اطمینان، همیشه منجر به تولید قوانین جذاب نمی شود. هدف از استخراج قوانین انجمنی، شناسایی روابط تکرارشونده و وابستگی بین اقلام می باشد به طوری که نسبت به دانش اولیه موجود، ارزش افزوده ای ایجاد نماید؛ به این معنی که استفاده از قوانین به دست آمده، منجر به ارتقای شانس وقوع برخی اقلام شود.
ارتقا (Lift): نسبت اطمینان یک قانون انجمنی به احتمال وقوع اولیه.
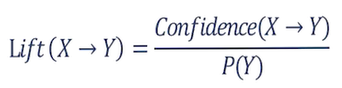
مقدار احتمال Y برابر با میزان پشتیبانی نسبی Y در مجموعه داده های اولیه می باشد.
بدیهی است هر چه مقدار Lift به عدد یک نزدیکتر باشد، نشان دهنده عدم جذابیت قانون است. معمولا به دنبال اعداد بزرگتر از یک هستیم که نشان می دهد شرایط گفته شده در قانون، شانس وقوع آن را ارتقا می دهد. همچنین اعداد کوچکتر از یک به معنی وابستگی منفی می باشد.
مثال:
در مجموعه داده های روبرو، با محاسبه معیار ارتقا، قوانین جذاب را لیست کنید:

رتبه بندی قوانین
در مجموعه داده های بزرگ معمولا تعداد قوانین بسیار زیادی که دارای شرایط حداقلی در معیارهای پشتیبانی، اطمینان و ارتقا می باشند استخراج می گردد. همچنین با رجوع به منابع می توان معیارهای متنوع دیگری همچون کای – دو، کسینوسی، کولژیبنسکی و … را مورد استفاده قرار داد. رتبه بندی قوانین بر اساس هر یک از شاخص ها می تواند منجر به ترتیب های متفاوتی گردد. معمولا استفاده از افراد خبره و بررسی قوانین منتخب بر اساس هر یک از شاخص ها، ایده انتخاب شاخص اصلی در رتبه بندی قوانین مسئله مورد نظر را به وجود می آورد.
بهینه سازی الگوریتم
علی رغم ایده تولید مجموعه اقلام مکرر که در الگوریتم Apriori به کار رفته است، اما هنوز در داده های بسیار بزرگ منجر به فضای جستجوی گسترده و کندی الگوریتم می گردد. بنابراین اغلب توسعه های انجام شده در این حوزه، روی ساختار مشابه الگوریتم Apriori و بهبود سرعت آن بوده است. الگوریتم FP-Growth توانسته به صورت کارآمدی در داده های بسیار بزرگ فرآیند شناسایی اقلام مکرر را بهبود داده و با سرعت بیشتری به خروجی برسد.