
هنگامی که از “علم داده” صحبت میکنیم، باید مشخص کنیم که منظور از “داده” چیست. علاوه بر این، بخش “علم” که قبلاً به آن اشاره شد، شامل چه رویکردهایی است؟ این دو مفهوم، پایههای اصلی علوم داده هستند و عمدتاً در رویکردهای تحلیلی شامل آمار، احتمال و یادگیری ماشین تعریف میشوند. در ابتدا، به بررسی دادهها میپردازیم.
انواع دادهها
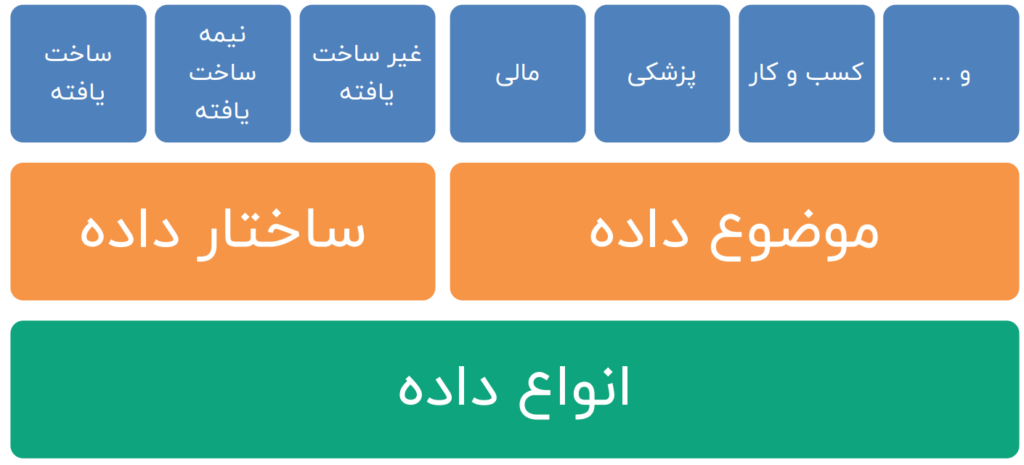
دادهها را میتوان از دو منظر دستهبندی کرد:
- موضوع دادهها: دادهها ممکن است از حوزههای مختلفی مانند مالی، پزشکی، بازاریابی، مدیریت یا علوم دیگر استخراج شوند.
- ساختار دادهها: دادهها از نظر ساختاری به سه دسته تقسیم میشوند: دادههای ساختیافته، نیمهساختیافته و غیرساختیافته.
دادههای ساختیافته
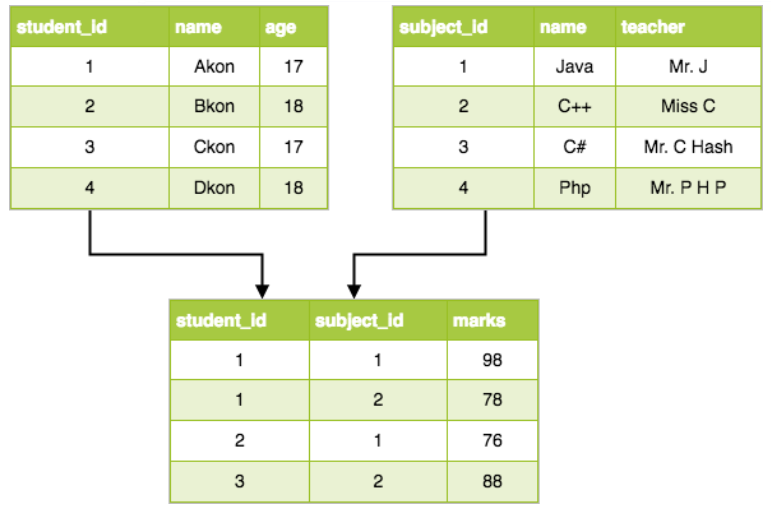
یکی از سادهترین نمونههای دادههای ساختیافته، جداول موجود در فایلهای اکسل است. هر سطر نشاندهنده یک رکورد و هر ستون نشاندهنده ویژگیهای آن رکورد است. به عنوان مثال، اطلاعات مشتریان در یک جدول شامل نام، جنسیت، سن و درآمد آنها ذخیره میشود. علاوه بر این، پایگاههای داده رابطهای نیز نمونهای از دادههای ساختیافته هستند که شامل جداول مرتبط با یکدیگرند.
در این پایگاهها، اطلاعات تکراری کاهش یافته و مدیریت دادهها بهینه میشود. برای مثال، اطلاعات دانشجویان و دروس آنها در جداول جداگانهای ذخیره میشوند و با استفاده از کلیدهای ارتباطی مانند “Student ID” به یکدیگر مرتبط میشوند. این ساختار امکان مدیریت مؤثر دادهها را بدون تکرار فراهم میکند.
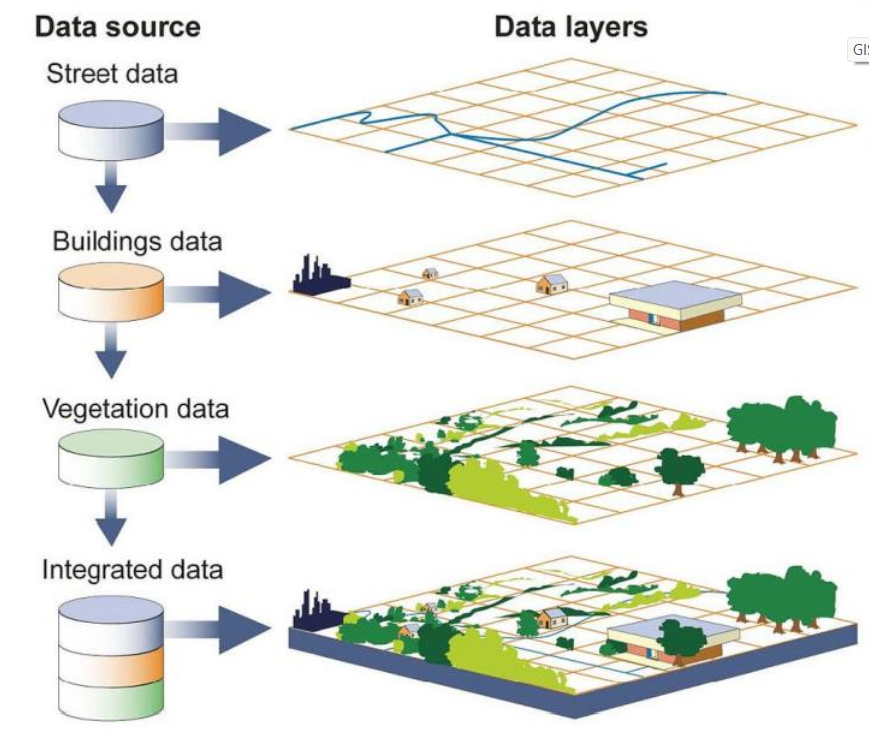
پایگاه دادههای جغرافیایی (GIS)
پایگاههای داده جغرافیایی شامل دادههایی هستند که مختصات جغرافیایی (طول و عرض) در آنها اهمیت ویژهای دارد. به عنوان مثال، یک لایه از دادههای جغرافیایی ممکن است شامل خیابانها باشد، لایه دیگری ساختمانها و لایهای دیگر فضاهای سبز. این لایهها ترکیب شده و نمای کاملی از منطقه ارائه میدهند. در این پایگاهها، مختصات جغرافیایی وابستگی خاصی را میان دادهها ایجاد میکند. برای مثال، فاصله یک ساختمان با خیابان مجاور یا نزدیکی آن به فضای سبز تأثیر مستقیمی بر تحلیل دادهها دارد.
دادههای سری زمانی
دادههای سری زمانی یکی دیگر از انواع دادههای ساختیافته هستند. به عنوان مثال، قیمت دلار در روزهای مختلف نمونهای از این نوع دادهها است. این دادهها به دلیل وابستگی زمانی، نیازمند تحلیل پیچیدهتری هستند. هر تغییری در ترتیب این دادهها میتواند الگوها و روندها را تغییر دهد. دادههای سری زمانی به تاریخچه خود وابسته بوده و نیازمند پردازش دقیق هستند. به عنوان مثال، پیشبینی نرخ ارز مستلزم تحلیل دقیق این وابستگیها است.
دادههای نیمهساختیافته
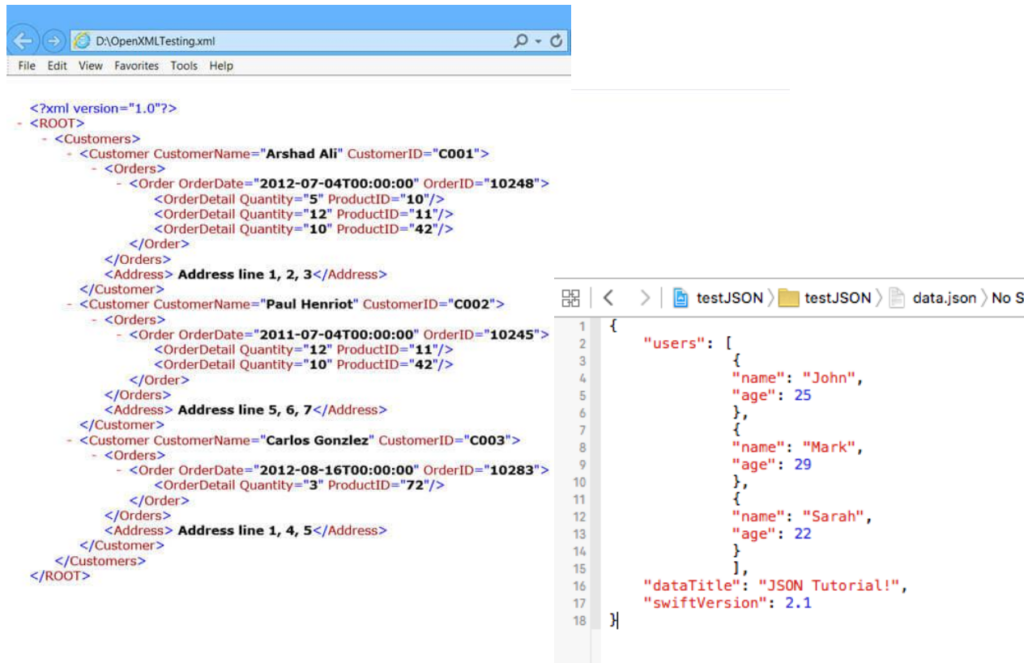
دادههای نیمهساختیافته مانند JSON یا XML دارای ساختاری مشخص اما انعطافپذیر هستند. این دادهها معمولاً بهعنوان واسطه بین نرمافزارها عمل کرده و پردازش آنها را سادهتر میکنند. برای مثال، اطلاعات مشتریان و سفارشات آنها در قالب JSON شامل “Customer ID”، “Order Date” و “Product ID” ذخیره میشود. اگرچه این دادهها قابل درک هستند، اما ترجیح داده میشود که در قالب جداول ذخیره شوند.
در فایلهای JSON، دادهها معمولاً در قالب برچسبها ذخیره میشوند که به هر عنصر یک مقدار خاص اختصاص میدهند. این فرمت برای انتقال دادهها بین نرمافزارها مناسب است و به دلیل سبک بودن، عملکرد بهتری در مقایسه با XML دارد.
دادههای غیرساختیافته
دادههای غیرساختیافته شامل تصاویر، ویدئوها، متون و سیگنالهای صوتی هستند. این دادهها فاقد فرمت مشخصی هستند، اما در الگوریتمهای یادگیری ماشین قابل استفادهاند. برای پردازش این نوع دادهها، ابتدا باید آنها را به فرمت عددی تبدیل کرد. به عنوان مثال:
- تصاویر به ماتریسهایی از اعداد تبدیل میشوند که هر عدد نمایانگر شدت نور در یک نقطه از تصویر است.
- متون به بردارهای عددی تبدیل میشوند که معمولاً با استفاده از تکنیکهایی مانند Word Embedding صورت میگیرد.
- سیگنالهای صوتی نیز به مقادیر دیجیتال مناسب برای پردازش تبدیل میشوند.
برای مثال، در پردازش تصویر، تکنیکهایی مانند فیلترهای کانولوشن یا الگوریتمهای یادگیری عمیق مورد استفاده قرار میگیرند. این الگوریتمها میتوانند ویژگیهای مختلف تصاویر را شناسایی و تحلیل کنند.
پردازش و تحلیل دادهها
فارغ از نوع دادهها (ساختیافته، نیمهساختیافته یا غیرساختیافته)، علوم داده این امکان را فراهم میکند که این دادهها در پروژهها مورد استفاده قرار گیرند. اگرچه پیچیدگیهای اولیه بسته به نوع داده ممکن است متفاوت باشد، اما الگوریتمها و تکنیکهای علوم داده برای تحلیل انواع دادهها طراحی شدهاند.
تمامی دادهها، حتی پیچیدهترین انواع آنها، با پیشپردازش مناسب میتوانند وارد الگوریتمهای یادگیری ماشین شوند. تکنیکهایی مانند پردازش تصویر یا الگوریتمهای پیشرفته یادگیری عمیق به تحلیل خودکار دادههای غیرساختیافته کمک شایانی میکنند.