
در این پست ابتدا خلاصه جلسه و سپس متن کامل جلسه آموزشی را مطالعه خواهید کرد:
خلاصهی جلسه:
1. هدف جلسه
- بررسی کیفیت دادهها با تمرکز بر نقاط پرت (Outliers).
- تحلیل بصری و آماری برای شناسایی روابط بین ویژگیها و متغیر هدف.
- گسترش تحلیل به ارتباط بین خود ویژگیها جهت جلوگیری از همخطی در مدلها.
2. شناسایی Outlierها (نقاط پرت)
- استفاده از روشهای ویژوال مانند:
- نمودار باکس (Boxplot)
- هیستوگرام (Histogram)
- نمودار پراکندگی (Scatter plot)
- استفاده از روشهای آماری مانند:
- تحلیل چارکها (IQR method)
- Z-Score
- ارائه کدهای نمونه توسط ChatGPT و اجرای آنها در Kaggle.
3. تفسیر نمودارهای باکس و هیستوگرام
- درک ساختار توزیع دادهها (مثلاً سن، سطح سدیم و پتاسیم).
- بررسی وجود یا عدم وجود مقادیر پرت در متغیرهای کمی.
- نتیجه: دادهها عمدتاً در محدودهی نرمال بوده و مشکلی از حیث Outlier ندارند.
4. تحلیل رابطه بین ویژگیها و متغیر هدف (Drug)
- استفاده از نمودارهای میلهای (Bar plot) برای متغیرهای کیفی مانند:
- جنسیت (Sex)
- فشار خون (BP)
- کلسترول (Cholesterol)
- استفاده از هیستوگرام برای مقایسه متغیرهای کمی با کلاسهای مختلف دارو:
- سن (Age)
- سدیم (Na)
- پتاسیم (K)
مشاهده شد که:
- فشار خون و سطح کلسترول رابطهی معنادار با نوع دارو دارند.
- جنسیت اثر معناداری روی نوع دارو ندارد.
- سن، سدیم و پتاسیم در برخی داروها توزیع خاص دارند، بنابراین تأثیرگذارند.
5. مفهوم Feature Selection و نقش ارتباطسنجی
- در صورتی که یک ویژگی با متغیر هدف ارتباط نداشته باشد، میتواند حذف شود.
- بررسی روابط به کمک نمودارها و آزمونهای آماری میتواند انتخاب ویژگی را بهینه کند.
6. تحلیل روابط بین ویژگیهای کمی (Input Features)
- استفاده از ماتریس همبستگی (Correlation Matrix) بین Age، Na و K.
- بررسی روابط آماری به کمک آزمونهای:
- Pearson Correlation
- Spearman Rank Correlation
نتیجه:
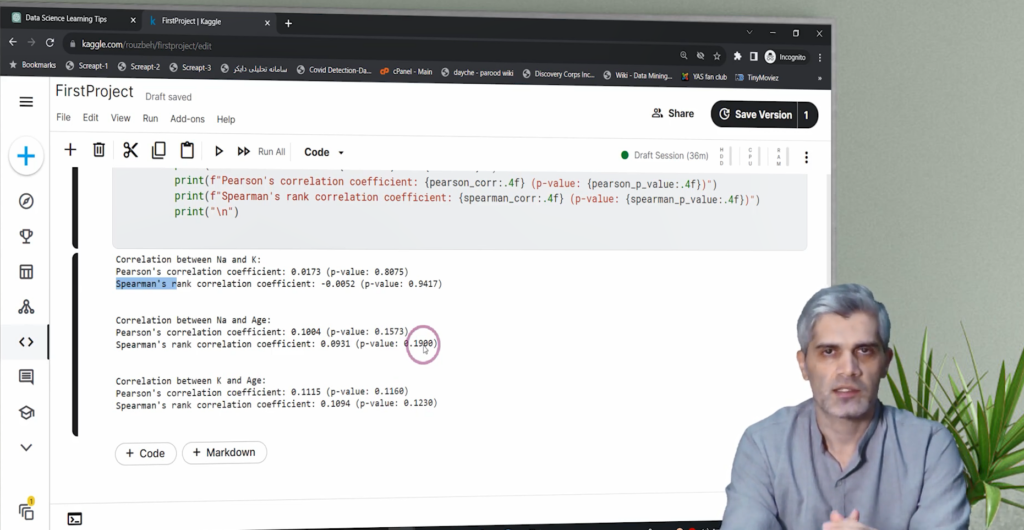
- بین Age، Na و K ارتباط خطی یا غیرخطی معنادار آماری وجود ندارد.
- پیولیوی (p-value) همهی روابط بالاتر از سطح معناداری (۰.۰۵) بود.
7. اهمیت استقلال ویژگیها در مدلسازی
- فرض مستقل بودن ورودیها در بسیاری از مدلهای آماری مهم است.
- همبستگی بین ویژگیها میتواند به کاهش دقت یا ناپایداری در مدلها منجر شود.
- در صورت وجود همبستگی، باید از روشهایی مانند:
- حذف برخی ویژگیها
- ترکیب ویژگیها (Feature Extraction)
استفاده کرد.
8. تمرین پایانی و معرفی نمودارهای Scatter
- معرفی نمودار Scatter برای نمایش رابطه دو متغیر کمی در یک فضای دوبعدی.
- توصیه به اجرای نمودار پراکندگی Na و K و تفسیر چشمی آن.
- پیشنهاد: اضافهکردن لایه رنگ به Scatter برای نمایش دستهی دارویی (Drug Class) بهعنوان تمرین.
9. نتیجهگیری
- با استفاده از ابزارهای آماری و بصری، توانستیم کیفیت داده را بسنجیم و ویژگیهای تأثیرگذار را شناسایی کنیم.
- گامهای بعدی: حرکت بهسمت پیشپردازش، انتخاب ویژگی و شروع مدلسازی.
متن کامل جلسه:
در این جلسه قصد داریم وارد مرحلهی تحلیل اکتشافی دادهها یا همان Exploratory Data Analysis (EDA) شویم. در این مرحله، تمرکز ما بر آن است که دادهها را از زوایای مختلف بررسی کنیم تا هم کیفیت آنها را ارزیابی کنیم و هم الگوهای مهمی را از دل آنها استخراج کنیم. یکی از اهداف کلیدی در این مرحله، شناسایی ویژگیهایی است که در پیشبینی متغیر هدف یعنی داروی تجویزشده نقش دارند.
ما تا اینجا دادهها را بارگذاری کردهایم، گزارش آماری اولیه را بررسی کردهایم، و اکنون نوبت آن است که تحلیل دقیقتری از روابط بین ستونها انجام دهیم.
بررسی نقاط پرت (Outliers)
نخستین موضوعی که بررسی میکنیم، وجود یا عدم وجود دادههای پرت یا Outlier در ویژگیهای عددی دادههای ماست. برای این منظور، از دو روش اصلی استفاده میکنیم: روشهای تصویری (ویژوال) و روشهای آماری.
در روش تصویری، از نمودارهایی مانند نمودار باکس (Boxplot)، هیستوگرام (Histogram) و نمودار پراکندگی (Scatter Plot) استفاده میشود. این نمودارها به ما کمک میکنند تا محدودهی توزیع دادهها را ببینیم و مقادیری که بهشکل غیرمعمول از بقیه فاصله دارند را شناسایی کنیم.
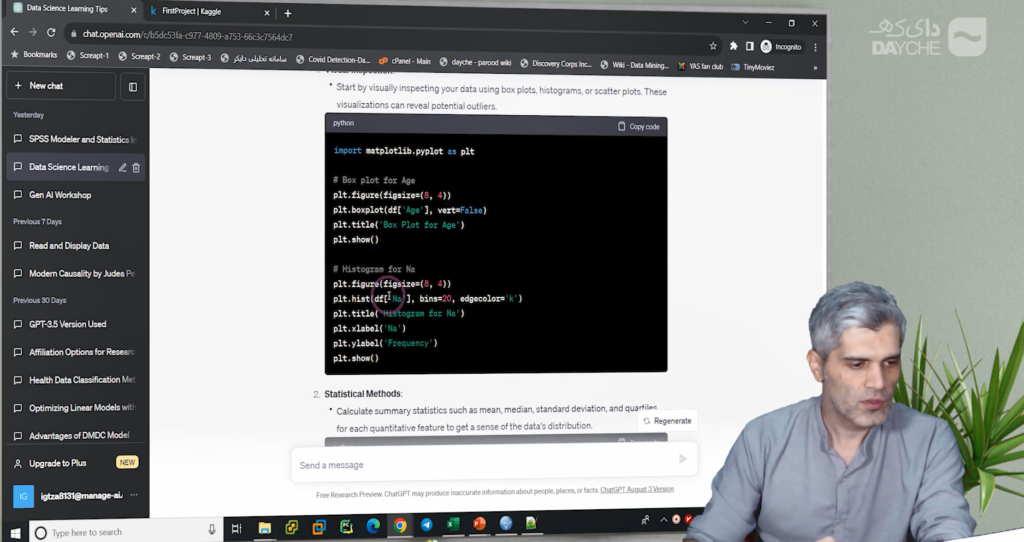
همچنین، در روش آماری میتوانیم از تکنیکهایی مانند Interquartile Range (IQR) و Z-Score استفاده کنیم. برای مثال، مقادیری که خارج از محدودهی [Q1 – 1.5×IQR, Q3 + 1.5×IQR] قرار دارند، معمولاً بهعنوان Outlier شناخته میشوند.
از ChatGPT میخواهیم برای ما کدی بنویسد که با استفاده از نمودارهای Boxplot و Histogram، وضعیت توزیع متغیرهایی مانند سن، سطح سدیم و سطح پتاسیم را نمایش دهد. پس از اجرای کد در محیط Kaggle، مشخص میشود که دادههای ما از نظر آماری در وضعیت نرمال و قابل قبولی قرار دارند و مورد مشکوکی از حیث دادههای پرت دیده نمیشود.
تحلیل رابطهی ویژگیها با متغیر هدف
در گام بعد، میخواهیم بررسی کنیم که هر یک از ویژگیها تا چه حد با متغیر هدف، یعنی داروی تجویزشده، ارتباط دارند. برای این کار، از نمودارهای مختلفی استفاده میکنیم.
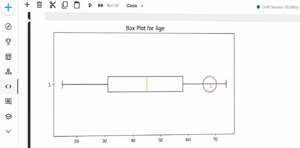
برای ویژگیهای کیفی مانند جنسیت، فشار خون و کلسترول، از نمودارهای ستونی یا Boxplot استفاده میکنیم. این نمودارها توزیع هر کلاس را نسبت به کلاسهای مختلف دارو نمایش میدهند.

برای ویژگیهای عددی مانند سن، سطح سدیم و پتاسیم، از نمودارهای Histogram استفاده میکنیم که توزیع این مقادیر را در بین گروههای مختلف دارو نشان میدهند.
نتایج بهدستآمده نشان میدهند که متغیرهایی نظیر فشار خون و کلسترول، تأثیر معناداری در تعیین نوع دارو دارند. بهعبارت دیگر، الگوی تجویز دارو بسته به دستهبندی این دو ویژگی متفاوت است. در مقابل، متغیر جنسیت ارتباط مشخصی با نوع دارو نشان نمیدهد و ممکن است در ادامه از مدل حذف شود.
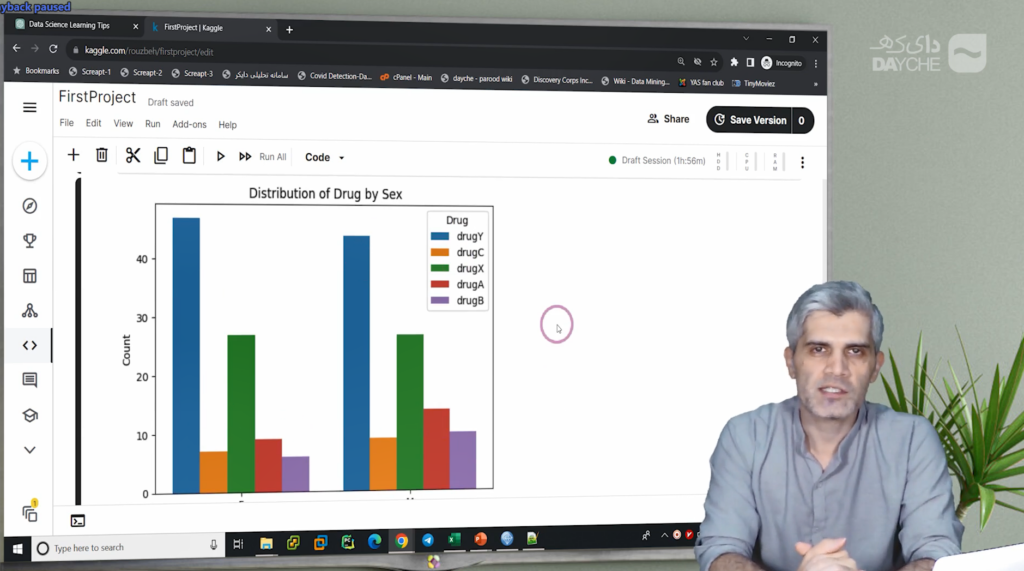
در خصوص سن، سطح سدیم و پتاسیم، مشاهده میشود که توزیع این ویژگیها در گروههای مختلف دارو متفاوت است. بنابراین، میتوان گفت که این سه ویژگی نیز در پیشبینی داروی تجویزشده نقش دارند.
مفهوم انتخاب ویژگی و ارتباط سنجی
در اینجا، مفهوم Feature Selection یا انتخاب ویژگی مطرح میشود. در صورتیکه یک ویژگی با متغیر هدف ارتباط آماری نداشته باشد، حذف آن نهتنها خللی در عملکرد مدل ایجاد نمیکند، بلکه میتواند به سادگی، سرعت و پایداری مدل کمک کند. بنابراین، تحلیلهایی که در این جلسه انجام میدهیم، مستقیماً در تصمیمگیری برای نگهداشتن یا حذف ویژگیها اثرگذار خواهند بود.
تحلیل روابط بین ویژگیهای عددی
اکنون تمرکز خود را بر روی رابطهی میان خود ویژگیها میگذاریم. این بررسی بهمنظور تشخیص همخطی (Multicollinearity) بین ویژگیها انجام میشود، چرا که در بسیاری از مدلهای یادگیری ماشین و آمار کلاسیک، فرض بر این است که ویژگیهای ورودی مستقل از یکدیگر هستند.
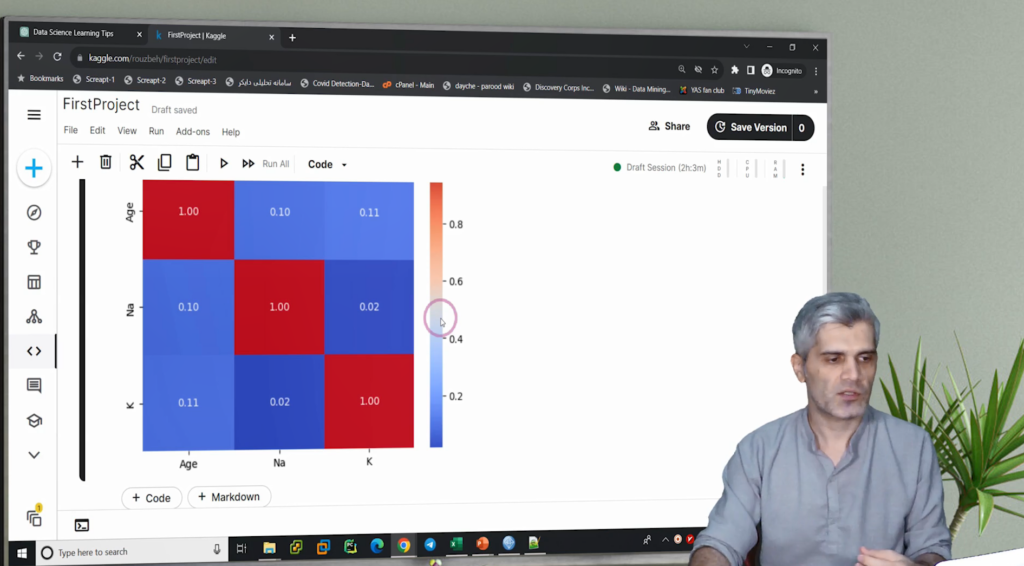
برای این منظور، از ماتریس همبستگی یا Correlation Matrix استفاده میکنیم. در این تحلیل، تنها سه ویژگی عددی داریم: سن، سدیم و پتاسیم. بنابراین، باید رابطهی میان این سه متغیر بررسی شود.
از ChatGPT میخواهیم تا کدی بنویسد که همبستگی بین این متغیرها را با استفاده از آزمونهای Pearson و Spearman محاسبه کند. همچنین، مقدار p-value برای هر رابطه محاسبه میشود تا مشخص شود که رابطه از نظر آماری معنادار هست یا خیر.
نتایج نشان میدهند که هیچ رابطهی معنادار آماری بین این متغیرها وجود ندارد. مقادیر p-value بالاتر از ۰.۰۵ هستند که یعنی نمیتوان ارتباط خطی یا غیرخطی بین این ویژگیها را تأیید کرد. این موضوع مطلوب است، چرا که نشان میدهد متغیرهای ورودی مدل از نظر آماری مستقل هستند و میتوان آنها را بهصورت همزمان در مدلسازی استفاده کرد.
اهمیت استقلال ویژگیها در مدلسازی
در این بخش یادآور میشویم که وجود همبستگی بالا بین ویژگیهای ورودی میتواند منجر به بروز مشکلاتی در مدلسازی شود، بهخصوص در مدلهای خطی مانند رگرسیون. این مسئله باعث ناپایداری ضرایب، کاهش دقت پیشبینی و سختتر شدن تفسیر مدل خواهد شد.
اگر در آینده با همبستگی بالا بین ویژگیها مواجه شویم، باید از روشهایی نظیر حذف یکی از ویژگیها یا استفاده از تکنیکهای استخراج ویژگی (مانند PCA) استفاده کنیم.
تمرین تکمیلی و معرفی نمودار پراکندگی
در انتهای جلسه، بهعنوان تمرین، از فراگیر خواسته میشود که از نمودار پراکندگی یا Scatter Plot برای بررسی رابطهی بین دو متغیر عددی سدیم و پتاسیم استفاده کند. این نمودار، دید مناسبی از الگوی توزیع این دو متغیر فراهم میآورد.
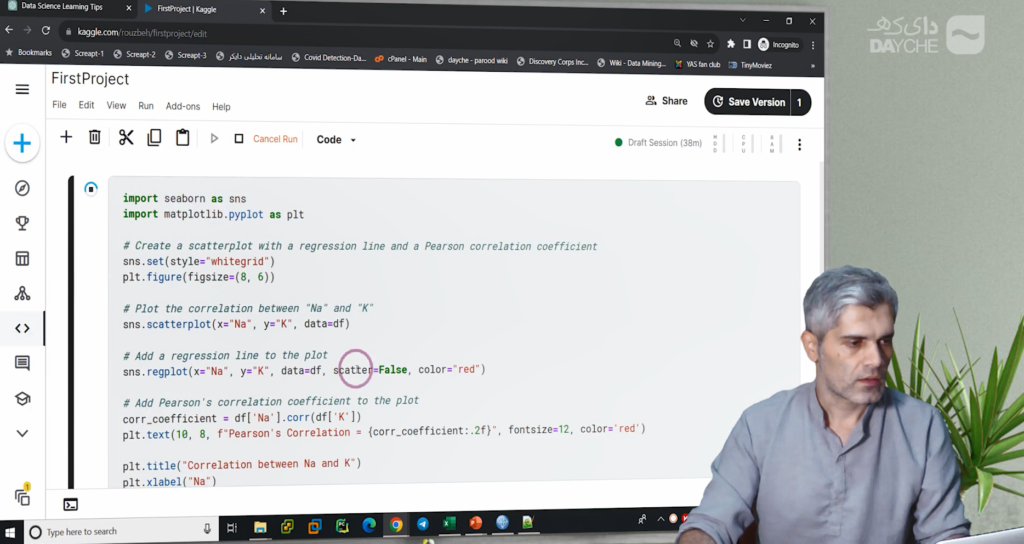
همچنین پیشنهاد میشود که رنگ نقاط داده در این نمودار بر اساس نوع دارو تعیین شود. این کار به تحلیل بصری ارتباط بین ویژگیها و متغیر هدف کمک میکند و زمینهی درک بهتر از تفکیکپذیری کلاسها را فراهم میسازد.
جمعبندی
در این جلسه با استفاده از ابزارهای آماری و بصری، دادهها را از نظر وجود نقاط پرت بررسی کردیم، روابط بین ویژگیها و متغیر هدف را تحلیل کردیم، و از وجود یا عدم وجود همخطی بین ویژگیها آگاه شدیم.
این تحلیلها نهتنها در درک بهتر دادهها مفید هستند، بلکه در آمادهسازی دادهها برای مدلسازی نیز نقش کلیدی ایفا میکنند. در جلسهی آینده، بهسمت پیشپردازش (Preprocessing) دادهها و انتخاب نهایی ویژگیها حرکت خواهیم کرد.