در مقاله قبلی رویکرد اول را که مبتنی بر آمار و احتمال بود معرفی کردیم. در این مقاله به رویکرد دوم که مبتنی بر یادگیری ماشین است میپردازیم.
یادگیری ماشین
شاخه ای از هوش مصنوعی داده محور است که سعی در توسعه الگوریتم هایی دارد که با یادگیری اتوماتیک الگوی موجود در داده ها به تصمیم گیری بپردازد.
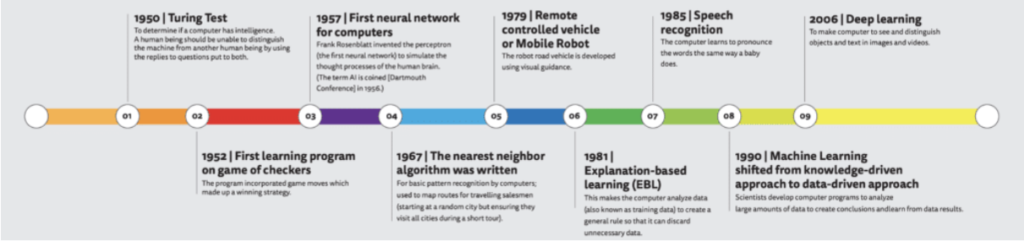
از سال ۱۹۵۶ تا ۱۹۷۳ دوره ای است به نام هوش مصنوعی نمادین که به عنوان عصر طلایی هوش مصنوعی نامیده می شود. در این دوره ارتباط زیادی بین هوش مصنوعی و ماشین لرنینگ وجود ندارد زیرا افرادی که در آن زمان در موضوع هوش مصنوعی فعالیت داشتند ابزارها و روش ها و رویکردهای شان بیشتر مبتنی بر روش های دانش محور بود و نه داده محور. در صورتی که یادگیری ماشین یک رویکرد داده محور محسوب می شود.
روش دانش محور یعنی اینکه من به عنوان شخصی که قصد دارم سیستم هوش مصنوعی ماشین را توسعه بدهم، آن دانشی را که تا آن زمان بشر به آن رسیده است به ماشین منتقل کنم و سعی کنم ماشینی را توسعه دهم که در بخشهایی جایگزین انسان شود و مانند انسان فکر کند و تصمیم بگیرد. این رویکرد، رویکرد بالغ در آن زمان بود. با توجه به دستاورد های اولیه و امیدها و انتظار هایی که آن زمان ایجاد شده بود توانست مبالغ بودجه بسیار زیادی را به خود اختصاص دهد. دانشگاه های همچون MIT و استنفورد پروژه های تحقیقاتی بزرگی را صرف روش های هوش مصنوعی کردند.
در کنار این رویکرد غالب و عمده، یک گروه اقلیت وجود داشتند که تحت عنوان ارتباط گرا، یک سری روش های داده محور بر مبنای تئوری احتمال و روش های آماری را بر اساس داده ها توسعه دادند که نتیجه آن معرفی اولین الگوریتم های شبکه عصبی بود. این گروه از آنجایی که در گروه اقلیت بودند نتایج کارشان را اغلب در قالب هوش مصنوعی ارائه نمی دادند.
از سال ۱۹۷۳ تا ۱۹۸۰ بسیاری از این پروژه ها شکست خوردند. به عنوان مثال پروژه ماشین ترجمه، مدل های داده محور شبکه های عصبی پرسپترون در زمینه ارتباط گیری و همچنین پروژه درک گفتار دانشگاه کارنگی ملون و دار شکست خوردند. همه این ها منجر به کاهش شدید و قطع بودجه پروژه های هوش مصنوعی شد و از این دوره به عنوان زمستان اول هوش مصنوعی نام می برند.
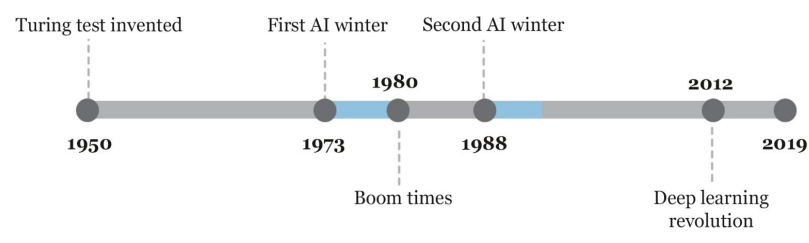
از سال ۱۹۸۰ تا ۱۹۸۸ به دوره رونق دوباره هوش مصنوعی بود که در این بازه زمانی مجدداً بودجههای تحقیقاتی برای هوش مصنوعی تخصیص داده شد. یکی از اتفاقات مهم این دوره این بود که دولت ژاپن تصمیم گرفت نسل پنجم کامپیوتر و حرکت به سوی هوش مصنوعی را آغاز کند. در این دوره همچنان تاکید بر رویکرد های دانش محور سیستم های خبره در قالب گزاره های اگر-آنگاه (if-then) با نمادهای قابل درک توسط هوش انسانی بود.
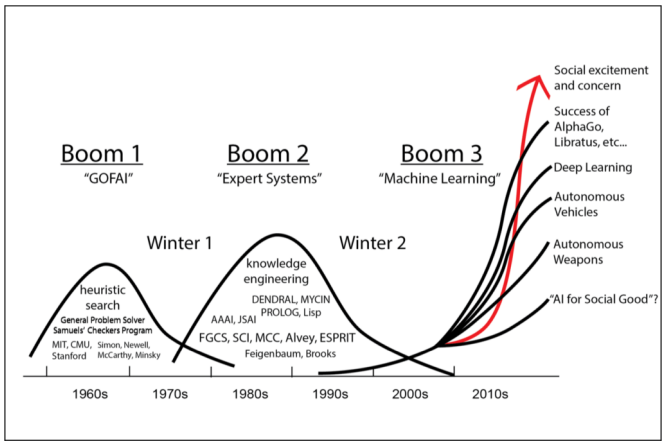
سال ۱۹۸۸ تا ۱۹۹۳ زمستان دوم هوش مصنوعی نامیده می شود. یکی از دلایل آن هزینه های گزاف نگهداری و به روز رسانی سیستم های خبره بود. زیرا سیستم های خبره ای که قبلاً برای آن ابزار ها بهینه سازی شده بودند اکنون با تغییر شرایط و پیشرفت تکنولوژی لازم بود که به روز رسانی یا تعویض شوند که هزینههای گزافی برای بروزرسانی این سیستم ها وجود داشت. همچنین سیستم های قبلی در چند زمینه خاص توسعه داده شده بودند و توسعه جدید آن برای شرایط جدید هزینه های بسیار زیادی در بر داشت. مجموعه همه این شرایط باعث خروج سرمایه از بازار هوش مصنوعی و در نتیجه زمستان دوم هوش مصنوعی شد.
از سال ۱۹۹۳ تا کنون هوش مصنوعی با یک شیب تند سیر تکاملی خود را طی می کند. در این بازه زمانی هوش مصنوعی مجدداً موضوع جذاب شد و گروه های زیادی به آن علاقهمند شدند و به آن وارد شدند و توانست بودجه های زیادی را به خود اختصاص داد. با این تفاوت که این بار از رویکرد دانش محور به سمت رویکرد داده محور رفتن و جریان اقلیت که ارتباط گرا بودند و بر مبنای تئوری احتمال و روش های آماری داده ها را توسعه می دادند این بار جریان غالب شدند و رویکرد هوش مصنوعی داده محور شد.
بیراه نیست اگر بگوییم که امروزه هوش مصنوعی مترادف با یادگیری ماشین بیان می شود و هرگاه که راجع به هوش مصنوعی صحبت می کنیم روش های ما عملاً روشهای یادگیری ماشین هستند.
البته روش های دیگری هم هستند که ما اینجا به آنها نمی پردازیم. در این دوره الگوریتم های یادگیری ماشین به عنوان روشهای داده محور با استفاده از روش های آماری توانست مدل های بسیار مهمی را توسعه دهد مثلا روش Backpropagation یا درخت های تصمیم، SVM، مدل های جمعی. در این دوره شاهد تغییر نگرش از هوش مصنوعی جامع به هوش مصنوعی برای حل مسائل خاص هستیم.
در ۲ دوره قبلی شاهد تصوری بودیم که هوش مصنوعی جامع را داشته باشیم که بتواند جایگزین انسان بشود. در سال ۱۹۹۳ این رویکرد کنار گذاشته شد و ما با استفاده از هوش مصنوعی و یادگیری ماشین بتوانیم یک مسئله ویژه را حل کنیم و چیزهای بیشتری را از آن انتظار نداشته باشیم.
چند دستاورد مهم هوش مصنوعی از ۱۹۹۳ تا ۲۰۱۱:
در ۱۹۹۳ اولین بازی کامپیوتری توسط شبکه های عصبی ساخته شد.
در ۱۹۹۷ توانستند یک مدل هوش مصنوعی بنویسند که گری کاسپاروف را در بازی شطرنج شکست دهد.
در ۲۰۱۱ پیروزی ماشین هوش مصنوعی IBM Watson در بازی تلویزیونی jeopardy.
با وجود همه دستاوردها و پیشرفت هایی که هوش مصنوعی در این دوره داشت اما همچنان سوال بزرگ و بی پاسخ در این دوره باقی ماند اینکه آیا یادگیری ماشین می تواند مانند انسان درکی از متن تصویر صدا و غیره داشته باشد؟

از سال ۲۰۱۱ تاکنون به عنوان دوره الگوریتم های یادگیری عمیق می شناسیم. الگوریتم های یادگیری عمیق از نظر تئوری تقریباً در سال ۲۰۰۳ معرفی شد از سال ۲۰۱۱ به این طرف بود که توانست قدرت خود را نشان دهد و به دو دلیل بود:
دلیل اول، رشد شبکه های اجتماعی و اینترنت که باعث تولید داده های بسیار زیادی شد و این داده ها در اختیار شرکت های بزرگی مانند گوگل و فیسبوک و آمازون بود که تیم های هوش مصنوعی قوی داشتند و اکنون دیتاهای بسیار زیادی در اختیار آنها قرار میگرفت.
دلیل دوم، رشد صنعت بازی بود که باعث سرمایه گذاری و توسعه روی پردازنده های گرافیکی شد و این پردازنده های گرافیکی با قیمت ارزان تر در دسترس عموم قرار بگیرد که این به نفع جامعه هوش مصنوعی شد و توانستند با هزینه کمتری نسبت به قبل، سخت افزارهای بهتری داشته باشند. درنتیجه الگوریتم های یادگیری عمیق که از قبل معرفی شده بودند در این دوره بتوانند روی سیستم ها اجرا بشوند.
ترکیب این دو عامل با همدیگر، یعنی داده های بسیار زیادی که در اختیار شرکتهای بزرگ بود و ارزان شدن تکنولوژی، باعث شد که امکان پیادهسازی ساختارهای پیچیده از شبکه های عصبی چند لایه تحت عنوان یادگیری عمیق به عنوان شاخهای قدرتمند از یادگیری ماشین توسعه پیدا کند.
چند دستاورد مهم یادگیری عمیق از سال ۲۰۱۱ تاکنون:
دستاورد های ویترینی این دوره:
۲۰۱۲: توسعه مدل شبکه عصبی عمیق برای شناسایی تصویر گربه در تصاویر بدون برچسب یوتیوب توسط تیم گوگل به سرپرستی Andrew Ng
۲۰۱۵: پیروزی ۵ بر ۰ هوش مصنوعی AlphaGO_Fan در مقابل قهرمان بازی GO با زیر ساخته ۱۷۶ پردازنده GPU به صورت توزیع شده
۲۰۱۶: پیروزی ۴ بر ۱ هوش مصنوعی AlphaGO_Lee در مقابل قهرمان بازی GO با زیرساخت ۴۸ پردازنده GPU به صورت توزیع شده
ماه می سال ۲۰1۱: پیروزی ۶۰ بر ۰ هوش مصنوعی AlphaGO_Master در مقابل جمعی از قهرمانان بازی GO با زیر ساخت ۴ پردازنده TPU روی یک ماشین.
یعنی توانستند معماری الگوریتم را بهینه کنند و هزینه ها را بسیار کاهش دهند و در عین حال توانایی کارکرد برنامه افزایش دهند.

اکتبر ۲۰۱۷: پیروزی ۱۰۰ بر ۰ هوش مصنوعی AlphaGO_Zero مقابل AlphaGO_Lee با زیرساخت چهار پردازنده TPU روی یک ماشین طی ۳ روز
اکتبر ۲۰۱۷: پیروزی ۸۹ بر ۱۱ هوش مصنوعی AlphaGO_Zero در مقابل AlphaGO_Master با زیرساخت ۴ پردازنده TPU روی یک ماشین طی ۲۱ روز
دسامبر ۲۰۱۷: معرفی الگوریتم AlphaZero که طی ۲۴ساعت میتواند به بالاترین سطح توانمندی قهرمانان جهان در بازی های GO, شطرنج و … برسد.
۲۰۱۹: پیروزی اولین هوش مصنوعی در بازی پوکر توسط تیم تحقیقاتی دانشگاه کارنگی ملون و فیسبوک
۲۰۲۰: حل مسئله ۵۰ ساله زیست شناسی با مدل پیش بینی و شبیه سازی ساختار سه بعدی تا شدگی پروتئین.
محدودیت های یادگیری ماشین:
- معمولا حجم زیادی از داده های مناسب را نیاز دارد. در پروژه های تحقیقاتی امروز تلاش می شود که بتوانند با حجم داده های کمتری نیز یادگیری ماشین انجام شود. انسانها در صورتیکه یک، دو یا چند بار محدود با صحنه ترسناک مواجه شوند بار دیگر که با آن صحنه مواجه می شوند احساس ترس میکنند اما ماشین نیاز به دفعات بسیار زیادی دارد که آن صحنه ترسناک را ببیند تا واکنش مورد نیاز را انجام دهد، در تحقیقات امروزه تلاش می شود که تعداد و حجم داده ها کمتر شود تا یادگیری ماشین به سرعت یادگیری انسان نزدیک تر شود.
- هر مدل ساخته شده صرفا برای حل یک مسئله مشخص کارایی دارد و خارج از دامنه داده های آموزش داده شده قابل استفاده نیست.
- حریم خصوصی داده و محدودیت در دسترسی به داده های مناسب. ما به عنوان یک دیتا ساینتیست مایل هستیم که حجم بسیار بیشتری داده داشته باشیم، هم حجم داده های بسیار بیشتر و هم از جنبه های متفاوت دیتاهایی را جمع آوری کنیم اما طبیعتاً بحث حریم خصوصی داده ها همچنان جدی است و محدودیت های قانونی و خصوصی برای آنها وجود دارد و محدودیت هایی را برای برخی از مسائل ماشین لرنینگ ایجاد میکند.
- انتخاب نادرست نوع مسئله و الگوریتم مناسب توسط تحلیلگر. یعنی اینکه یادگیری ماشین همچنان به یک عامل انسانی یک فرد یک تحلیلگر نیازمند است تا بتواند فضای داده ها الگوریتم ها و نوع مسئله را بشناسد تا بتواند انتخاب درستی برای آن مسئله داشته باشد.
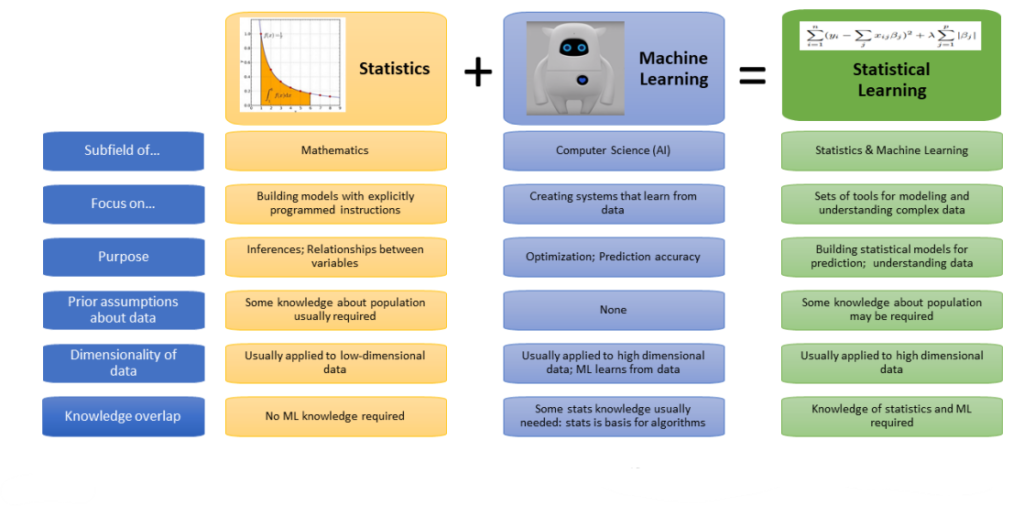
آمار و یادگیری ماشین
از هم افزایی علم آمار و یادگیری ماشین و ترکیب نقاط قوت این دو مفهوم جدیدی به عنوان یادگیری آماری مطرح شد. خیلی از اوقات یادگیری ماشین مفهومی شبیه به یادگیری آماری دارد و به طور یکسان به کار می روند اما اگر به طور دقیق تر نگاه کنیم یادگیری آماری چارچوبی از یادگیری ماشین است که بر پایه آمار و آنالیز تابعی ریاضیات استوار است.