مقادیر گمشده به داده هایی گفته می شود که به دلایل مختلفی همچون عدم ثبت (یا پاسخ دهی) عمدی یا سهوی در مجموعه داده ها ایجاد شده است. همچنین داده های گمشده می تواند به علت استفاده از استراتژی های پاکسازی مقادیر خارج از بازه منطقی یا داده های پرت بوجود آمده باشد.
ثبت و مشخص کردن مشاهداتی که دارای داده گمشده هستند از اهمیت زیادی برخوردار است. در مواجهه با این موارد، ممکن است لازم باشد، مقدار چنین مشاهداتی بازنگری شده یا بر حسب میانگین دیگر مشاهدات، جایگزین شود. از همین رو در این درس به معرفی دادههای گمشده پرداخته و روشهای مدیریت آنها را مرور خواهیم کرد.
باید توجه داشت که چنین دادههایی را در برخی نرمافزارها مانند زبان برنامهنویسی R با مقدار NA مشخص میکنند که اختصار بر گرفته از عبارت «Not Available» است و به آنها داده ناموجود میگویند.
نکته: بررسی علت شکل گیری داده های گمشده، جهت انتخاب روش برخورد از اهمیت بالایی برخوردار می باشد.
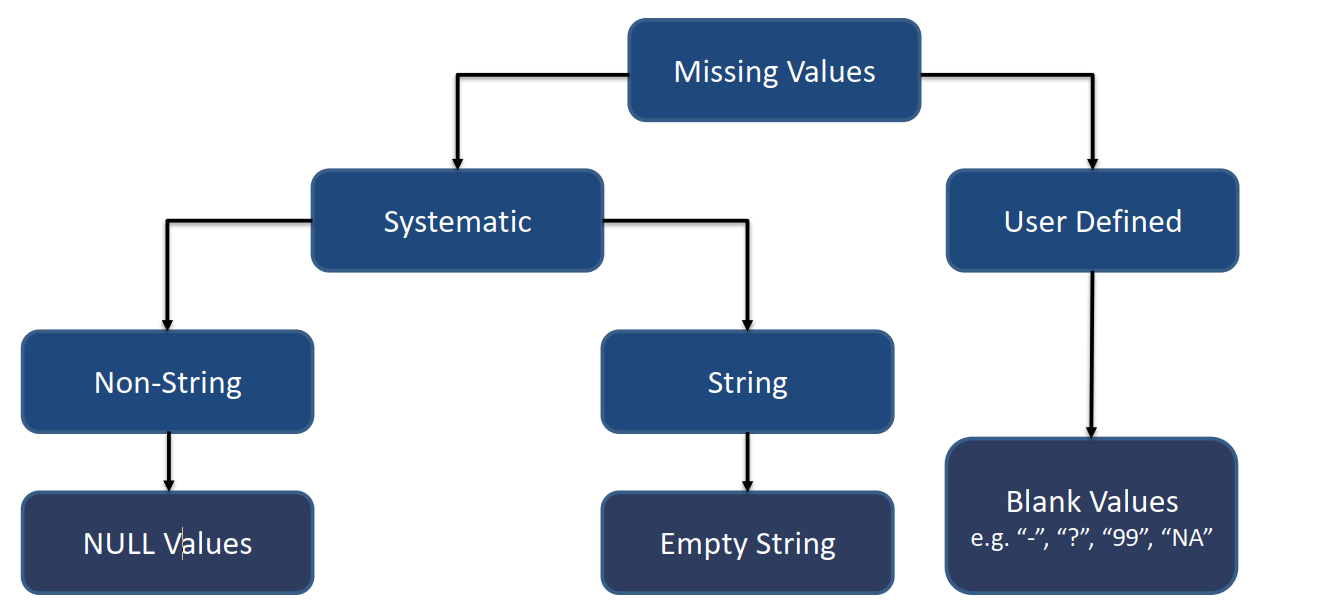
انواع داده های گمشده به دو گروه تقسیم میشوند:
- مقدارهای گمشده سیستمی (System Missing Values)
در گروه یا نوع اول که به آن مقدارهای گمشده سیستمی (System Missing Values) گفته میشود، مقدار ثبت یا اندازهگیری نشده است.
- مقدارهای گمشده کاربر (User Missing Values)
منظور از داده گمشده کاربر، مقداری است که توسط کاربر وارد شده به عبارت دیگر هر کاراکتری که توسط کاربر وارد شده باشد تا نشان دهد داده آن فیلد صحیح نیست مقدار user missing value خواهد بود.
استراتژی های برخورد با مقادیر گمشده
انتخاب روش برخورد با مقادیر گمشده به پارامترهای مختلفی وابسته است؛ همچون:
1- ماهیت و موضوع زمینه ای داده های گمشده
بررسی دقیق از ماهیت و ارتباط مقادیر یک ویژگی با سایر ویژگی ها گام اول جهت شناسایی و برخورد با داده های گمشده میباشد.
به طور مثال: درجدول داده روبرو تعداد 4 مقدار گمشده مشاهده میشود. با دقت در ماهیت داده ها خواهیم دید 3 مقدار گمشده مربوط به رکوردهایی می باشد که وضعیت تأهل آنها “مجرد” است. بنابراین بصورت ذاتی آنها بدون مقدار می باشند.
نحوه برخورد: برخورد با مقادیر گمشده که بصورت ذاتی دارای مقدار نمی باشند اغلب با تعریف کلاس جدید مانند “Unknown” یا مقدار دهی عدد ثابت براساس موضوع داده مورد بررسی و یا ادغام ویژگی های مرتبط انجام میشود.
2- پراکندگی وقوع مقادیر گمشده
3- تعداد ویژگی های دارای مقادیر گمشده در هر رکورد
4- تعداد رکوردهای دارای مقادیر گمشده در هر ویژگی
5- اهمیت ویژگی های دارای مقادیر گمشده و ارتباط آنها با سایر ویژگی ها
استراتژی های برخورد با مقادیر گمشده
روش های عمده در برخورد با مقادیر گمشده شامل موارد زیر است:

روش حذفی:
حذف رکوردها با ویژگی هایی که دارای مقادیر گمشده می باشند یکی از سریعترین و راحتترین استراتژی های برخورد می باشد.
حذف ویژگی ها: در اغلب موارد ویژگی هایی که دارای تعداد زیادی مقادیر گمشده باشد (بیش از %50) و امکان دسترسی به داده های صحیح نباشد به علت جلوگیری از بایوس (اریبی) از تحلیل کنار گذاشته می شوند. در مواردی که ویژگی مورد نظر اهمیت بسیار زیادی در تحلیل داشته باشد میتوان از کلاس “unknown “ برای آنها استفاده کرد.
حذف رکوردها: حذف کلیه رکوردهای دارای مقادیر گمشده، امکان از دست دادن تعداد قابل توجهی از مجموعه داده ها را در پی دارد. بنابراین این استراتژی عموما برای رکوردهای بی کیفیت که تعداد ویژگی های مفقود شده آن بیش از %50 کل ویژگی ها باشد استفاده می شود و یا در مواردی که داده های بسیار بزرگ در اختیار داریم قابل استفاده است.
روش جانشینی با اعداد ثابت یا تصادفی
روش های جانشینی عمدتا بر اساس پارامترهای توزیع هر ویژگی مانند میانگین، میانه، مد و … و یا شبیه سازی توزیع آماری ویژگی ها انجام می شود. استفاده از این روش در تعداد زیاد مقادیر گمشده، مستعد بایاس و خطا در تحلیل هست و بایستی با توجه به شناخت از ماهیت و کمیت داده ها انجام شود.
نکته 1: در توزیع های دارای چولگی استفاده از میانه جایگزین بهتری نسبت به میانگین میباشد.
نکته 2: در مجموعه داده هایی که رکوردهای آن دارای توالی زمانی هستند، استفاده از درونیابی و یا پارامترهای متحرک (مانند میانگین متحرک) مفید میباشد.
نکته 3: استفاده از شبیه سازی توزیع آماری (بطور مثال تولید اعداد تصادفی از توزیع نرمال، یکنواخت و یا توزیع تجربی) و جانشینی آن با مقادیر گمشده، منجر به جلوگیری از بایاس بودن نتایج میشود، اما همچنان ریسک ایجاد خطا در داده ها وجود دارد.
روش جانشینی با الگوریتم
روش های الگوریتمی از نظر جلوگیری از بایاس و ناسازگاری در داده ها بهترین روش می باشند اما دارای پیچیدگی های محاسباتی و اجرایی هستند.
استفاده از روشهای الگوریتمی دارای فرض ارتباط منطقی بین ویژگی دارای مقادیر گمشده با سایر ویژگی ها هست. بنابراین فرض، سایر ویژگی های مرتبط به عنوان ورودی الگوریتم برای حل مسئله رگرسیون پیش بینی یا رده بندی در نظر گرفته میشود.