
انواع داده ها را می توانیم از 2 بعد بررسی کنیم:
1- موضوع داده
2- ساختار داده
موضوع داده مثل: مالی، پزشکی، کسب و کار، حوزه های علم مانند فیزیک، نجوم و …
ساختار داده یعنی: 1- ساخت یافته 2- نیمه ساخت یافته 3- غیرساخت یافته

بر اساس موضوع داده
هرجا داده ای وجود داشته باشد علم داده می تواند آنجا نقش داشته باشد و ارزش خلق کند و محدودیتی در نوع موضوع نداریم. زیرا ما در علم داده یکسری ابزارها و الگوریتم هایی داریم که فارغ از دامنه و موضوع مورد بررسی، میتواند بدون نیاز به تغییر و یا با حداقل تغییر مورد استفاده قرار گیرد.
بر اساس ساختار داده ها
اولین دسته داده های ساختیافته است که راحتترین و دم دست ترین دیتاها هستند که فارغ از سادگی یا پیچیدگی آنها، ساختار مشخصی دارند که الگوریتم ها و کامپیوترها می توانند آنها را شناسایی کنند و با آنها ارتباط برقرار کنند: مثلا دیتاهای موجود در یک شیت اکسل که واضح و شفاف است.
اندکی پیچیده تر بشود مثلا داده های موجود در پایگاه داده ها. که مثلا بتوانیم بر اساس داده های 2جدول شفاف و ارتباطی که بین این 2 ایجاد کرده ایم، جدول سومی را داشته باشیم که اطلاعات جدیدی از آن دیتاها به ما بدهد.

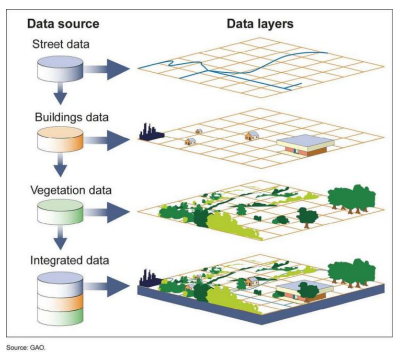
می توان از دید دیگری به این دیتاها نگاه کرد مثلا پایگاه داده های جغرافیایی (GIS) . در شکل زیر اگر هرکدام از سلول ها نشان دهنده مختصات جغرافیایی باشد، آنگاه مثلا می توانیم بگوییم که در یک لایه جاده ها را نشان می دهیم، لایه بعدی ساختمان ها، لایه بعدی فضای سبز و در لایه دیگری همه این لایه ها را در کنار هم داریم. اشتراک همه آنها طول و عرض جغرافیایی است. مثلا در یک شعاع جغرافیایی می توانیم ببینیم که چندمدرسه، بیمارستان، فضای سبز، بزرگراه و … وجود دارد.
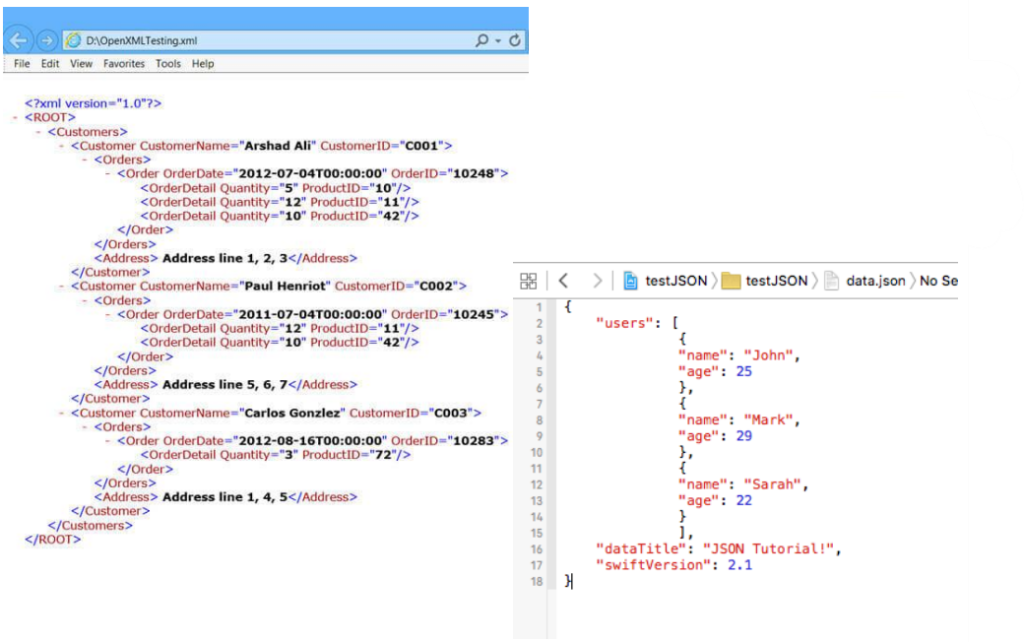
دسته دوم داده های نیمهساختیافته هستند مثل فایل های XML یا Json بر اساس تگ ها و لیبل هایی که دارند، به نوعی یک ساختاری دارند که کمک می کنند تا کامپیوتر آنها را بشناسد. ما به عنوان یک انسان ساختاری مثل شیت اکسل را بهتر درک می کنیم و با این ساختارهایی شبیه XML زیاد راحت نیستیم و این بیشتر برای نرم افزار و الگوریتم مناسب است.
از آنجایی که این فایل ها به صورت تکست و متن هستند، حجم کمتری دارند نسبت به مثلا اکسل دارند به همین دلیل یکی از انواع فایل های رایج به عنوان واسط بین نرم افزارها هستند. یعنی مثلا خروجی یک کار را با فرمت XML یا Json دریافت می کنیم و به عنوان ورودی به نرم افزار دیگری می دهیم. به ویژه زمانی که نقش انسانی در این فرایند وجود نداشته باشد، این داده ها بسیار مناسب و رایج هستند.
رایج ترین داده هایی که ما در اطراف خود داریم داده های غیرساختیافته هستند مانند انواع تصاویر، متن، ویدیو، صداها و … . واکشی اطلاعات از این دیتاها برای کامپیوتر کار دشواری است و پیچیدگی های بالایی دارد. مثلا نرم افزار یک صدایی را میشنود و احساس پشت آن را تشخیص میدهد. یا نزدیکترین موزیک شبیه به آن را پیدا میکند. یا … .
مدرس: محمد روزبه (مدیرعامل گروه دایکه)
مستندساز: ساره واحدی
برگرفته از محتوای آموزشی پانزدهمین دوره علم داده دایکه