
مقدمه
در ادامه مباحث، وارد بخش عملی پروژهی EDA بر روی دادههای مربوط به بیماران کلینیک شدیم. تا اینجا در ویدیوی قبلی به مرحلهی ارتباطسنجی میان برخی ویژگیها با متغیر هدف رسیدیم. بهویژه به بررسی فیلدهای سدیم و پتاسیم پرداختیم.
این دو متغیر عددی ماهیتی نزدیک به هم داشتند. بنابراین مطرح کردیم که آیا بین این دو ارتباطی وجود دارد یا خیر. اهمیت این موضوع در آن است که در مدلسازی معمولاً تمایل داریم ورودیها از یکدیگر مستقل باشند. چنانچه میان دو ویژگی عددی (مانند سدیم و پتاسیم) رابطهی خطی قوی وجود داشته باشد، ترجیح میدهیم تنها یکی از آنها را در مدل استفاده کنیم و هرگز هر دو را بهطور همزمان وارد مدل نمیکنیم. از همین رو، بررسی این موضوع در فرایند EDA اهمیت ویژهای دارد.
بررسی ارتباط بین سدیم و پتاسیم
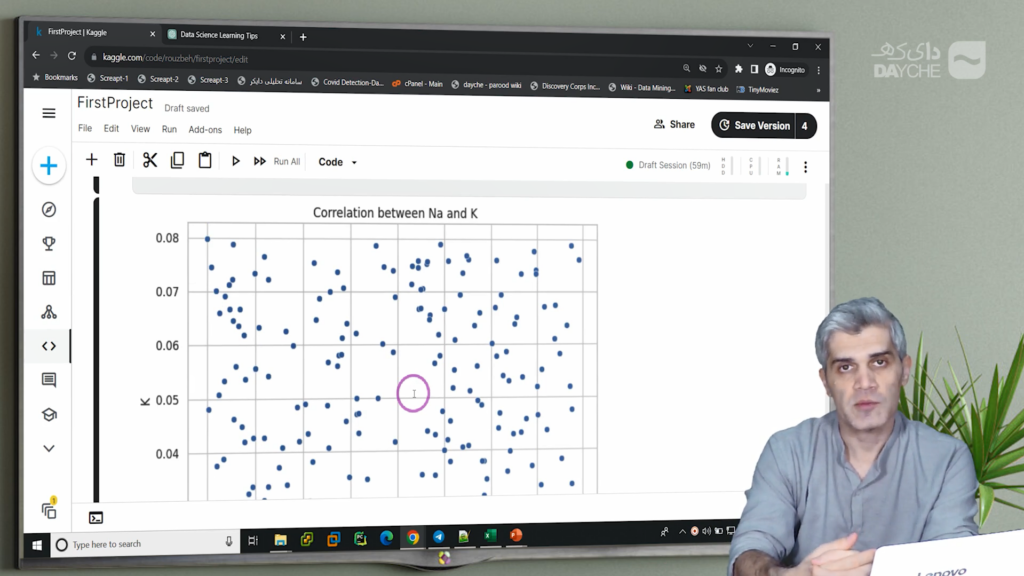
در ویدیوی قبلی نمودار مربوط به این بررسی را اجرا کردیم اما با خطایی مواجه شدیم که به دلیل مشکل پردازشی (CPU) بود. با تغییراتی در کد این مشکل رفع شد و نمودار رسم گردید.
نتایج نشان داد که هیچ ارتباط خطی یا غیرخطی میان سدیم و پتاسیم وجود ندارد. در فضای دوبعدی تشکیلشده از این دو متغیر، نقاط بهصورت پراکنده و بدون الگوی مشخص قرار گرفتهاند. بنابراین نگرانی از بابت همبستگی خطی شدید میان این دو متغیر وجود ندارد.
بررسی ترکیب سدیم و پتاسیم در ارتباط با دارو
پس از رسم نمودار، این پرسش مطرح شد که آیا ترکیب این دو متغیر میتواند در ارتباط با نوع داروی تجویزی معنادار باشد یا خیر. برای این منظور نمودار دوبعدی سدیم و پتاسیم مجدداً رسم شد، اما این بار نقاط بر اساس نوع دارو با رنگهای مختلف نمایش داده شدند.
نتیجه جالب توجه بود:
-
در بخشهایی از نمودار که داروی Y تجویز شده بود، تقریباً هیچ داروی دیگری دیده نمیشد.
-
در مقابل، در بخشهای دیگر نمودار، داروی Y مشاهده نمیشد و سایر داروها حضور داشتند.
این موضوع نشان میدهد که پزشک احتمالاً بر اساس نسبتی میان سدیم و پتاسیم تصمیم به تجویز داروی Y میگیرد.

ایدهی ایجاد ویژگی جدید
از مشاهدهی نمودار میتوان نتیجه گرفت که نسبت سدیم به پتاسیم میتواند یک ویژگی مهم در مدلسازی باشد. به جای استفاده از دو ستون جداگانه، میتوان ویژگی جدیدی بهصورت نسبت سدیم به پتاسیم ایجاد کرد. این کار میتواند به مدل کمک کند تا سریعتر و دقیقتر الگوی تصمیمگیری پزشک را شناسایی کند.
سایر متغیرها و ارتباط با داروها
علاوه بر سدیم و پتاسیم، سایر متغیرها نیز بررسی شدند:
-
کلسترول: در نمودار مربوطه مشاهده شد که برای داروی C توزیع متفاوتی نسبت به سایر داروها وجود دارد.
-
فشار خون: ارتباطات معنادار و تفاوتهای محسوس در تجویز دارو دیده شد.
-
جنسیت: در توزیع داروها تفاوت قابل توجهی میان زنان و مردان دیده نشد. به عبارت دیگر، به نظر میرسد جنسیت بر نوع داروی تجویزی اثرگذار نباشد.
آزمونهای آماری برای تأیید نتایج
برای اطمینان بیشتر از یافتهها، نیاز به استفاده از آزمونهای آماری داریم. به عنوان نمونه، در بررسی جنسیت و دارو از آزمون استقلال کای-دو (Chi-Square Test of Independence) استفاده شد.
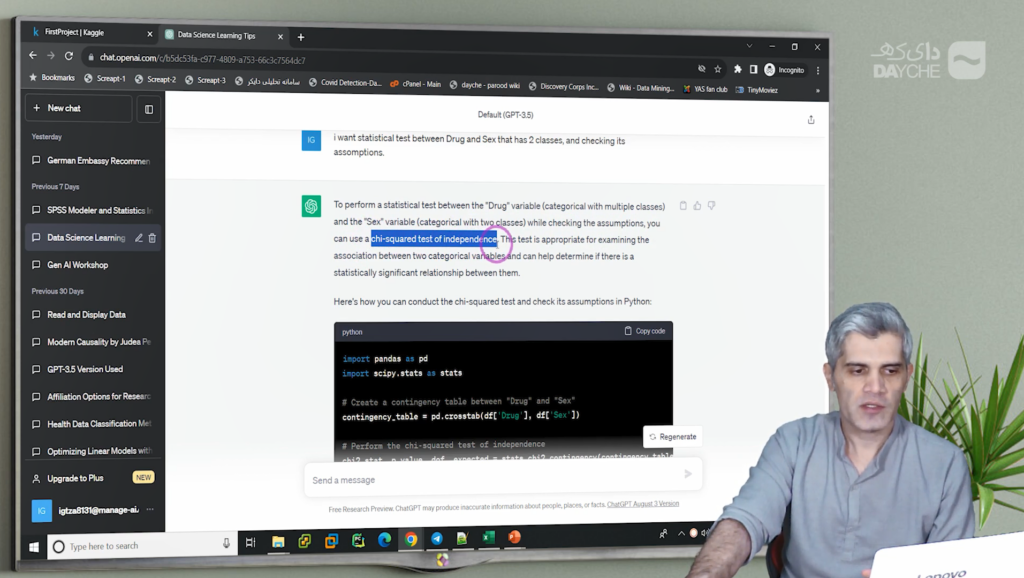
مراحل آزمون
-
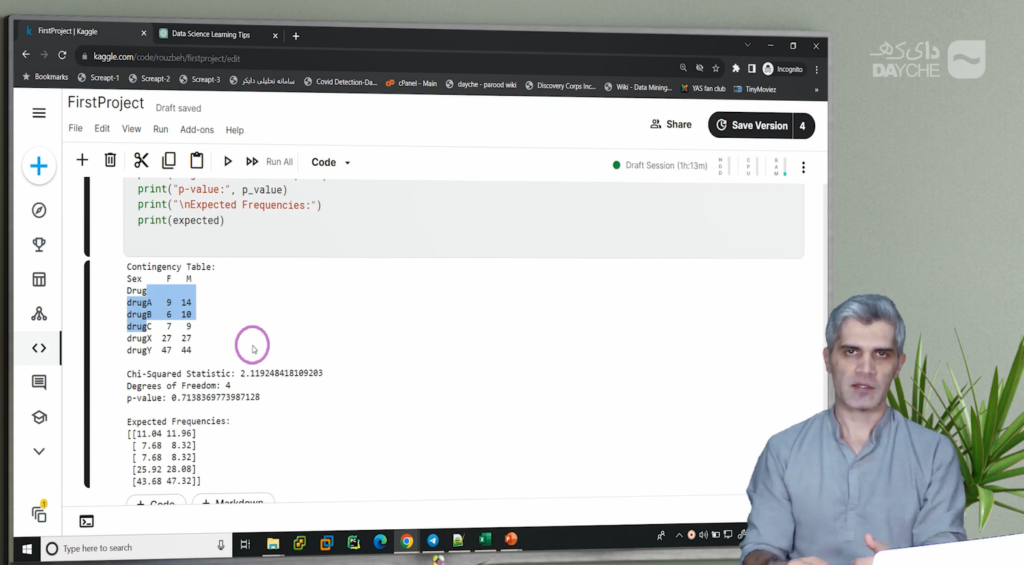
ابتدا جدول توافقی میان جنسیت و نوع دارو تشکیل شد. این جدول نشان میداد برای هر جنسیت چه تعداد از هر دارو تجویز شده است.
-
سپس آزمون کای-دو اجرا شد.
-
آماره آزمون (X²) و درجه آزادی (df) محاسبه شد.
-
p-value به دست آمد.
-
تفسیر p-value
با توجه به اینکه مقدار p-value بسیار بزرگتر از سطح معناداری متداول (۵٪) بود، نتیجه گرفتیم که فرض اولیه (عدم ارتباط میان جنسیت و دارو) رد نمیشود. بنابراین میتوان گفت:
جنسیت و دارو مستقل از یکدیگر هستند و جنسیت عامل تعیینکنندهای در تجویز دارو نیست.
اهمیت بررسی فرضیات آزمونها
آزمونهای آماری بر پایهی یکسری فرضیات بنا شدهاند. بنابراین هنگام استفاده از آنها باید از صحت فرضیات اطمینان حاصل کنیم. برای مثال در آزمون کای-دو، بررسی فراوانیهای مورد انتظار اهمیت دارد. مقادیر واقعی با مقادیر مورد انتظار مقایسه میشوند و اختلاف میان آنها مبنای محاسبات آزمون است.
اگر این اختلافها کوچک باشند، فرض استقلال تقویت میشود. در این مثال نیز اختلافها کوچک بودند و نتیجهی آزمون اعتبار کافی داشت.
جمعبندی و نتیجهگیری
در این جلسه از کلاس، فرایند تحلیل اکتشافی دادهها (EDA) به مراحل پایانی رسید. در این مسیر توانستیم:
-
ارتباط میان متغیرهای عددی (مانند سدیم و پتاسیم) را بررسی کنیم.
-
ارتباط این متغیرها با داروی تجویزی را تحلیل نماییم.
-
ایدهی ایجاد ویژگیهای جدید (مانند نسبت سدیم به پتاسیم) را مطرح کنیم.
-
متغیرهای دیگری مانند کلسترول، فشار خون و جنسیت را در ارتباط با داروها بسنجیم.
-
از آزمونهای آماری (مانند کای-دو) برای تأیید یا رد فرضیات استفاده کنیم.
به این ترتیب، میتوان گفت مرحلهی EDA یا همان فاز Data Understanding بهخوبی پیش رفت و ما به شناخت مناسبی از دادهها رسیدیم.
هدف اصلی EDA تنها تحلیل و گزارشگیری نیست، بلکه ایجاد شناختی عمیق برای ورود به مرحلهی بعدی یعنی Data Preparation (آمادهسازی دادهها) است.
همچنین مجموعهای از ویدیوهای بعدی به مرور مباحث تئوری آمار و احتمال اختصاص مییابد تا درک عمیقتری از مفاهیم آماری داشته باشیم و بتوانیم آنها را در پروژههای عملی بهتر بهکار ببریم.