فرایند داده کاوی با استفاده از متدولوژی CRISP-DM
هدف نهایی از تحلیل داده، شناسایی و کشف الگوهای موجود در داده ها است.
چالش های شناسایی الگوها: انتخاب داده های مناسب، ساخت شاخص های مناسب، انجام تبدیلات مناسب، انتخاب الگوریتم مناسب، انتخاب ارزیابی مناسب، انتخاب الگوی مناسب و…
تعریف داده کاوی: بنا بر تعریف اسامه فیاض در سال 1996 داده کاوی فرآیند کشف دانش از پایگاه های داده به منظور شناسایی الگوهای موجود در داده ها که شرایط زیر را داشته باشند: معتبر باشند، کارا و قابل استفاده باشند، بدیع باشند، توجیه پذیر باشند.
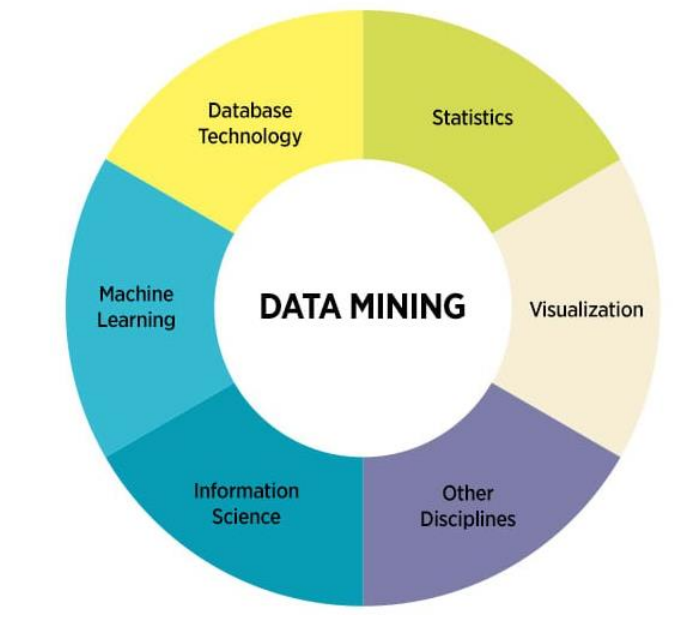
جعبه ابزار داده کاوی: روش های آماری، یادگیری ماشین، پایگاه داده، مصور سازی و … .
متدولوژی CRISP-DM :
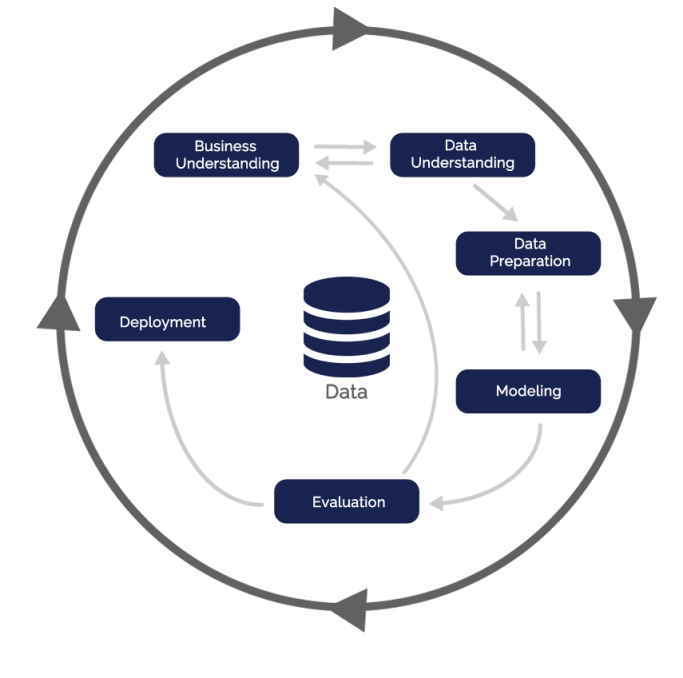
عنوان CRISP-DM برگرفته از حروف اول کلمات cross-industry process for data mining به معنای فرایند میان صنعتی برای داده کاوی است. CRISP-DM یک رویکرد ساختاری برای برنامه ریزی یک پروژه داده کاوی ارائه می دهد. این مدل یک دنباله یا توالی ایده آل از حوادث و رویدادها است. در عمل بسیاری از وظایف را می توان با ترتیب متفاوت انجام داد و اغلب لازم است که به کارهای قبلی برگشت و نگاهی انداخت و اقدامات خاصی را تکرار کرد. این مدل سعی می کند که همه مسیرهای احتمالی را از طریق فرایند داده کاوی به دست آورد.
 فازهای فرآیند داده کاوی:
فازهای فرآیند داده کاوی:
 فازهای فرآیند داده کاوی:
فازهای فرآیند داده کاوی:شناسایی و درک مسئله: در این مرحله، یک متخصص علم داده بایستی کسب و کاری که میخواهد بر روی آن پروژه داده کاوی انجام دهد را به خوبی بشناسد. در مرحلهی فهم کسب و کار، بایستی زوایای مختلف آن کسب و کار، محدودیتها، شرایط موجود و اهداف آن کسب و کار از پروژه یا پروژههای جاری را بررسی نمود.
این مرحله ذهن متخصص علم داده را برای کار بر روی پروژه آماده میکند و به او اجازه میدهد تا با شناخت بیشتر و بهتر به سراغ مراحل بعدی برود. در این مرحله، یک متخصص علم داده میتواند تا حدودی به کسب و کارِ موجود مسلط شده و فهم خود را از آن کسب و کار تا حد ممکن بالا ببرد.
شناسایی و درک داده ها: در مرحلهی فهم دادهها، متخصص علم داده، به سراغ دادههای موجود کسب و کار رفته آن را برای شروع پروژه بررسی میکند. با فهم دادهها و درک ابعاد و ویژگیهای مختلف آن، میتوان ایدههای مختلف را مطرح کرد و ساختار اصلی پروژه را تعیین نمود. در این مرحله میتوان کیفیت دادهها را نیز ارزیابی کرد و در صورت نامناسب بودن دادهها، با مشورت و مشارکت قسمتهای مختلف کسب و کار، این دادهها را بهبود بخشید.
آماده سازی داده ها: بعد از فهم کسب و کار و فهم دادهها، حال میتوان دادهها را آمادهی تحلیل و مدلسازی کرد. در این مرحله، دادههای کثیف، تمیز میشوند و دادهها به صورت ساختاری، برای مرحلهی بعدی آمادهسازی میشوند. در این مرحله همچنین میتوان مجموعه دادههای مختلف را با یکدیگر ترکیب کرد تا به مجموعه دادهی بهتر و با کیفیتتری رسید.
هدف نهایی از تحلیل داده، شناسایی و کشف الگوهای موجود در داده ها است.
مدل سازی: بسته به اینکه مسئلهی شما چه نوع مسئلهایست در این مرحله بایستی از الگوریتمها و روشهای مخصوص به خود استفاده کنید. مثلاً اگر مسئلهی شما طبقه بندی دادههاست، بایستی از الگوریتمهای طبقه بندی برای یادگیری استفاده کنید و یا اگر مسئلهی شما در دستهی خوشه بندی قرار میگیرد، میتوانید یکی از الگوریتمهای خوشه بندی را برای پروژهی خود مورد استفاده قرار دهید.
البته در یک پروژهی داده کاوی، ممکن است مسائل مختلف و ترکیبی وجود داشته باشد که نیاز به عملیات پیچیدهتری جهت مدل سازی دارند.
ارزیابی: این ارزیابی بستگی به مدلِ انتخابی دارد. برای مثال اگر مسئلهی شما طبقه بندی بود، میتوانید از روشهای ارزیابی الگوریتمهای طبقه بندی استفاده کنید. طبیعتاً اگر مدلِ شما به اندازهی کافی کیفیت نداشت، بهتر است به مراحل قبلی بازگرید و مدل یا دادهها یا روشهای آمادهسازی دادههایتان را بهبود بخشیده و مجدداً ارزیابی را انجام دهید.
گسترش و توسعه: در نهایت، بایستی نرم افزاری توسعه دهید تا کاربران بتوانند از زحمات شما استفاده کنند. این مرحله، معمولاً با کمک مهندسین نرم افزار و برنامه نویسان انجام میشود.
همانطور که مشاهده میکنید این فرآیند به صورت چرخشی و تکراری انجام میشود. برای مثال اگر در مرحلهی « شناسایی و درک داده ها» دچار مشکلی شدید به عقب برمیگردید و « شناسایی و درک مساله » میکنید و یا اگر «مدلسازی» خوبی انجام ندادید، به عقب برگشته و در مرحلهی «آمادهسازی دادهها» تجدید نظر میکنید. و یا اگر مدل شما بعد از «ارزیابی»، کیفیت مناسبی نداشت میتوانید به مرحلهی اول برگشته و دوباره از « شناسایی و درک مساله: » شروع کنید.
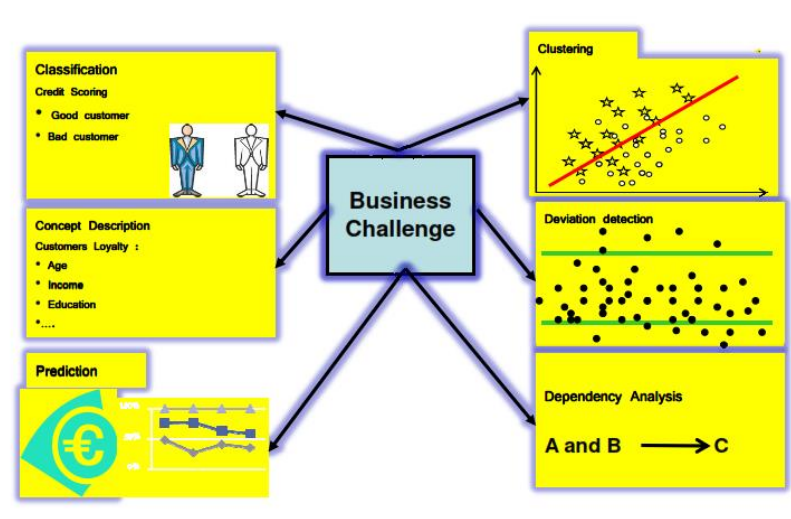
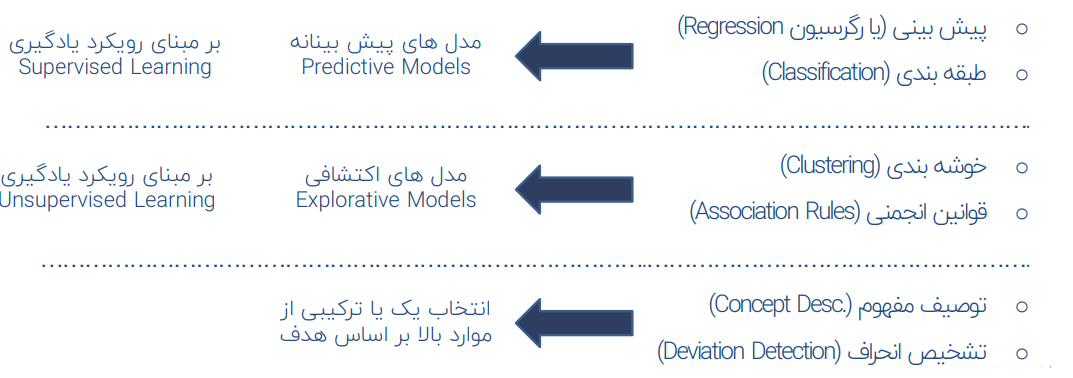
انواع مسائل (وظایف) داده کاوی:
- پیش بینی ( یا رگرسیون Regression)
- طبقه بندی (Classification)
- خوشه بندی (Clustering)
- قوانین انجمنی (Association Rules)
- توصیف مفهوم (Concept Desc.)
- تشخیص انحراف (Deviation Detection)
در ادامه به بررسی هر یک از مباحث به جزء خواهیم پرداخت:
پیش بینی ( یا رگرسیون Regression)
- یادگیری با نظارت است (Supervised Learning)
- پیش بینی مقدار هدف با توزیع آماری پیوسته و نتیجه به صورت یک عدد بیان می شود
اگر بخواهیم واژه رگرسیون(Regression) را از لحاظ لغوی تعریف نماییم، این واژه در فرهنگ لغت به معنی پسروی، برگشت و بازگشت است. اما اگر آن را از دید آمار و ریاضیات تعریف کنیم اغلب جهت رساندن مفهوم “بازگشت به یک مقدار متوسط یا میانگین” به کار میرود. بدین معنی که برخی پدیده ها به مرور زمان از نظر کمی به طرف یک مقدار متوسط میل می کنند.
بیش از 100 سال پیش در سال 1877 فرانسیس گالتون (Francis Galton) در مقاله ای که در همین زمینه منتشر کرد اظهار داشت که متوسط قد پسران دارای پدران قد بلند ، کمتر از قد پدرانشان می باشد. به نحو مشابه متوسط قد پسران دارای پدران کوتاه قد نیز بیشتر از قد پدرانشان گزارش شده است. به این ترتیب گالتون پدیده بازگشت به طرف میانگین را در داده هایش مورد تأکید قرار داد.
برای گالتون رگرسیون مفهومی زیست شناختی داشت اما کارهای او توسط کارل پیرسون (Karl Pearson) برای مفاهیم آماری توسعه داده شده. گرچه گالتون برای تأکید بر پدیده “بازگشت به سمت مقدار متوسط” از تحلیل رگرسیون استفاده کرد، اما به هر حال امروزه واژه تحلیل رگرسیون جهت اشاره به مطالعات مربوط به روابط بین متغیرها به کار برده می شود.
به لحاظ لغوی رگرسیون به معنای بازگشت است. به بیانی دیگر این لغت یعنی پیشبینی و بیان تغییرات یک متغیر بر اساس اطلاعات متغیری دیگر. زمانی که بین دو متغیر همبستگی وجود داشته باشد؛ می توان نمره ی فردی را در یک متغیر از طریق متغیر دیگر برآورد یا پیشبینی کرد. اگر ضریب همبستگی بین متغیرها عددی بین ۱+ تا ۱- باشد و در واقع همبستگی کامل برقرار نباشد پیشبینی ما برآورد خوبی است اما پیشبینی کاملی نیست.
هرچه همبستگی بین متغیرها بالاتر باشد؛ به همان اندازه پیش بینی دقیقتر است. نحوه ی محاسبه ی رگرسیون به این شکل است که اگر متغیری را که قصد پیشبینی آن را داریم Y و متغیری که از طریق آن پیش بینی صورت میگیرد را X بنامیم؛ نمره ی پیش بینی شده برای متغیر Y برابر است با حاصل ضرب نمره ی استاندارد متغیر X در ضریب همبستگی بین دو متغیر.
رابطه بین متغیر پیش بینی شونده y و پیش بینی کننده x تابع علامت و شدت ضریب همبستگی است. رگرسیون به سمت میانگین پدیده ای بود که گالتون مطرح کرد و به معنای میل نمرات به سمت میانگین آنهاست. در ادامه از انواع رگرسیون ها نام می بریم و در نهایت رگرسیون خطی را شرح می دهیم.
مثال: مثلا می خواهیم دمای هوا بر اساس فیلد های ورودی را پیش بینی نماییم:


در این معادله x ها تعداد ورودی ما هستند و دمای هوا (Y) می تواند بر اساس تابع f(x) تعیین شود.
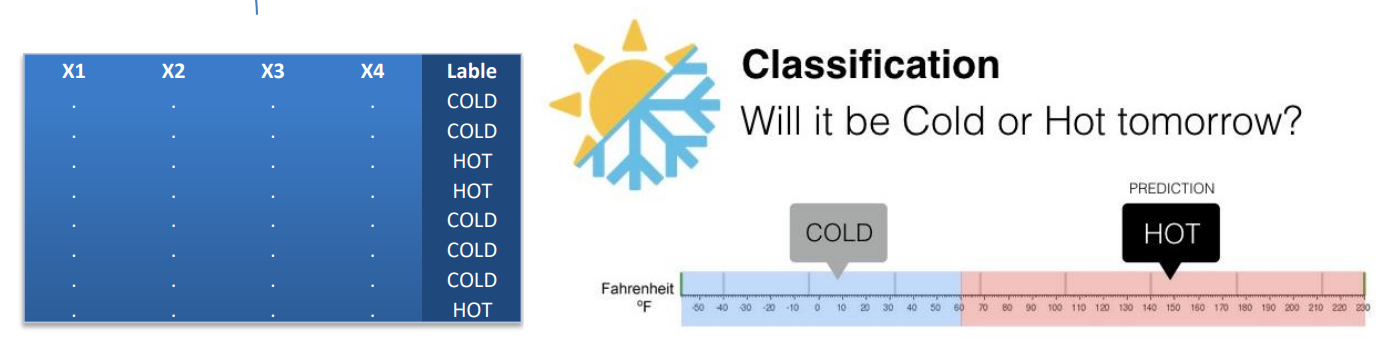
طبقه بندی (Classification):
- یادگیری با نظارت است (Supervised Learning)
- طبقه بندی مقدار هدف با توزیع آماری گسسته
اصولاً از تکنیک های طبقه بندی برای طبقه بندی هر داده در مجموعه ای از داده ها و اختصاص به یکی از مجموعه های از پیش تعیین شده کلاس ها یا گروه ها استفاده می شود. روش طبقه بندی از تکنیکهای ریاضی مانند درخت تصمیم، برنامه ریزی خطی، شبکه عصبی و آمار برای طبقه بندی استفاده می کند.
به عبارتی طبقه بندی، فرایند یافتن مدلی که توصیف کننده کلاس ها و مفاهیم داده است و داده ها را به گروه های مشخص تفکیک می کند. الگوریتم های طبقه بندی، قادر به یادگیری از تجربیات گذشته هستند و این یادگیری بر اساس تجربه نشان دهنده یک گام اساسی در تقلید از توانایی های استقرایی مغز انسان است که بر اساس این توانایی مغز میتواند مسئله ی شناسایی یک گروه از دسته ها (زیرجمعیت ها) را انجام دهد.
فرض کنیم در مثال قبل بخواهیم دمای هوا را به دو طبقه یا کلاس گرم و سرد تقسیم نماییم، در اینجا اعداد به یک حالت کیفی تبدیل شده اند و به جای اعداد کلاس را خواهیم دید.
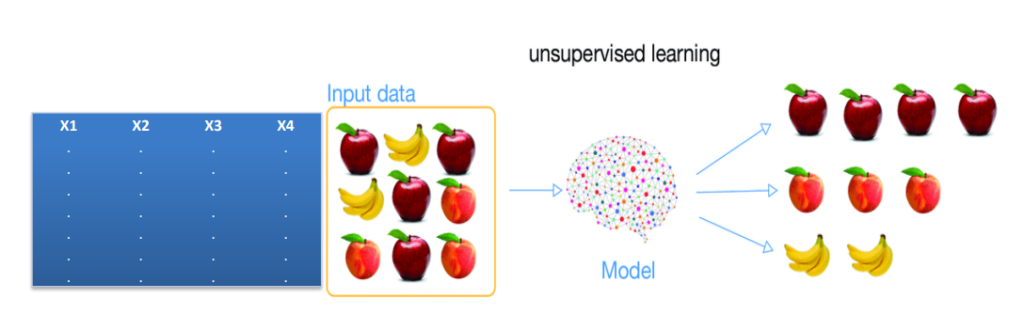
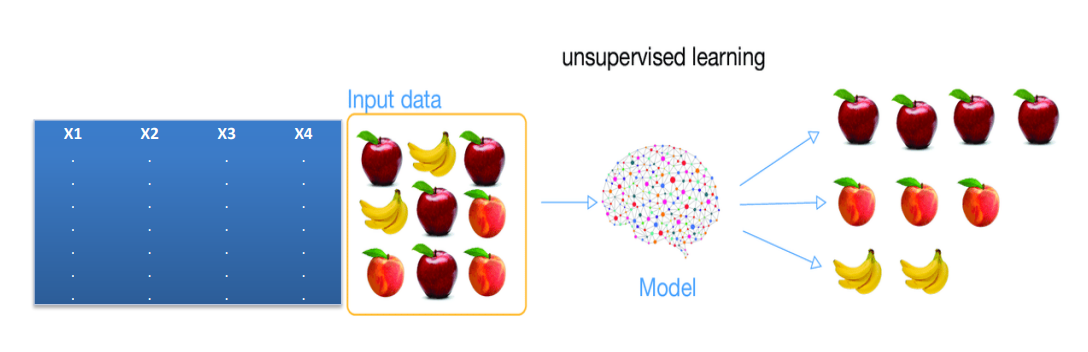
خوشه بندی (Clustering):
- یادگیری بدون نظارت است (Unsupervised Learning)
- در این نوع، فیلد با اهمیت و یا شاخصی وجود ندارد و همه فیلد ها input هستند و نمی توان برای آن تابع خاص و رابطه خاصی را هدف فرض نمود.
بخشبندی که اصطلاح کاملتر و دقیقتر آن تحلیل خوشهبندی (Cluster Analysis) است به فرآیندی اشاره دارد که با استفاده از آن میتوان مجموعهای از اشیا را به گروههای مجزا از یکدیگر تخصیص داد. اعضا هر خوشه بر مبنای ویژگیهایی که دارند به یکدیگر شباهت دارند و در مقابل میزان شباهت بین خوشهها کم است.
خوشهبندی با هدف برچسبگذاری اشیا انجام میشود تا امکان شناسایی اشیایی که عضو گروههای مختلف هستند با سهولت انجام شود. در این روش دادهها به گروههای معناداری تقسیم میشوند که محتویات هر خوشه ویژگیهای مشابه، اما متفاوت از سایر اشیایی دارد که در گروههای دیگر قرار گرفتهاند. از مکانیزم خوشهبندی در مجموعه دادههای بزرگ و در مواردی که تعداد خصلتهای دادهای زیاد باشد استفاده میشود.
معمولا با استفاده از خوشه بندی یک فیلد کیفی به اطلاعات اضافه می شود و پس از تحلیل خوشه بندی می توان از تحلیل طبقه بندی یا همان Classification استفاده نمود.
مثال: فرض کنید، شما یک فروشگاه بزرگِ مواد غذایی دارید و مشتریانِ این فروشگاه که بالغ بر ۱۰۰ هزار نفر هستند ویژگیهای مختلفی دارند. اجازه دهید، سه ویژگیِ زیر را برای یک مشتریِ خاص از مشتریان این فروشگاهِ بزرگ مواد غذایی در نظر بگیریم (بقیهی مشتریان نیز این ویژگیها را دارند):
۱. این مشتری آخرین خریدِ خود را چند روز پیش انجام داده است؟(که با R نام گذاری میکنیم)
۲. این مشتری در یکسالِ گذشته، به طورِ میانگین چند روز یک بار از فروشگاه ما خرید کرده است؟ (که با F نام گذاری میکنیم)
۳. این مشتری در یکسالِ گذشته به طورِ میانگین در هر بار خرید، چه مبلغی از فروشگاه خرید کرده است؟(که با M نامگذاری میکنیم)
حال به جدول زیر که نوعی ماتریس است نگاهی بیندازید. اینها قسمتی از دادههای ما هستند:
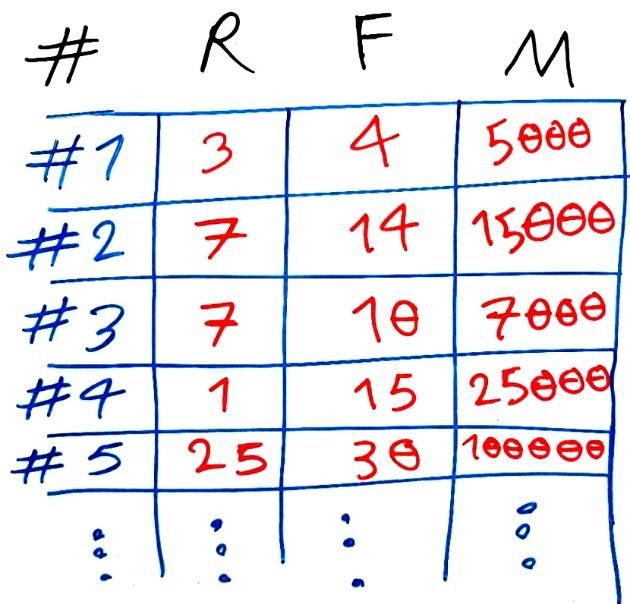
هر سطر در این جدول، یک مشتری را نشان میدهد. ستونهایR و F و M به ترتیب سه ویژگی یا سه بُعدِ مسئله ما را تشکیل میدهند که مطابق با سه ویژگیِ گفته شده در بالا است. اینها ۵ نمونه از ۱۰۰ هزار مشتریِ فروشگاه ما را تشکیل می دهند که در جدول بالا نمایش داده شده است.
به فرد شماره ۱ توجه کنید: این فرد ۳ روز گذشته آخرین خرید خود را انجام داده است (ویژگی R) در یکسال گذشته به طور میانگین هر ۴ روز یکبار خرید انجام داده (ویژگی F ) و به طورِ میانگین در یکسال گذشته در هر خرید ۵۰۰۰ تومان خرید کرده است. بقیهی مشتریان را هم میتوانید به همین ترتیب تفسیر کنید.
قوانین انجمنی (Association Rules):
- یادگیری بدون نظارت است (Unsupervised Learning)
- قوانین انجمنی، تحلیل وابستگی بین وقوع رخدادها از نظر با همآِیی و تقدم-تاخر
تاریخچه قواعد انجمنی
مفهوم قوانین وابستگی یا انجمنی در سال ۱۹۹۳ پس از انتشار مقاله اگرول مورد توجه خاص قرار گرفت. با توجه به اطلاعات آماری سرویس Google Scholar ، در مارس ۲۰۰۸ این مقاله بیش از ۶۰۰۰ نقل قول (citation) دریافت کرده است که آن را در صدر بیشترین تعداد نقل قول ها در گرایش داده کاوی قرار می دهد. اگرچه ممکن است آنچه که امروزه قوانین وابستگی نامیده می شود، همان مفهوم مطرح شده در مقاله سال 1966 تحت عنوان GUHA (یک متد عمومی داده کاوی) مطرح شده است.
در داده کاوی، یادگیری قانون وابستگی یا انجمنی یک متد مناسب برای یافتن روابط جذاب بین متغیرهای موجود در پایگاه داده های بزرگ است. پیاتتسکی-شاپیرو در چگونگی تحلیل و ارائه قوانین قوی یافته شده را در پایگاه های داده با استفاده از معیارهای متفاوت جذابیت توضیح می دهد. بر مبنای مفهوم قوانین قوی، راکش اگرول و همکارانش قوانین وابستگی را برای کشف قاعده های موجود بین محصولات در داده های تراکنشی با مقیاس بالا معرفی می کنند.
در اینجا فیلد شاخص و با اهمیت هدف وجود ندارد و با بررسی رکورد ها در کنار هم می توان به تحلیل داده ها دست یافت، در این تحلیل، جهت تحلیل اهمیت دارد، به عنوان مثال در تصویر زیر می توان انتظار داشت که اگر کالای A خریده شود کالای B نیز خرید می شود بنابراین نمی توان انتظار داشت که اگر کالای B خریده شود حتما کالای A خرید می شود. در واقع Association Rules ها به ما قوانین اگر و آنگاه را خروجی می دهند.
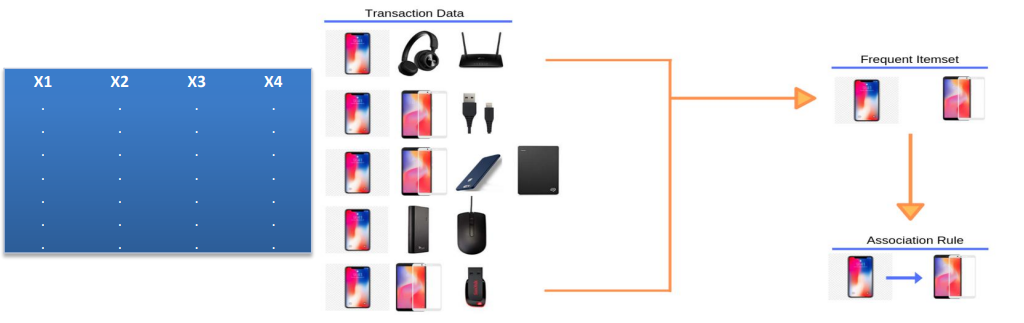
از جمله نمونه های کاربرد قوانین انجمنی را در سیستم های پیشنهادگر در سایت های فروشگاه اینترنتی، در نحوه طبقه بندی و چیدمان در قفسه فروشگاه ها و… می توان شاهد بود.
توصیف مفهوم (Concept Desc.):
در بسیاری از مسئله های داده کاوی، توصیف چگونگی وقوع یک پدیده مهمتر از پیش بینی دقیق آنهاست. در این نوع مسائل به دنبال توصیف یا تعریفی از الگوهای بدست آمده هستیم.
بطور مثال
- مشتریان وفادار چه ویژگی هایی دارند؟
- پذیرفته شدگان در کنکور دارای چه مشخصاتی می باشند؟
وضعیت سهام در روز آتی چگونه خواهد بود؟ سود، ضرر؟

تشخیص انحراف (Deviation Detection):
در بسیاری از مسئله های داده کاوی، الگوی موارد نادر و خاص که به نوعی انحراف از وضعیت نرمال می باشند مد نظر می باشد. در این نوع مسائل به دنبال شناسایی و کشف الگوهای آنومالی و پیش بینی آنها هستیم.
در دادهکاوی به فرآیند شناسایی نمونهها، رویدادها یا مشاهداتی که با الگوها یا دیگر نمونههای موجود در مجموعه داده مطابقت نداشته باشند، «تشخیص ناهنجاری (Anomaly detection) یا تشخیص دورافتادگی (Outlier Detection) گفته میشود. معمولا ناهنجاریها بسته به نوع مساله، مربوط به کلاهبرداری بانکی، حملات سایبری ساختاریافته، مشکلات پزشکی یا وجود خطا در متن هستند. به ناهنجاری، دورافتادگی، الگوی نوظهور، نویز (Noise)، انحراف(deviation) و استثنا (exception) نیز گفته میشود.
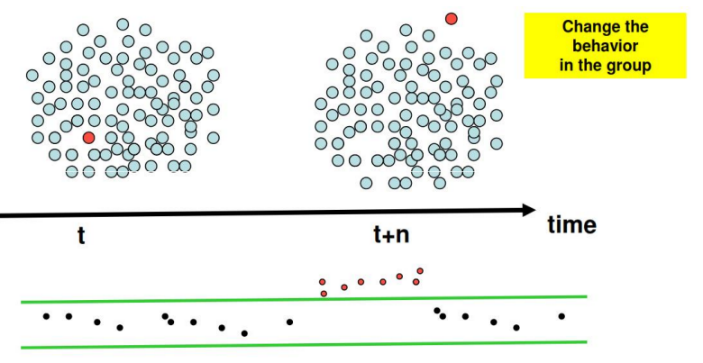
بطور مثال
- شناسایی الگوی تقلب در صنعت بیمه
- پیش بینی خرابی در یک توربین گازی
پس از شناسایی داده های پرت، معمولا یا آن ها را جدا می نماییم، یا با مقداری دیگر جایگزین می کنیم یا با سایر روش ها و بنا به نوع مساله با آن برخورد می شود.