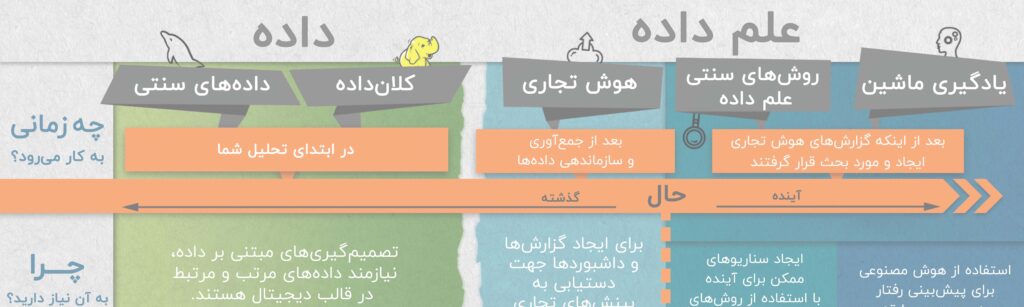
دانشمند داده یا تحلیلگر داده؟ تفاوتها را بشناسید
در دنیای امروز، دانشمند داده و تحلیلگر داده از جمله مشاغل کلیدی در حوزه دادهمحوری هستند، اما وظایف و مهارتهای آنها چه تفاوتهایی دارد؟ این اینفوگرافیک به شما کمک میکند تا نقش هر کدام را بهتر درک کنید.
دانشمند داده یا تحلیلگر داده؟ تفاوتها را بشناسید Read More »