پس از برآورد ضرایب و ساخت مدل رگرسیونی، آزمون های فرض آماری جهت بررسی معناداری برازش مدل خطی و جزئیات بدست آمده بکار می رود. این آزمون ها در دو سطح معناداری مدل را مورد بررسی قرار می دهد:
معناداری برازش مدل خطی بر اساس جدول تحلیل واریانس ANOVA
معناداری ضرایب مدل خطی بر اساس آزمون t ضرایب برآورد شده
معناداری برازش مدل خطی
بر اساس جدول تحلیل واریانس ANOVA، پراکندگی (واریانس) مقادیر فیلد هدف به دو بخش تجزیه می شود. بخشی از پراکندگی که توسط مدل رگرسیونی توضیح داده می شود و بخش دیگر از آن که به عنوان جمله خطا در نظر گرفته می شود.
بدیهی است هر چقدر سهم SSR از مجموع مربعات کل داده ها (SST) بیشتر باشد، می توان نتیجه گرفت مدل بهتری خواهیم داشت.

● ساخت جدول تحلیل واریانس
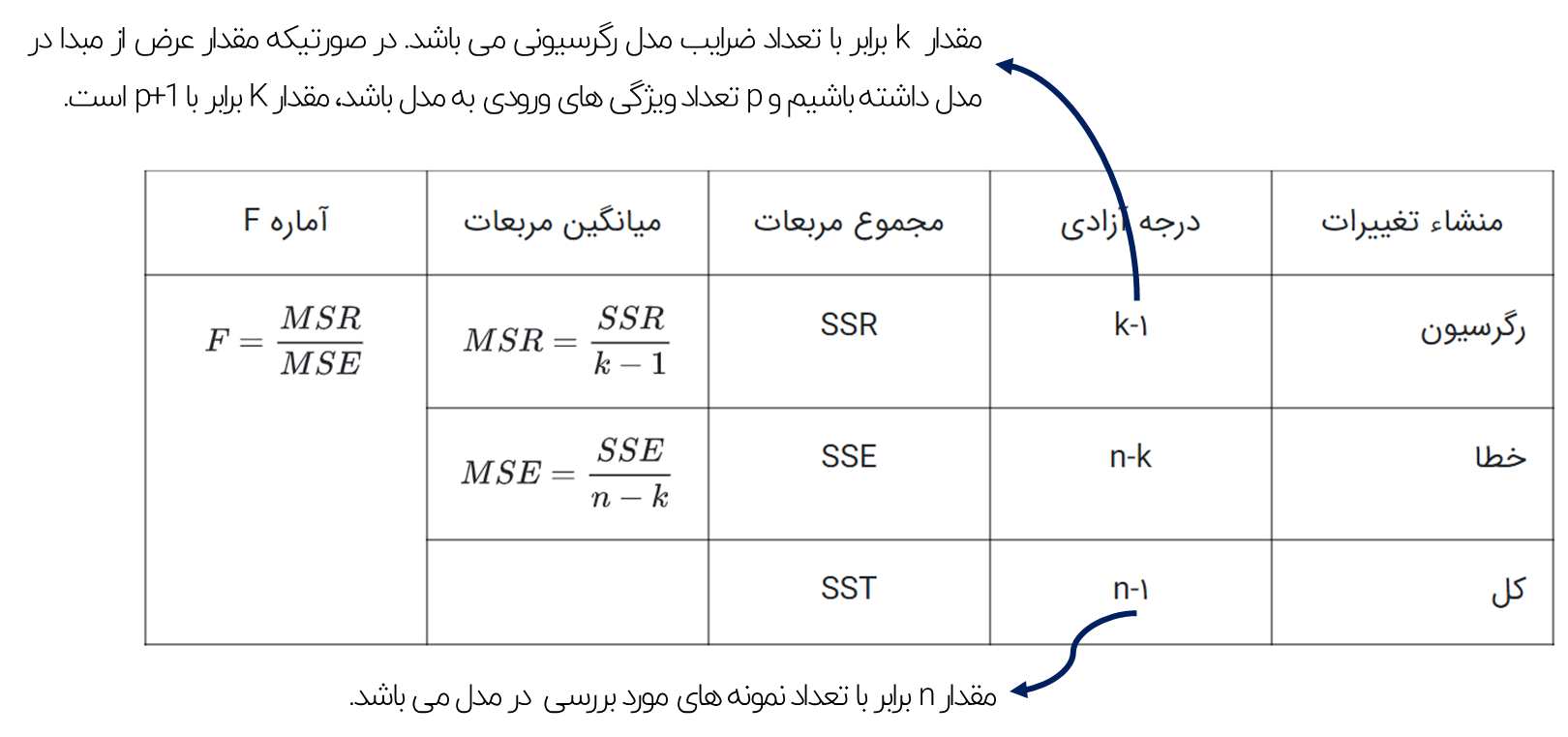
● درجه آزادی Degree of Freedom:
مفهوم درجه آزادی به منابع پراکندگی مرتبط است. هر چقدر میزان درجه آزادی بیشتر باشد، انعطاف بیشتری در پراکندگی توزیع داده ها خواهیم داشت.
فرض کنید از شما خواسته شده تا 3 عدد دلخواه انتخاب کنید، بنابراین شما 3 درجه آزادی خواهید داشت تا هر عدد دلخواهی را برای این چالش در نظر بگیرید.
حال اگر از شما بخواهند 3 عدد دلخواه انتخاب کنید به طوری که میانگین آنها برابر با مقدار فرضی 50 شود، آنگاه تنها دو درجه آزادی برای انتخاب دو عدد دلخواه خواهید داشت و عدد سوم بایستی مقداری در نظر گرفته شود که برابری مقدار میانگین با عدد 50 تضمین شود.
به طور کلی، به ازای برآورد هر پارامتر از مجموعه داده ها، یک واحد از درجه آزادی خطا کم می شود.

● ضریب تعیین : Coefficient of Determination
ضریب تعیین یا ضریب تشخیص Coefficient Of Determination قدرت توضیح دهندگی مدل را نشان میدهد. ضریب تعیین نشان میدهد که چند درصد از تغییرات متغیر وابسته توسط متغیرهای مستقل توضیح داده میشود.
تغییرات کل متغیر وابسته برابر است با تغییرات توضیح داده شده توسط رگرسیون بعلاوه تغییرات توضیح داده نشده. این شاخص یکی از شاخصهای برازش مدل است که قدرت پیشبینی متغیر وابسته (ملاک) براساس متغیرهای مستقل (پیشبین) را نشان میدهد.
مقدار این شاخص بین صفر تا یک میباشد و اگر از ۰/۶ بیشتر باشد نشان میدهد متغیرهای مستقل تا حد زیادی توانستهاند تغییرات متغیر وابسته را تبیین کنند.
یکی از شاخص های مهم و پرکاربرد در تحلیل مدلهای رگرسیونی مقدار ضریب تعیین می باشد که نسبتی از پراکندگی کل فیلد هدف است که توسط مدل رگرسیونی توضیح داده می شود. در واقع این شاخص قدرت برازش مدل رگرسیون روی داده ها را اندازه گیری می کند.

فرض کنید مقدار برای یک مدل 0.87 بدست آمده است. به این معنی می باشد که 87% از تغییرات فیلد هدف توسط مدل رگرسیونی کنترل و توضیح داده می شود که نشان دهنده میزان اثر بخشی ویژگی های ورودی به مدل می باشد.
● ضریب تعیین تعدیل شده
ضعف مهم شاخص اینست که با افزایش تعداد ویژگی های ورودی به مدل، به صورت کاذب افزایش می یابد. بنابراین با تعدیل آن نسبت به تعداد ویژگی های ورودی به مدل، مقدار مطمئن تری برای اندازه گیری قدرت برازش مدل خواهیم داشت.
مقدار K برابر با تعداد پارامترهای برآورد شده مدل می باشد که برابر با تعداد ویژگی های ورودی به مدل (p) و پارامتر عرض از مبدا است.


معناداری ضرایب مدل خطی
ضرایب مدل رگرسیونی برآورد شده دارای توزیع نرمال با میانگین مجهول می باشند. بنابراین از طریق آزمون میانگین می توان فرض صفر بودن آنها را مورد بررسی قرار داد. با استفاده از آزمون t اینکار انجام می شود.
در صورتیکه دلیلی بر رد فرض صفر بودن وجود نداشته باشد، می توان نتیجه گرفت ویژگی مربوط به آن ضریب دارای ارتباط معنادار خطی در مدل نمی باشد و با حذف آن مجددا مدلسازی شود.
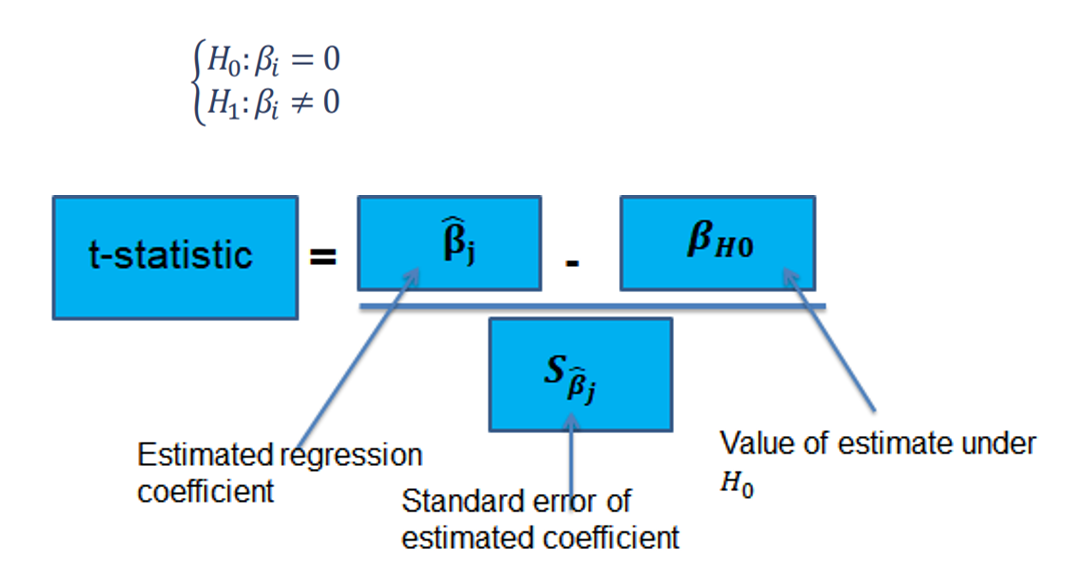
در صورت معنادار بودن ضریب رگرسیونی، بر اساس مثبت یا منفی بودن آن می توان به نوع ارتباط مستقیم یا معکوس آن با فیلد هدف پی برد. همچنین اندازه ضریب نشان دهنده این می باشد، به ازای هر انحراف معیار تغییر در ویژگی مربوطه، به میزان ضریب بدست آمده در انحراف معیار فیلد هدف، مقدار فیلد هدف افزایش یا کاهش می یابد.

مثال از خروجی آزمون های فرض مدل رگرسیونی