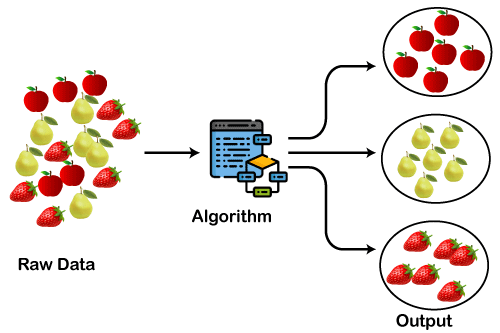
هدف خوشه بندی ایجاد گروه هایی از داده هاست که اعضای درون هر گروه دارای بیشترین شباهت (کمترین پراکندگی) و اعضای بین گروه ها دارای کمترین شباهت (بیشترین پراکندگی) باشند.
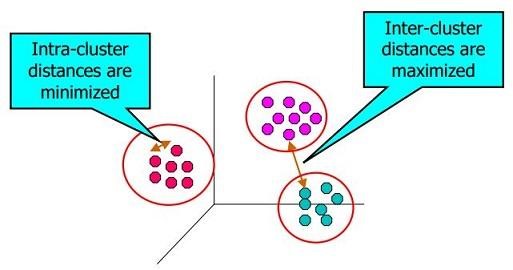
بنابراین اندازه گیری کارایی مدل های خوشه بندی را می توان بر اساس همین هدف به دست آورد. در واقع اغلب معیارهای ارزیابی خوشه بندی بر اساس دو فاکتور انسجام خوشه ای (Cohesion) و جدایی خوشه ای (Separation) تعریف می گردد که معمولا به آنها معیارهای داخلی می گویند.
معیار مجموع مربعات درون خوشه ای (WSS)
این شاخص همان تابع زیان الگوریتم K-Means است (SSE) و با کمینه کردن آن، خوشه ها شناسایی می شود.
ویژگی بسیار جالب این معیار این است که علاوه بر سادگی و سرعت بالای محاسبه، در ذات خود فاکتورهای انسجام خوشه ای و جدایی خوشه ای را به صورت همزمان داراست.
از آنجا که مقدار واریانس کل برای هر مجموعه داده مقدار ثابتی است، بنابراین کمینه کردن فاکتور انسجام خوشه ای WSS به معنی بیشینه کردن فاکتور جدایی خوشه ای BSS می باشد.

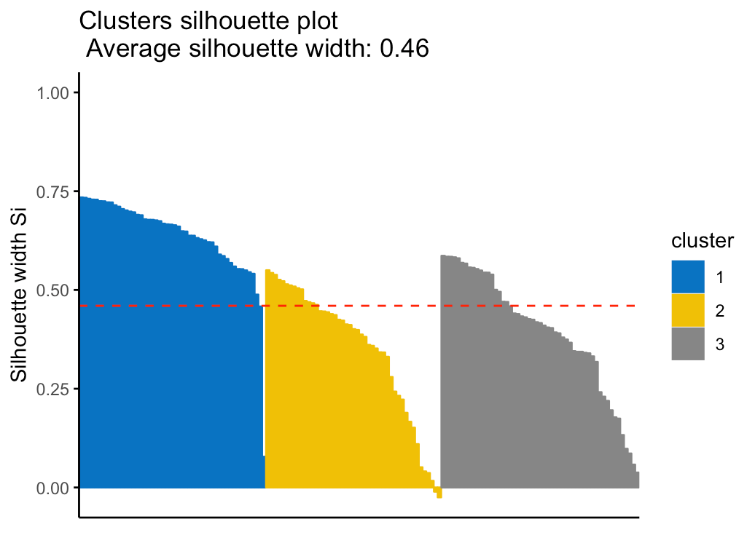
معیار نیم رخ (Silhouette)
این معیار میزان تعلق هر رکورد به خوشه ای که در آن قرار گرفته، در مقایسه با خوشه مجاور را اندازه گیری می کند.
محاسبه معیار سیلوئت برای هر رکورد انجام می شود:
a: میانگین فاصله هر رکورد از تمامی رکوردهای هم خوشه
b: میانگین فاصله هر رکورد از تمامی رکوردهای نزدیکترین خوشه مجاور

دامنه معیار سیلوئت در بازه 1- تا 1 قرار می گیرد. مقادیر مثبت و نزدیک به مقدار یک به معنی خوشه بندی درست و با کیفیت خوب است. همچنین منفی بودن این معیار نیز به معنی نادرست بودن خوشه بندی می باشد.
از مزایای این معیار می توان گفت، قابلیت ارزیابی کلی مدل، ارزیابی هر خوشه مجزا و همچنین ارزیابی هر رکورد را فراهم می سازد.
در ارزیابی کلی مدل خوشه بندی مناسب معمولا میانگین معیار سیلوئت بایستی بالاتر از 0.2 در نظر گرفته شود.
به علت نیاز به محاسبه فاصله بین تمام جفت رکوردها، سرعت محاسبه این معیار کند بوده و معمولا در مجموعه داده های بزرگ استفاده نمی شود.
معیار دان (Dunn Index)
این شاخص نیز مانند سایر شاخص های معرفی شده، از ترکیب فاکتورهای انسجام خوشه ای و جدایی خوشه ای استفاده می کند.
محاسبه معیار دان:
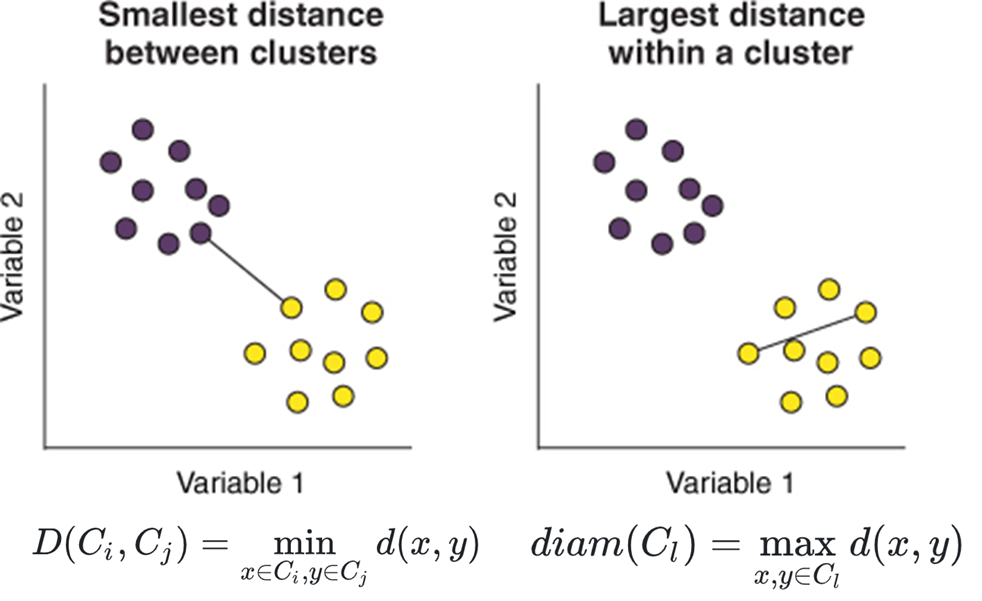
جدایی خوشه ای: کوچکترین فاصله بین اعضای دو خوشه
انسجام خوشه ای: بزرگترین فاصله بین اعضای یک خوشه (قطر خوشه)
شاخص دان با نسبت کمترین فاصله بین خوشه ها به بیشترین میزان قطر خوشه محاسبه می شود.
مقدار شاخص دان در بازه صفر تا بی نهایت هست که بزرگ بودن آن به معنای تفکیک پذیری و در نتیجه خوشه بندی بهتر می باشد.

معیار DBCV (Density Based Clustering Validation)
این شاخص به عنوان معیاری برای ارزیابی خوشه های پیچیده و غیر کروی و بر مبنای تراکم داده ها محاسبه می شود. ایده کلی این شاخص بر اساس ترکیب تراکم داده ها در داخل و بین خوشه ها هست.
محاسبه این شاخص نسبت به سایر روش های گفته شده، دارای پیچیدگی محاسباتی و زمان بیشتر می باشد و همانند شاخص سیلوئت دارای دامنه 1- تا 1 بوده و برای هر خوشه امکان ارزیابی کیفیت جداگانه آن نیز وجود دارد.
