
در ابتدای مبحث یادگیری گروهی لازم است بیان کنیم که در یادگیری ماشین، روش Ensemble یا کلاسه بندی جمعی از چندین الگوریتم یادگیری اصطلاحاً ضعیف یا همان weak Learner که مدلهای پایه هستند که با ترکیب چندین مدل ضعیف، مدل پیچیدهای ایجاد میشود.
مدلهای ضعیف باید تنها اندکی بهتر از حالت تصادفی یعنی Random Guess باشند استفاده میکند تا بتواند عملکرد بهتری را نسبت به تک تک الگوریتمها بدست بیاورد و عملاً یک پیشبینی دقیقتر و درستتر را ارائه دهد. Ensemble در واقع روش یادگیری ماشین با ناظر است که ابتدا یاد میگیرد و سپس با آنچه که یاد گرفته است، پیشبینیهایش را روی دادههای ناشناخته انجام میدهد.

اگر بخواهیم به زبان ساده توضیح دهیم، فرض کنید که قصد جا به جا کردن یک جسم سنگین را دارید اما به تنهایی از پس آن برنمیآیید. در این شرایط با کمک مثلاً 3 نفر دیگر (که هر یک به تنهایی قادر به جا به جایی جسم نیستند)، میتوانید این کار را انجام دهید و جسم را جا به جا کنید. در واقع با کمک توان جمعی، توانایی انجام یک کار را بدست آوردید.
بر خلاف رویکرد یادگیری که تا کنون گفته شده و سعی بر ایجاد یک مدل قوی و جامع بوده است، رویکرد یادگیری گروهی به دنبال استفاده از برآیند تعداد زیادی مدل ضعیف است، به طوری که قادر به پیش بینی با دقت بالا و قوی شود.
“حتی ضعیف ها هم وقتی متحد شوند، قوی می شوند.” فردریش شیلر
چرا یادگیری گروهی می تواند منجر به نتایج خوب شود؟
-
- Bias – Variance Trade-off
- منابع خطا
- سوگیری (Bias): ناشی از وجود فرضیات ساده سازی در مدلسازی است که مدل توانایی شناسایی روابط پیچیده بین ویژگی های ورودی و مقادیر خروجی را از دست می دهد. (کم برازشی)
- واریانس: ناشی از پیچیدگی و انعطاف بیش از حد مدل است که منجر به حساسیت بالا به تغییرات جزئی در داده های آموزشی و خطای زیاد در داده های آزمایشی می شود. (بیش برازشی)
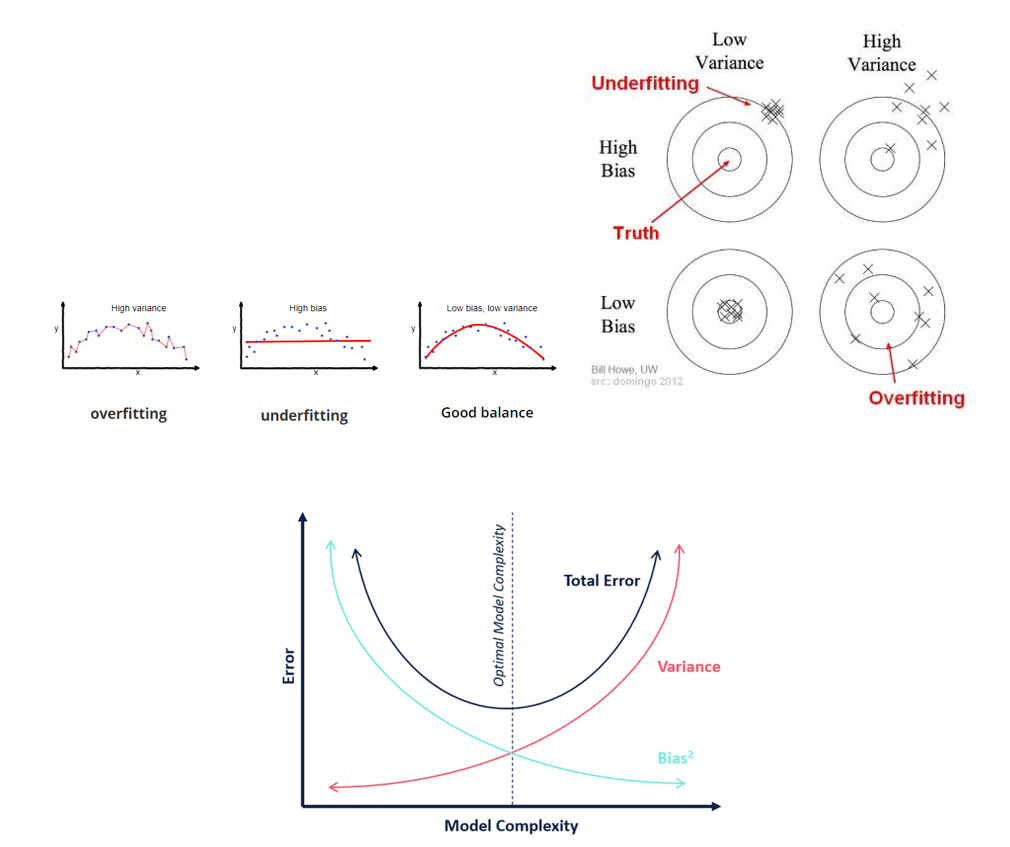
به صورت تئوری انتظار می رود، تمام الگوریتم های مدلسازی، در حین یادگیری از داده های آموزشی به مدلی با میزان سوگیری (بایاس) کم و همچنین مقدار پراکندگی در خطا (واریانس) کم دست پیدا کنند. ولی در خیلی از مواقع دستیابی همزمان به هر دو هدف امکان پذیر نیست. به این حالت مبادله بایاس – واریانس گفته می شود.
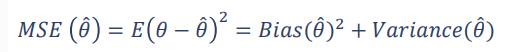

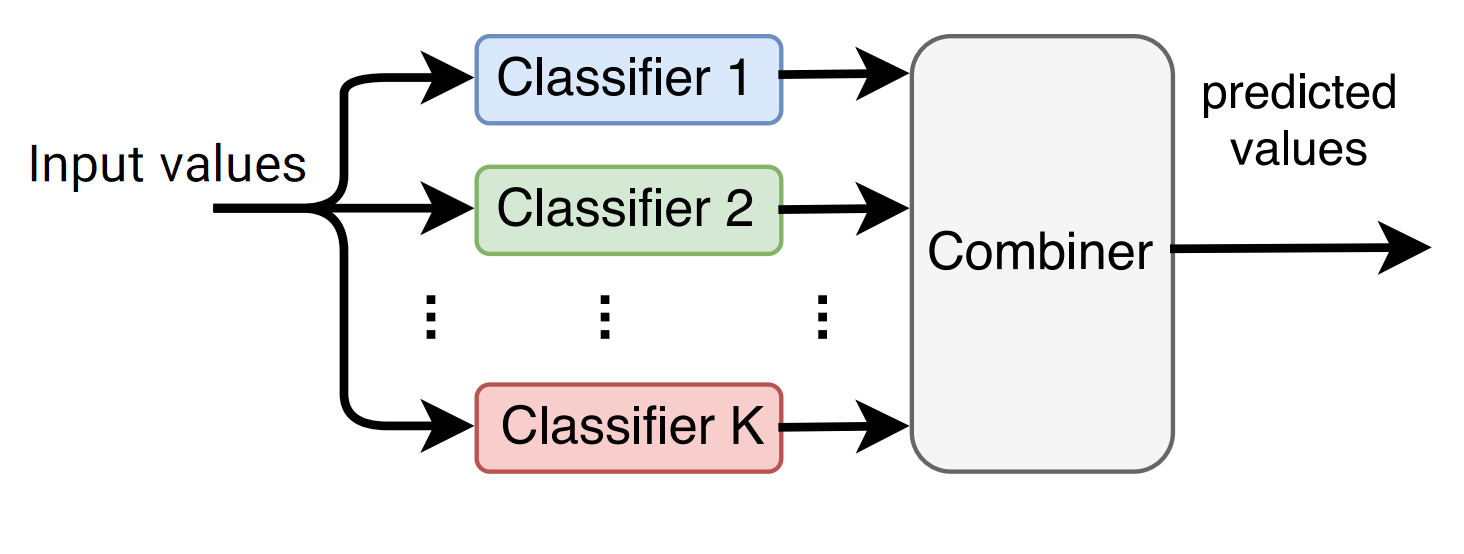
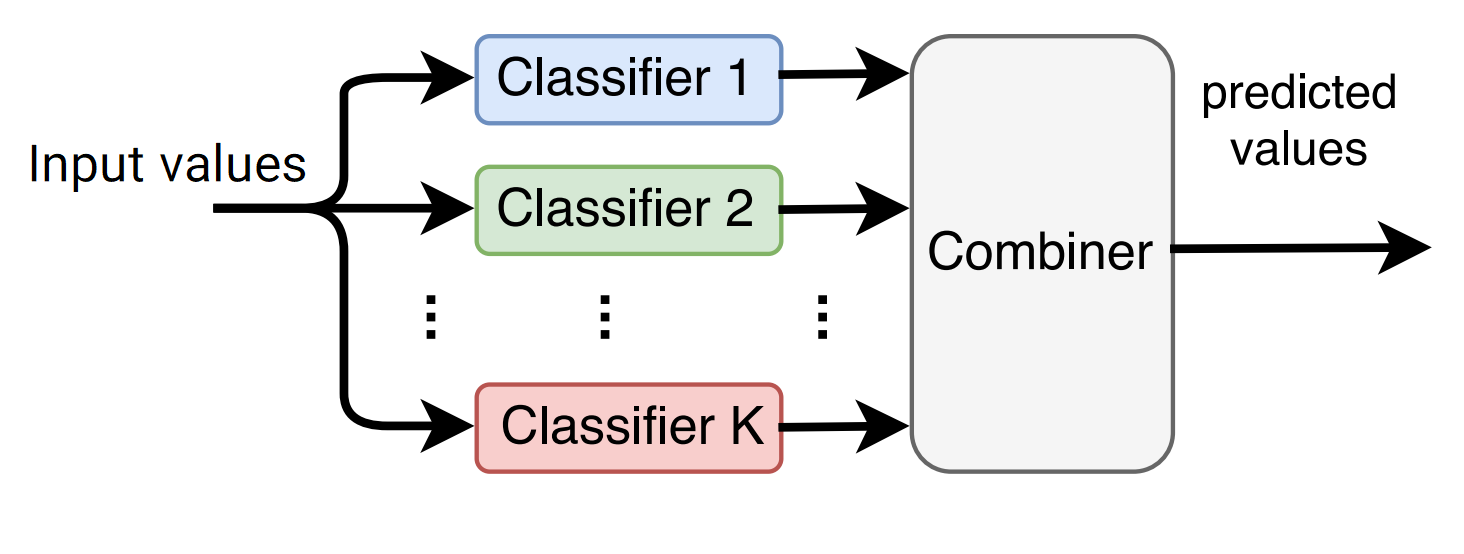
یادگیری گروهی از طریق ترکیب چندین مدل آموزش داده شده برای پیش بینی مقادیر هدف استفاده می کند. بسته به رویکرد یادگیری گروهی، مدل های آموزش داده شده (مدل های پایه) می توانند از:
الگوریتم های متفاوت، یا الگوریتم یکسان در داده های آموزشی متفاوت و یا الگوریتم یکسان در داده های آموزشی یکسان با وزن های متفاوت بدست آیند.
همچنین ترکیب (ادغام) پیش بینی مدل های پایه نیز با دو روش قابل انجام هست:
- خلاصه سازی آماری (استفاده از رای گیری ساده یا وزنی، میانگین، میانه)
- استفاده از Metaclassifier (مدل متا)
مزایای یادگیری گروهی
افزایش کارایی مدل ها: هریک از مدل های انفرادی ممکن است در زیرمجموعه ای از داده ها و الگوهای موجود دارای عملکرد خوب یا بد باشند. ادغام آنها امکان ایجاد یک مدل قوی برای شرایط مختلف را با کاهش بایاس (سوگیری) به وجود می آورد.
افزایش پایداری نتایج: استفاده از شاخص های خلاصه سازی آماری در یادگیری گروهی، امکان کاهش واریانس مقادیر پیش بینی در مدل های انفرادی و در نتیجه افزایش اطمینان و پایداری نتایج را فراهم می سازد.
رویکردهای متنوعی در پیاده سازی یادگیری گروهی وجود دارد، ولی عموما سه رویکرد رایج در یادگیری گروهی مورد استفاده قرار می گیرد:
