
در ابتدای معرفی تکنیک خوشه بندی لازم به ذکر است که مدل های اکتشافی در فرآیند داده کاوی که با عنوان مدل های توصیفی (Descriptive Models) نیز شناخته میشوند، در دسته یادگیری بدون نظارت قرار می گیرد.
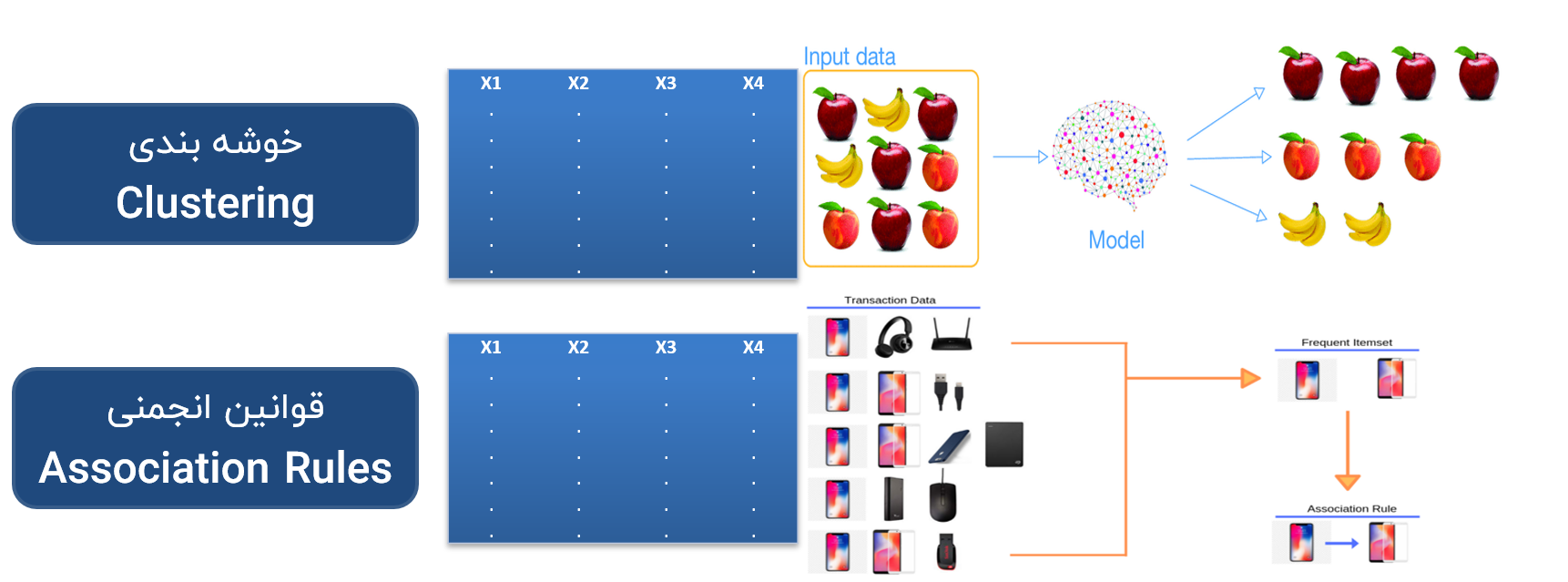
خوشه بندی (Clustering)
هدف از خوشه بندی، دسته بندی داده ها و تقسیم بندی آنها در چندین گروه می باشد به طوری که اعضای داخل هر گروه دارای بیشترین شباهت (کمترین واریانس) به هم باشند و اعضای گروه های متفاوت دارای کمترین شباهت (بیشترین واریانس) باشند.
به هر یک از این گروه ها که زیر مجموعه ای از داده های شبیه به هم می باشند یک خوشه (Cluster) گفته میشود.
مثال:
- خوشه بندی مشتریان بر اساس رفتار خرید آنها (بخش بندی مشتریان)
- خوشه بندی مناطق زلزله خیز بر اساس اطلاعات لرزه های ثبت شده گذشته (تعیین زون های ساختاری زمین شناسی)
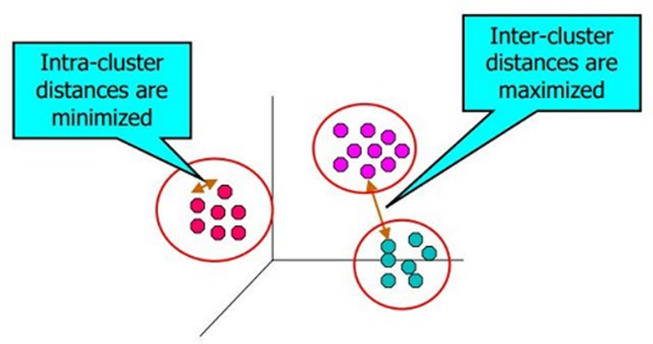
به طور کلی خوشه بندی به دو حالت مختلف می تواند وجود داشته باشد:
خوشه بندی سخت (Hard Clustering)
در این نوع خوشه بندی هر رکورد از داده ها صرفا به یک خوشه تعلق خواهد داشت.
خوشه بندی نرم/فازی(Soft/Fuzzy Clustering)
در این نوع خوشه بندی هر رکورد از داده ها، احتمال تعلق به هر یک از خوشه ها خواهد داشت.
الگوریتم های خوشه بندی نیز به انواع مختلف دسته بندی می شوند که سه رویکرد رایج در خوشه بندی این موارد هستند:
