
در این پست ابتدا خلاصه جلسه و سپس متن کامل جلسه آموزشی را مطالعه خواهید کرد:
خلاصه جلسه
1. معرفی پروژه
- پروژه: پیشبینی داروی تجویزشده بر اساس اطلاعات پزشکی بیماران.
- نوع مسئله: Classification (طبقهبندی).
- نوع یادگیری: Supervised Learning (یادگیری با ناظر).
2. بررسی فایل داده
- فایل با فرمت متنی (Flat File) و جداشده با کاما (CSV).
- شامل فیچرهایی مانند: سن، جنسیت، فشار خون، کلسترول، سدیم، پتاسیم.
- آخرین ستون: داروی تجویزشده (متغیر هدف).
3. استفاده از Notepad++
- توصیه به استفاده از Notepad++ برای بررسی فایلهای متنی.
- نمایش بهتر و امکانات بیشتر نسبت به Notepad معمولی.
4. ورود به Kaggle و آپلود دیتا
- از بخش Datasets وارد شده و یک پوشه جدید (مثلاً intro-ds) میسازیم.
- فایل داده را به این پوشه درگ و دراپ میکنیم.
- میتوان Dataset را به صورت Private یا Public تنظیم کرد.
- قابلیت اضافه کردن داده از:
- URL
- GitHub
- نوتبوک دیگر
- منابع دیگر Kaggle
5. ساخت نوتبوک جدید در Kaggle
- استفاده از “New Notebook” برای شروع برنامهنویسی.
- محیط مشابه Jupyter Notebook با زبان Python.
- قابلیت اتصال مستقیم Dataset به نوتبوک.
6. تنظیمات نوتبوک
- انتخاب Dataset از “Your Datasets” یا “Competition Datasets”.
- امکان استفاده از:
- Python یا R
- GPU یا TPU
- اتصال اینترنت
7. اجرای کد نمونه
- اجرای سلول با Run یا Run All.
- نمایش فایلهای موجود در پوشهی input.
8. محیط اجرای پایتون
- نسخه پایتون: ۳
- کتابخانههای پیشفرض نصبشده:
numpyبرای محاسبات عددیpandasبرای کار با دادههای جدولی (DataFrame)
- Import کتابخانهها:
import numpy as npimport pandas as pd
متن کامل این جلسه:
در این جلسه، برای اولین بار میخواهیم یک پروژه را بهصورت عملی و گامبهگام در محیط Kaggle پیادهسازی کنیم. در ویدیوی قبلی، مسئلهی پروژه مطرح شد: پروژهای در حوزهی اطلاعات بیماران یک کلینیک. در فاز اول که مرحلهی فهم بیزینسی (Business Understanding) است، به چالشهایی مانند شفاف نبودن تعریف مسئله برخوردیم. در آن ویدیو تمرین کردیم که چطور میتوانیم از روی دیتاست موجود، به یک تعریف دقیقتر و کاربردیتر از مسئله برسیم.
در نهایت به این صورت مسئله رسیدیم: پیشبینی داروی تجویزشده توسط پزشک، بر اساس اطلاعات پروفایل بیمار یا همان پروندهی پزشکی او.
اگر به خاطر داشته باشید، دادهها را بهصورت نمونه دیده بودیم. فایل دادهای که داریم، یک فایل متنی فلت (Flat File) است که میتوان با ابزارهایی مثل Notepad++ آن را باز کرد. توصیه میشود Notepad++ را نصب داشته باشید چون ابزار سبکی است و نسبت به نوتپد معمولی قابلیتهای بیشتری برای نمایش بهتر محتوا به شما میدهد.
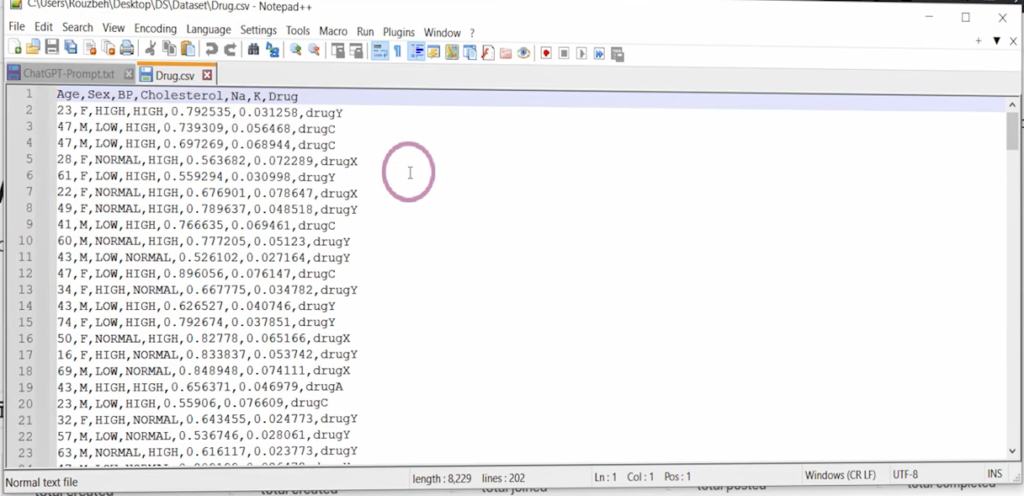
در این فایل، دادهها با کاما (,) از هم جدا شدهاند. هر سطر یک رکورد است. سطر اول، نام فیچرهاست و سطرهای بعدی مقادیر مربوط به هر رکورد هستند. فیچرهایی مثل سن، جنسیت، فشار خون، کلسترول، سطح سدیم و پتاسیم وجود دارند و در نهایت ستون مربوط به داروی تجویزشده قرار دارد. این داروها در چند کلاس دستهبندی شدهاند، بنابراین با یک متغیر کیفی طرف هستیم. مسئلهی ما از نوع Classification یا طبقهبندی است و در دستهی یادگیری با ناظر (Supervised Learning) قرار میگیرد.
حال وارد محیط Kaggle میشویم. فرض بر این است که شما قبلاً حساب کاربری Kaggle و حساب ChatGPT خود را فعال کردهاید. از ChatGPT بهعنوان یک دستیار هوشمند کمک میگیریم تا در انجام مراحل پروژه، راهنمایی بدهد و حتی کدهایی را برای ما بنویسد. این کدها را در زیرساخت Kaggle که بهصورت آنلاین و بدون محدودیت نرمافزاری و سختافزاری در دسترس است، اجرا خواهیم کرد.
ما در این پروژه عمدتاً از دو بخش “Datasets” و “Notebooks” استفاده خواهیم کرد. این دو بخش به هم مرتبطاند. مثلاً اگر قبلاً روی یک دیتاست کدی نوشته باشید، وقتی آن را باز کنید، به نوتبوک مربوطه متصل خواهد شد و بالعکس. اما برای سازماندهی بهتر، ترجیح میدهیم از بخش دیتاست شروع کنیم.
در صفحهی Datasets میتوانید یک Dataset جدید بسازید. مثلاً یک پوشه بهنام intro-ds ایجاد میکنیم. این پوشه در واقع فضای دیسکی است که Kaggle در اختیار شما میگذارد. در این پوشه میتوانیم فایل دادهی خود را آپلود کنیم. پس از ساخت پوشه، مسیری به آن اختصاص داده میشود بهصورت:
kaggle.com/datasets/<نامکاربری>/<نامپوشه>
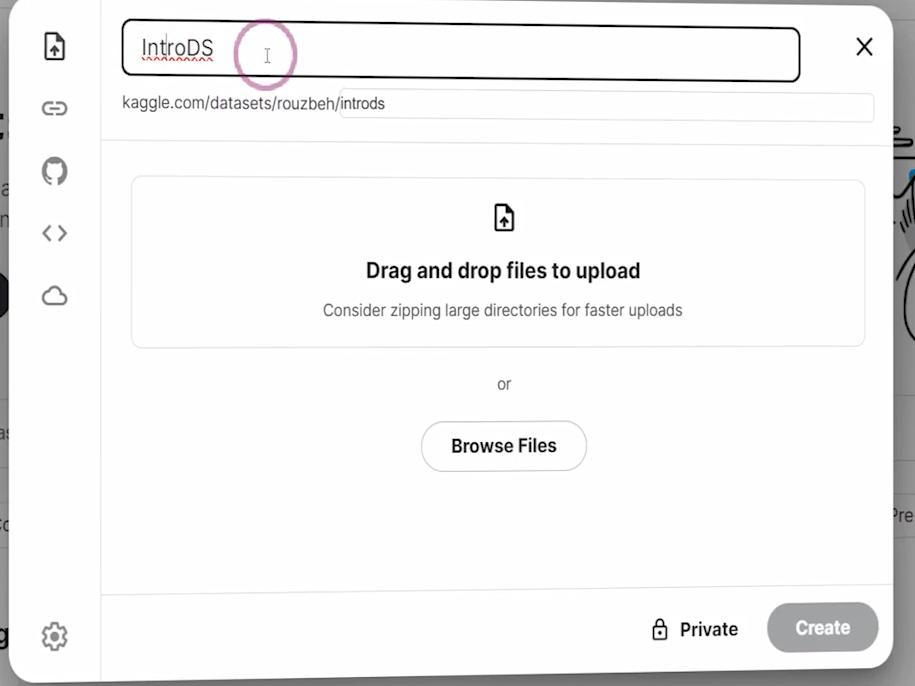
حالا میتوانیم فایل داده را بهراحتی به این مسیر درگ و دراپ کنیم تا آپلود شود. اگر قبلاً این فایل را آپلود کرده باشید، Kaggle پیامی به شما میدهد مبنی بر اینکه این فایل وجود دارد و آیا میخواهید یک نسخهی تکراری بسازید یا خیر. اگر تأیید کنید، فایل دوباره بارگذاری میشود.
همچنین میتوانید داده را از منابع دیگر وارد کنید، مثلاً:
- URL مربوط به دادهای که در یک هاست قرار دارد.
- اتصال به اکانت GitHub.
- استفاده از دادههای یک نوتبوک دیگر.
بعد از اضافه کردن داده، در داشبورد خود میتوانید وارد آن Dataset شوید، عنوان و توضیحاتی برای آن بنویسید و در صورت تمایل Dataset را عمومی (Public) کنید تا دیگران هم به آن دسترسی داشته باشند.
حال وارد بخش کدنویسی میشویم. از سمت چپ، وارد بخش “Code” شده و گزینهی “New Notebook” را میزنیم تا نوتبوک جدیدی ساخته شود. این محیط در واقع شبیه محیط Jupyter Notebook است. محیطی برای نوشتن و اجرای کد با استفاده از زبان Python. موتور اجرای پایتون در پشت صحنه کدها را تحلیل و اجرا میکند.
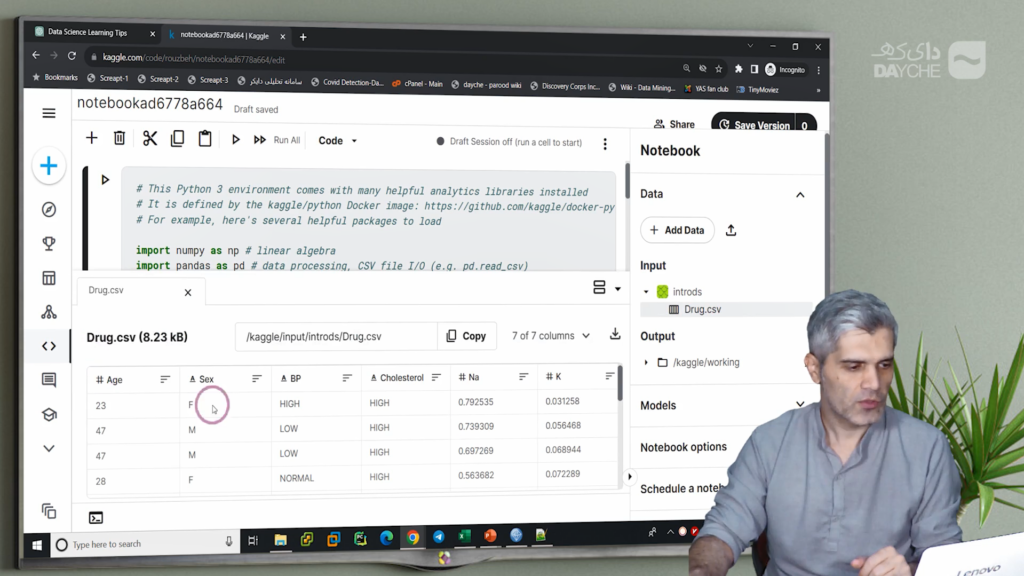
در سمت راست این محیط، بخشی بهنام Data وجود دارد که از آنجا میتوانید Dataset خود را به نوتبوک متصل کنید. میتوانید یکی از Datasetهای عمومی موجود در سایت را انتخاب کنید یا از قسمت “Your Datasets”، دیتاستی که خودتان ساختهاید را انتخاب کرده و با گزینهی “Add” به نوتبوک اضافه کنید. مثلاً Dataset intro-ds را به نوتبوک وصل میکنیم و حالا در بخش Input، مسیر آن نمایش داده میشود. با کلیک روی فایل csv، محتوای آن بهشکل جدول نیز نمایش داده میشود.
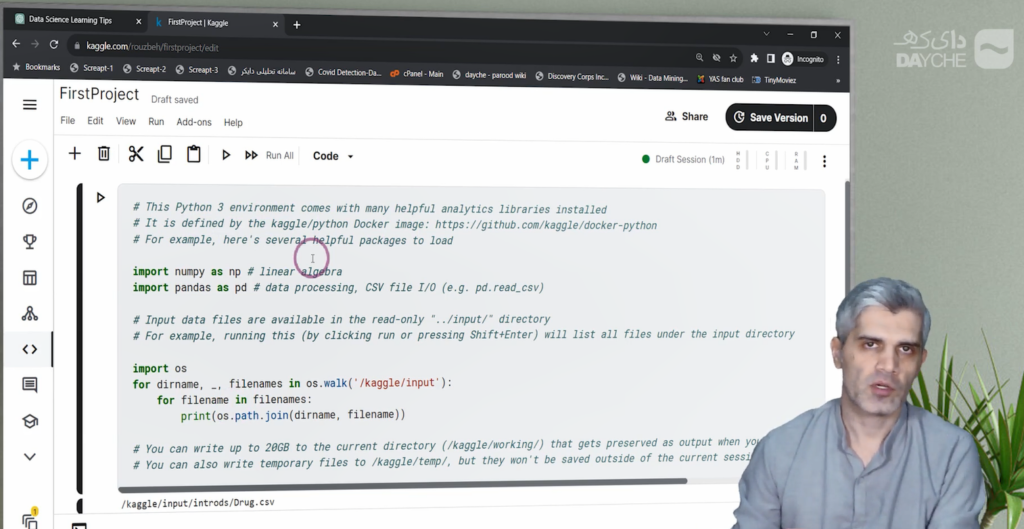
در قسمت بالا، میتوانیم نام نوتبوک را تعیین کنیم، مثلاً First-Project. پس از ساخت، یک Session آغاز میشود و میتوانید کدنویسی را شروع کنید. با زدن گزینهی Start، اتصال برقرار میشود و Session فعال خواهد شد.
اکنون میتوانیم اولین کد نمونه را اجرا کنیم. مثلاً یک کد ساده که لیست فایلهای موجود در پوشهی input را نمایش میدهد. اگر فقط یک سلول داشته باشیم، با گزینهی Run آن را اجرا میکنیم. اگر چند سلول باشد، گزینهی Run All همهی سلولها را به ترتیب اجرا خواهد کرد.
کدی که در اینجا اجرا شده، از پوشهی input لیست فایلها را میگیرد و نمایش میدهد. میبینیم فایل intro-ds.csv شناسایی شده و مسیر آن هم مشخص است.
نسخهی پایتون این محیط، پایتون 3 است. برخی کتابخانهها مانند numpy و pandas بهصورت پیشفرض نصب هستند. اگر بعدها نیاز به نصب کتابخانههای دیگر بود، میتوان از طریق اتصال به اینترنت در همین محیط، آنها را نصب کرد.
کتابخانهی numpy برای انجام محاسبات برداری، جبر خطی و عملیات ماتریسی بسیار مناسب و سریع است. pandas نیز برای کار با دادههای جدولی (DataFrame) استفاده میشود؛ مثلاً وقتی یک فایل csv را میخواهید بخوانید، با استفاده از pandas میتوانید آن را به یک جدول داده تبدیل کنید، همانند چیزی که در نرمافزار Excel میبینید.
برای استفاده از کتابخانهها در پایتون، باید ابتدا آنها را import کنید. مثلاً:
import numpy as np
import pandas as pd
در این صورت، میتوانید از np و pd بهعنوان نامهای کوتاهشده برای دسترسی به توابع و متدهای موجود در numpy و pandas استفاده کنید.
البته ما در این مرحله جزئیات مربوط به این کدنویسیها را به عهدهی ChatGPT میگذاریم و صرفاً قصد داریم پروژه را پیش ببریم و یاد بگیریم. این جزئیات در دورهی آموزش پایتون بهصورت مفصل بررسی خواهند شد.
در همین حد برای شروع کفایت میکند. سلول نمونه را پاک میکنیم و از جلسهی بعد، مسیر پروژه را از طریق ChatGPT پیگیری خواهیم کرد و فرآیند حل مسئله را گامبهگام در نوتبوک اجرا خواهیم کرد.