یکی از رایج ترین مراحل آماده سازی داده ها، ساخت ویژگی های جدید و اثربخش برای ورود به مدل ها می باشد. این مرحله به عنوان فرآیند شاخص سازی با اهداف مختلفی همچون تفسیرپذیری، تعمیم پذیری، افزایش کارایی مدل ها و … در داده های خام انجام می شود که شامل رویکردهای زیر می باشد:
استفاده از دانش زمینه ای
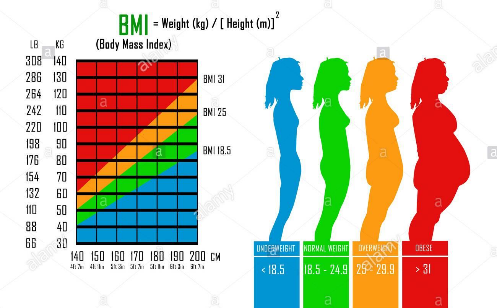
استفاده از دانش زمینه ای در خصوص رابطه متقابل بین ویژگی ها و یا ارتباط آنها با فیلد هدف می تواند ایده هایی مبنی بر ترکیب ویژگی های اولیه و ساخت ویژگی های جدید بیان کند به عنوان مثال با داشتن ویژگی های وزن و قد در بررسی عوامل موثر بر کنترل دیابت، میتوان شاخص توده بدنی (BMI) را جایگزین ویژگی های اولیه نمود با این کار می توان به ساده سازی دیتا ها کمک نمود و دو متغیر را به یک متغیر تبدیل نمود.
مثال دوم: ساخت شاخص درآمد با تقسیم درآمد بر میزان حداقل دستمزد سالانه جهت تفسیرپذیری و تعمیم پذیری الگوهای به دست آمده
مثال سوم: ساخت سلسله مراتب مفهومی از ویژگی های اسمی مانند تبدیل شهر به استان، تبدیل شغل به گروه های شغلی و … .
استفاده از روابط آماری
ممکن است دانشی را به وسیله روابط آماری و کشف روابط بین داده ها بدست آورده باشیم. در این حالت به دو شکل اقدام به ساخت ویژگی های جدید می شود:
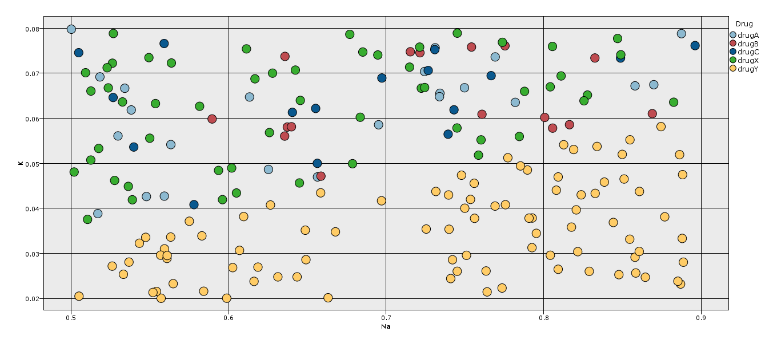
حالت اول: استفاده از دانش به دست آمده برای ساخت ویژگی جدید. بطور مثال، تقسیم سدیم به پتاسیم برای پیشبینی نوع دارو براساس رابطه شناسایی شده در نمودار پراکنش
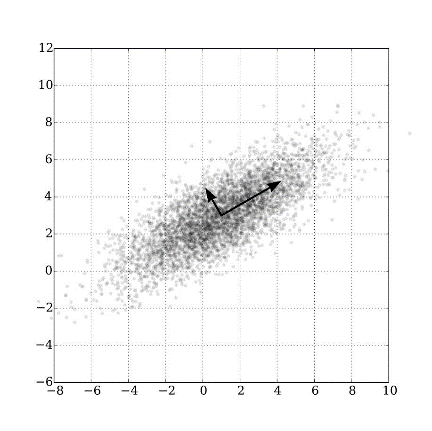
حالت دوم: استفاده از الگوریتم های آماری مانند PCA یا SVD. به طور مثال، ساخت یک مولفه از ترکیب خطی ویژگی ها براساس ساختار واریانس کوواریانس بین داده ها.
 کد گذاری مقادیر فیلد های اسمی
کد گذاری مقادیر فیلد های اسمی
بسیاری از الگوریتم های یادگیری ماشین و روش های آماری نیاز به داده های عددی دارند. بنابراین یکی از اقدامات لازم در آماده سازی داده ها کدگذاری مقادیر ویژگی های اسمی می باشد. برخی از روش های رایج کدگذاری موارد زیر است.
- One-hot encoding
- Ordinal or label encoding
- Ordered label encoding
- Probability ratio encoding
- Rare labels encoding
روش One-Hot Encoding
روش کدبندی One-Hot، یکی از پرکاربردترین رویکردها است و عملکرد آن به جز در مواردی که متغیر دستهای مقادیر خیلی زیادی بگیرد، بسیار خوب است (معمولا از این روش برای متغیرهایی که بیشتر از ۱۵ مقدار متفاوت بگیرند، مناسب نیست.
در برخی از مواردی که تعداد متغیرها کمتر است نیز امکان دارد گزینه مناسبی نباشد). کدبندی One-Hot ستونهای دودویی (binary) جدیدی میسازد که هر یک مربوط به یکی از مقادیری هستند که متغیر به خود میگیرد. برای درک بهتر موضوع، مثالی در ادامه ارائه شده است.
فرض میشود که یک متغیر با عنوان Color در مجموعه داده وجود دارد که مقادیر آن Red ،Yellow و Green هستند. اکنون، کلیه مقادیر این متغیر به سه ستون جدا با عنوانهایYellow ،Red و Green تبدیل میشوند.
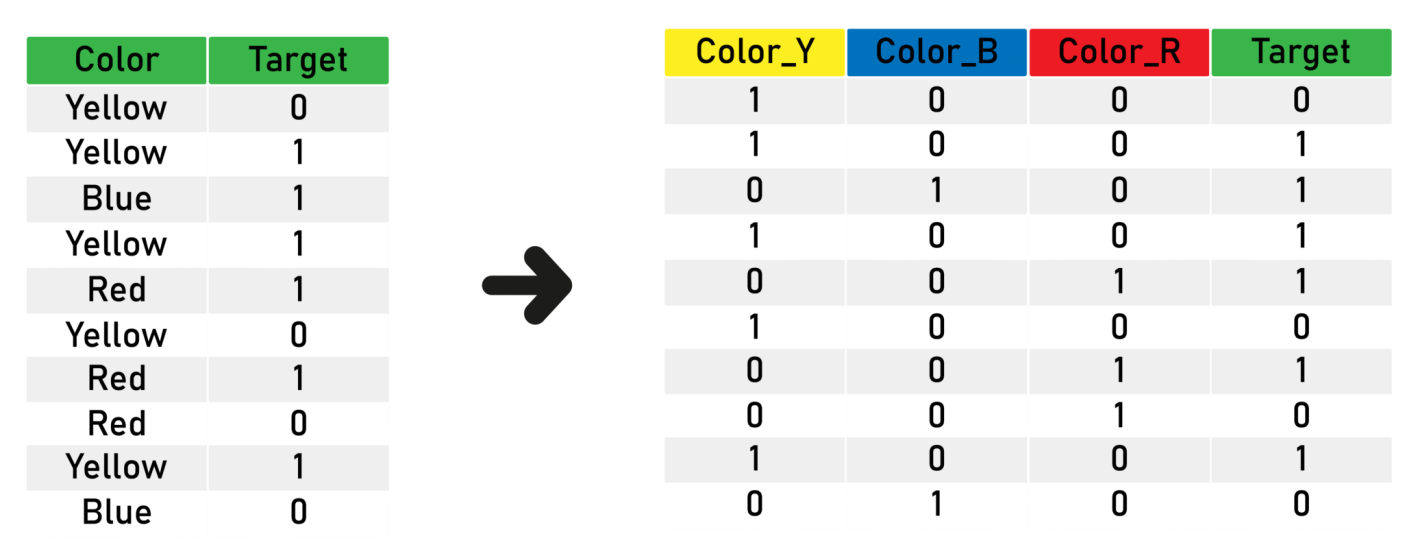
در این روش که با آن Dummy Variable نیز گفته می شود به ازای هر سطح برای متغییر اسمی یک فیلد را اختصاص می دهیم، در این روش به تعداد حالت های فیلد اسمی فیلد خواهیم داشت، این روش با استفاده از ایجاد K ستون انجام می شود و یا K-1 (زیرا با دانستن تعداد K-1 وضعیت می توان وضعیت فیلد آخر را حدس زد)
- وقتی که تعداد داده ها نسبتا کمتر است ( برای پردازش سریعتر)
- وقتی رابطه ای بین متغیرها وجود ندارد و متغیرهای اسمی(بطور مثال جنسیت، اسم ) هستند.
معایب این روش:
- در صورت داده های زیاد باعث سرعت کم در پردازش میشه.
- همخطی چندگانه (Multicollinearity)

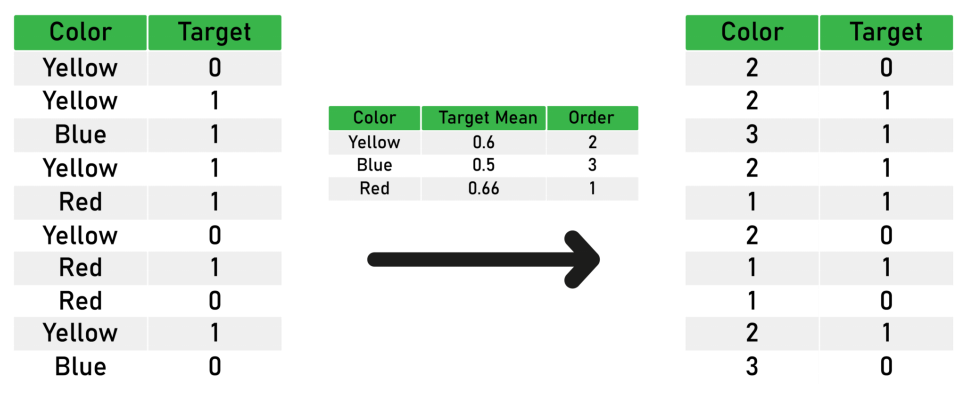
روش Ordinal or label encoding
در این روش به هر حالت از فیلد مورد نظر یک عدد تخصیص داده می شود، از مزایای این روش عدم تعدد ستون ها یا فیلد ها است و ضعف آن این است که ترتیب اعداد منطق خاصی ندارد و اعداد نمی توانند مورد محاسبات قرار گیرند. مهمترین کاربرد این روش، در مدل های بر مبنای درخت است و اعداد می توانند بیانگر کلاس ها باشند.
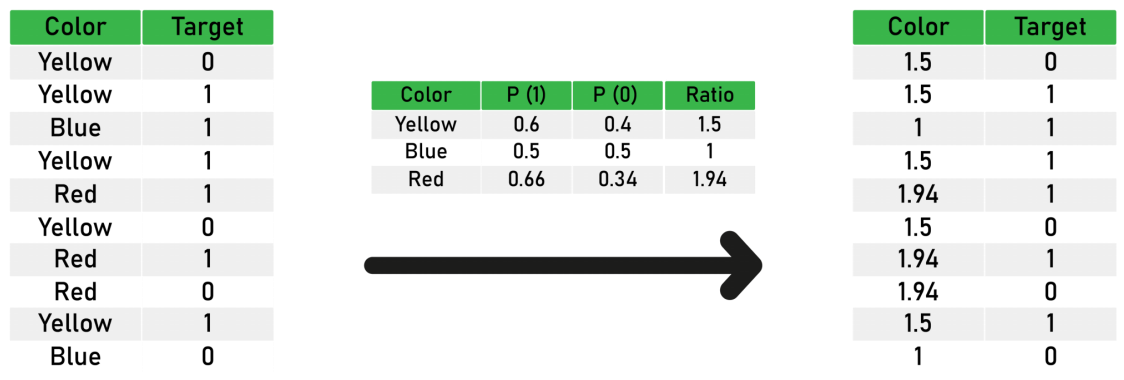
روش Probability ratio encoding
این روش که روش تکمیل شده تری از روش قبل است و ضعف روش قبل که در زمانی که میانگین پراکندگی بین حالت ها اعداد نزدیک هستند می تواند با دقت کمتری عمل نماید. در این روش بر اساس اطلاعات احتمالاتی، احتمال وقوع و عدم وقوع هر کدام در نظر گرفته می شود و فیلد Ratio نسبت بین این احتمالات را بیان می کند. با این حال در این روش در حالتی که این نسبت ها برای دو حالت یکسان باشند ضعف ادغام وجود دارد.
در این حالت اگر همه اعداد یک باشند و احتمال عدم وقوع که صفر می شود در مخرج نسبت قرار میگیرد بنابراین این حالت در الگوریتم مد نظر قرار نمی گیرد که ضعف بزرگی خواهد بود.
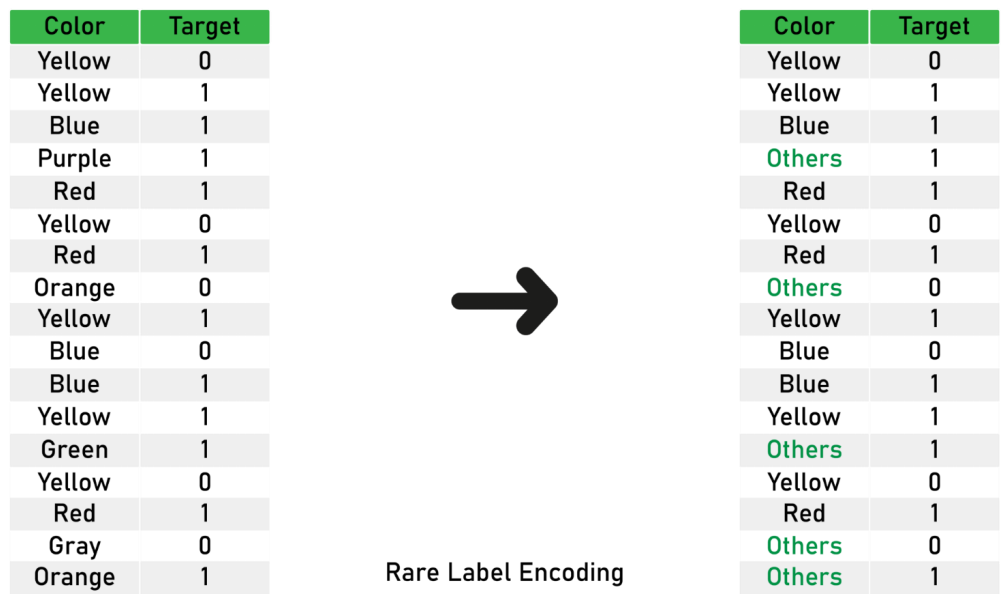
روش Rare labels encoding
در مواقعی که برخی از حالات یک فیلد فراوانی کمی داشته باشند و عملا نادر باشند می توان رده های این چنین را که فراوانی آنها (به عنوان مثال) زیر 1 تا 5 درصد است در گروه دیگری به نام سایر یا Others قرارداد مزیت این روش در این است که در الگوریتم ها موارد نادر می توانند در نظر گرفته نشوند ولی در حالت تجمع این موارد باعث افزایش میزان این نرخ می شود.