دانش داده کاوی فرآیند کشف دانش پنهان درون داده های انبوه می باشد که این مهم توسط الگوریتم ها و نرم افزارهای داده کاوی انجام می پذیرد. در این میان نرم افزار داده کاوی کلمنتاین (IBM SPSS Modeler) یکی از نرم افزارهای برتر داده کاوی از شرکت IBM می باشد که به صورت گسترده ای در پروژه های داده کاوی کاربرد دارد. به وسیله امکانات و الگوریتم هایی که کلمنتاین در اختیار کاربران قرار می دهد مدل سازی و انجام امور داده کاوی به بهترین شکل انجام می گیرد.
نرم افزار کلمنتاین به دلیل کاربرپسند بودن آن و همچنین سهولت استفاده و صرف وقت کم از کاربران، دارای محبوبیت خاصی بوده و نتایج ارزشمندی ایجاد می نماید. این نرم افزار، فرآیند انجام داده کاوی در محیط کسب و کار را بر اساس استاندارد CRISP DM از ابتدا تا انتها پشتیبانی نموده و زمان آماده سازی داده و تحلیل های داده کاوی را نسبت به سایر نرم افزارها کاهش می دهد.
در این بخش از آموزش مباحث داده کاوی به کار با این نرم افزار و آموزش قابلیت های آن می پردازیم. نسخه مورد استفاده در این آموزش نسخه 18 می باشد.
در این ویدیو به صورت اجمالی به معرفی نرم افزار SPSS Modeler می پردازیم و با یک دیتاست که مربوط به داده های وضعیت کلسترول، سدیم و پتاسیم خون بیماران است و نوع دارویی که به عنوان نتایج هدف مشخص شده اند در قالب حل مسئله به معرفی نرم افزار، قابلیت ها و کاربرد های آن می پردازیم.
همچنین در این بخش به عنوان نمونه ای از کاربرد توصیف و کاوش در داده ها، دیتا را مدل می نماییم و میبینیم که چطور می توان از آن برای حل مسائل داده کاوی استفاده نمود.
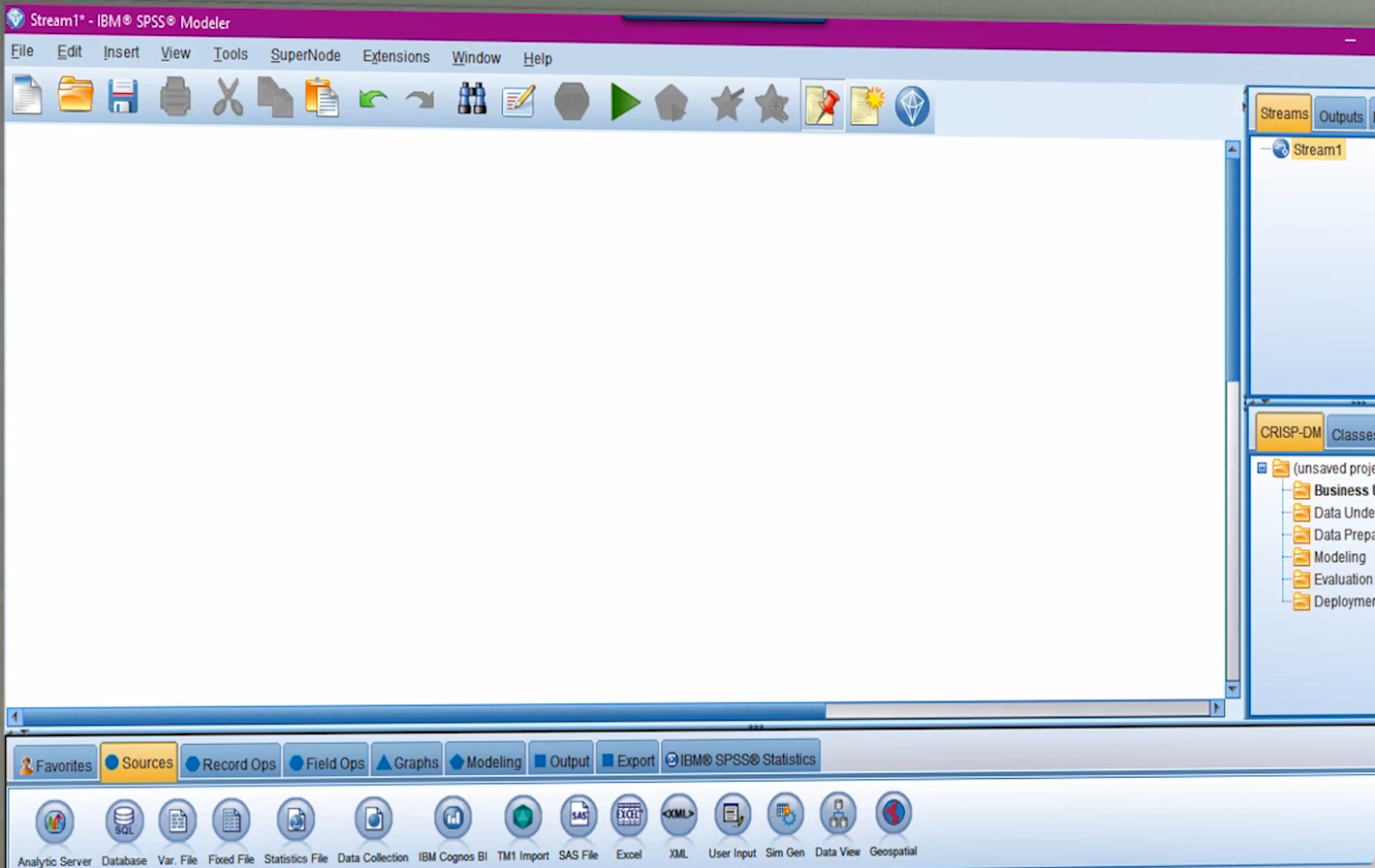
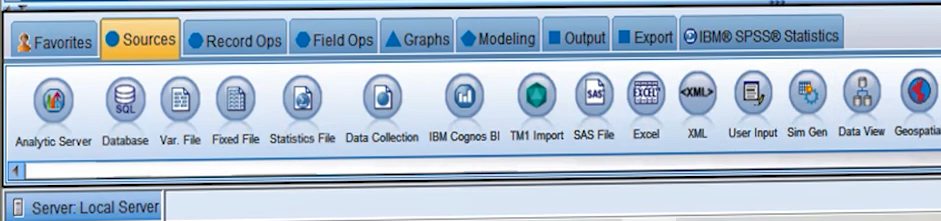
در این نرم افزار همه کارهایی که ما انجام می دهیم توسط Node ها انجام میشوند. همه Node های مربوط به ورود دیتا به این نرم افزار در یه Pallet به نام Sources قرار دارند. یعنی مثلا یک Node برای ورود فایل های اکسل، یکی برای دیتابیس ها و … وجود دارد.
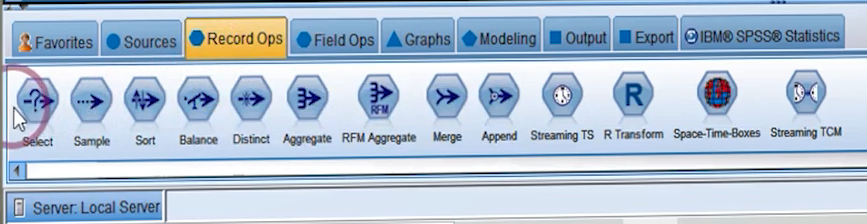
در Pallet بعدی با نام Record Ops ما Node هایی را داریم که عملیات سطری را انجام می دهند یعنی همه عملیات لازم در سطر داده ها، مشاهدات و ثبت ها را با این ها انجام می دهیم.
در Pallet بعدی با نام Fields Ops ما Node هایی را داریم که عملیات ستونی را انجام می دهند یعنی همه عملیات لازم در ستون های داده ها، مشاهدات و ثبت ها را با این ها انجام می دهیم.

همه گراف ها در پلت Graphs قرار دارند.
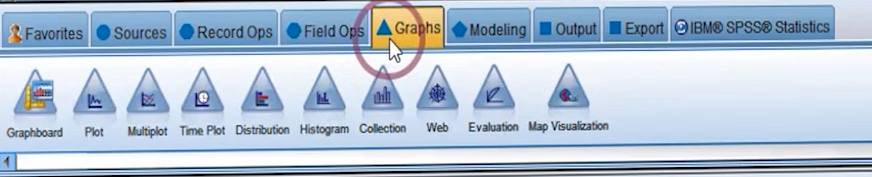
در پلت Modeling نودهایی را داریم که با استفاده از آنها مدل هایمان را Run می کنیم. در سمت چپ می بینیم که این نودها دسته بندی شده اند و دسترسی ما را آسانتر می کند.
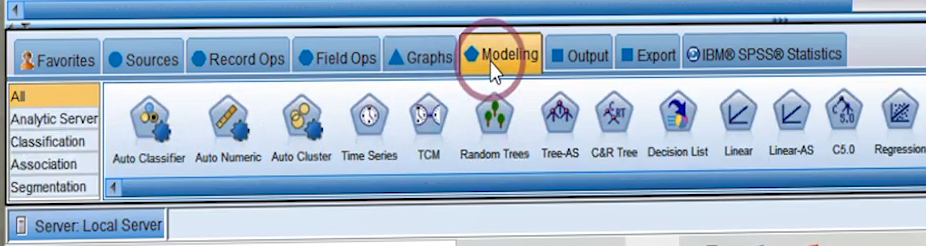
تمامی خروجی های، گزارش ها و توصیف های حاصل از داده ها که لازم داریم در پلت output قراردارند.
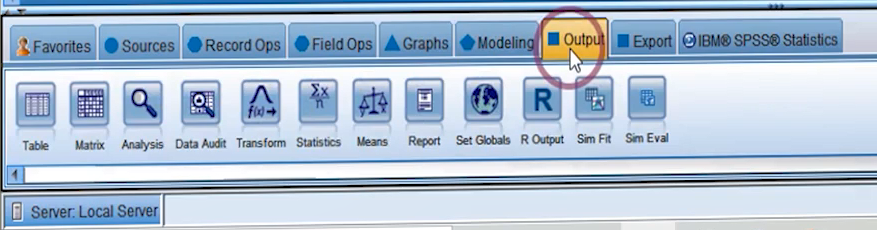
عملکرد پلت Export در مقابل پلت Sources قرار دارد یعنی در این قسمت همه نودهایی قرار دارند که می توانند با فرمت های مختلفی می توانیم از دیتاها خروجی بگیریم.
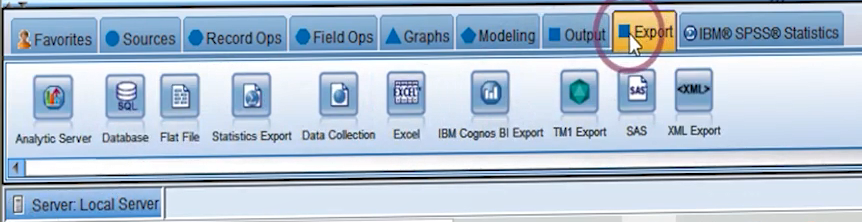
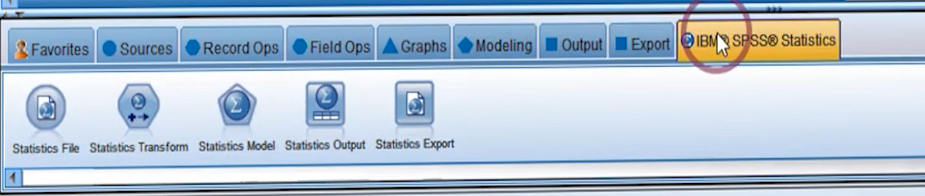
پلت آخر شامل نودهایی است که با استفاده از آنها می توانیم از قابلیت های SPSS Statistics استفاده کنیم.
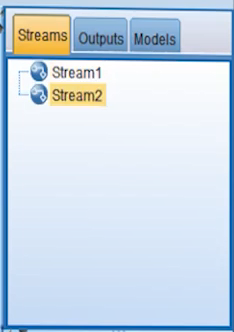
در قسمت بالا سمت راست حافظه کوتاه مدت نرم افزار را داریم که تا زمانی که برنامه بسته نشده است می توانیم از این هیستوری استفاده کنیم و بین استریم های مختلفی که در حال اجرا هستند جابجا شویم. اگر از دیتایی خروجی گرفتیم، جدولی را Run کرده ایم یا آزمون فرضی را انجام داده ایم می توانیم تاریخچه آنها را در بخش Outputs در همین قسمت از صفحه ببینیم. نکته مهم این است که همه این ها تا قبل از بسته شدن برنامه قابل دسترسی است.
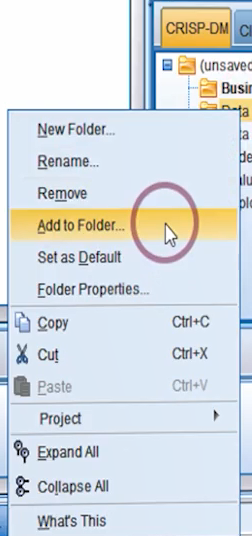
در بخش پایین سمت راست صفحه بخشی را برای مدیریت فایل های مرتبط با پروژه داریم که طبق فازهای CRISP-DM می توانیم مراحل پروژه را پیش ببریم و و تمام فایل های مربوطه را یکجا داشته باشیم. برای اضافه کردن فایل به هرکدام از این مراحل، کافیست روی آن کلیک راست کنیم و Add to folder را بزنیم و فایل دلخواه را اضافه کنیم. دقت کنید که صرفا shortcut فایل ها اینجا اضافه میشود بنابراین اگر مسیر فایلی عوض شد لازم است که در برنامه نیز اصلاح شود.
بر اساس نوع خروجی هم این دسته بندی ها انجام شده و در کنار گزینه قبلی قابل دسترسی است.