
در این پست ابتدا خلاصه جلسه و سپس متن کامل جلسه آموزشی را مطالعه خواهید کرد:
خلاصه جلسه:
1. هدف جلسه
- آغاز مرحلهی تحلیل آماری اولیه دادهها در پروژهی دارویی Kaggle.
- بررسی کیفیت و توزیع دادهها برای درک بهتر از ساختار آنها.
2. استفاده از ChatGPT در تحلیل پروژه
- درخواست از ChatGPT برای ارائهی نقشهی راه گامبهگام برای پروژهی Classification.
- مراحل پیشنهادی شامل:
- درک مسئله
- بررسی کیفیت دادهها
- تقسیمبندی دادهها
- مهندسی ویژگی
- انتخاب و آموزش مدل
- ارزیابی، تفسیر و استقرار مدل
3. خواندن داده با کد تولیدشده توسط ChatGPT
- استفاده از
pandasبرای خواندن فایلdrug.csv. - اصلاح مسیر فایل برای محیط Kaggle.
- اجرای موفق کد و نمایش ۵ ردیف اول دادهها.
- بررسی نوع دادهها و عدم وجود مقادیر گمشده (Missing Values).
4. بررسی نوع ستونها
- ستونهای کمی:
سن،سطح سدیم،سطح پتاسیم→ دادههای عددی (int64,float64) - ستونهای کیفی:
جنسیت،فشار خون،کلسترول،داروی تجویزشده→ دادههای متنی (object)
5. گزارش آماری از ستونهای عددی
- استفاده از
describe()برای بهدست آوردن:- میانگین
- میانه
- انحراف معیار
- حداقل و حداکثر
- چارکها (25٪، 50٪، 75٪)
- مثال: میانگین سن ≈ ۴۴، میانه ≈ ۴۵، انحراف معیار ≈ ۱۶
6. تحلیل توزیع متغیرهای کیفی
جنسیت: نسبت مرد و زن تقریباً برابرفشار خون: High (۳۸٪)، Normal (۳۲٪)، Low (۲۹٪)کلسترول: High (۵۱٪)، Normal (۴۹٪)دارو: کلاس Y ≈ ۴۵٪ (بیشترین)، سایر کلاسها با درصد کمتر
7. هشدار دربارهی توزیع نامتوازن کلاسها
- معرفی مفهوم Imbalanced Classes
- خطر یادگیری ناعادلانه مدل در صورت وجود کلاسهای نادر با حجم دادهی کم
- راهکارهای احتمالی:
- حذف یا ادغام کلاسهای نادر
- Oversampling یا Undersampling
- استفاده از الگوریتمهای مقاوم به عدم توازن
8. نتیجهگیری
- بررسی اولیه دادهها، مبنایی برای طراحی و بهبود مراحل بعدی پروژه.
- آمادهسازی برای ورود به فاز پیشپردازش و مهندسی ویژگیها در جلسهی بعد.
متن کامل این جلسه:
در این جلسه، وارد مرحلهی جدیدی از پروژهی یادگیری ماشین خود در پلتفرم Kaggle میشویم. پس از تعریف مسئله و آمادهسازی دادهها، اکنون زمان آن رسیده است که یک گزارش آماری اولیه از دادهها تهیه کنیم تا شناخت دقیقتری نسبت به وضعیت آنها به دست آوریم.
با توجه به مراحل متدولوژی CRISP-DM که در جلسات گذشته با آن آشنا شدیم، تحلیل آماری اولیه، بخش مهمی از مرحلهی “درک داده” یا Data Understanding محسوب میشود. در این بخش، ما با کمک مدل زبانی ChatGPT تلاش میکنیم تا بهصورت ساختارمندتر به تحلیل و پیشبرد پروژه بپردازیم.
ابتدا در یک گفتوگو با ChatGPT، از آن درخواست میکنیم تا یک نقشهی راه گامبهگام برای حل یک مسئلهی طبقهبندی (Classification) با هفت ویژگی (Feature) و یک متغیر هدف با پنج کلاس ارائه دهد. نکتهی قابلتوجه در این بخش آن است که در تعامل با مدل، نیازی به رعایت دقیق نگارشی یا حتی زبان انگلیسی بینقص نیست؛ مدل، پیام ما را بهخوبی متوجه خواهد شد و پاسخ متناسب را ارائه میدهد. در صورت نیاز میتوان از ابزارهایی نظیر Google Translate نیز برای ترجمهی متون استفاده کرد.
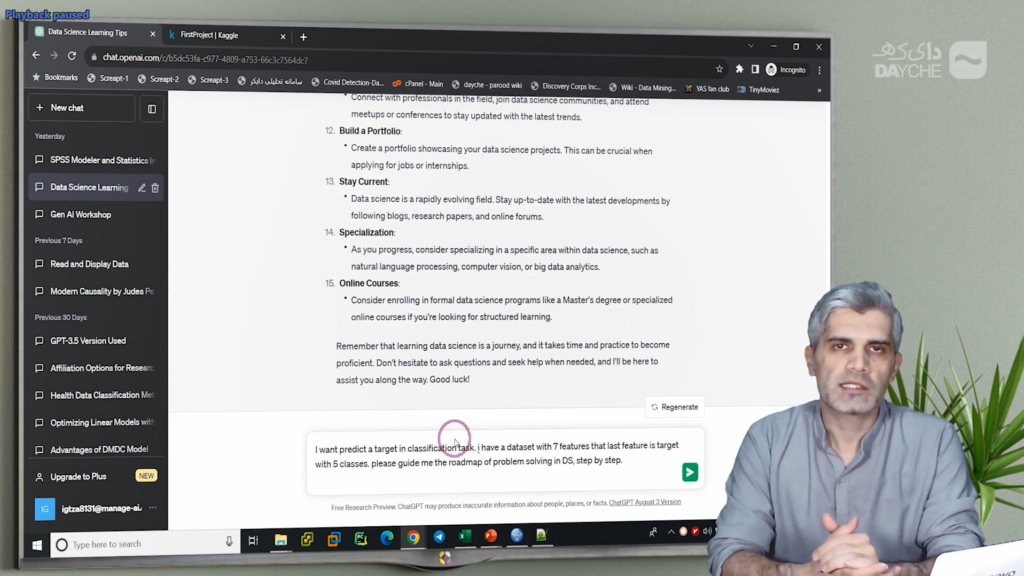
ChatGPT در پاسخ، مراحلی را برای انجام پروژه پیشنهاد میدهد که شامل درک دامنهی مسئله، بررسی کیفیت دادهها، تقسیمبندی دادهها، انجام مهندسی ویژگی (Feature Engineering)، انتخاب و آموزش مدل، ارزیابی عملکرد مدل، تنظیم پارامترها، انتخاب مدل نهایی و در نهایت استقرار مدل است.
در گام بعدی، اطلاعات دقیقتری از فایل دادهای خود در اختیار ChatGPT قرار میدهیم. فایل ما با نام drug.csv، شامل هفت ستون اطلاعاتی است که برخی کمی و برخی کیفی هستند. این ستونها عبارتاند از: سن، جنسیت، فشار خون، کلسترول، سطح سدیم، سطح پتاسیم و داروی تجویزشده. از ChatGPT میخواهیم کدی در زبان پایتون بنویسد که این فایل را بارگذاری کرده، محتوای آن را نمایش دهد و همراه با توضیحاتی در قالب کامنت باشد.
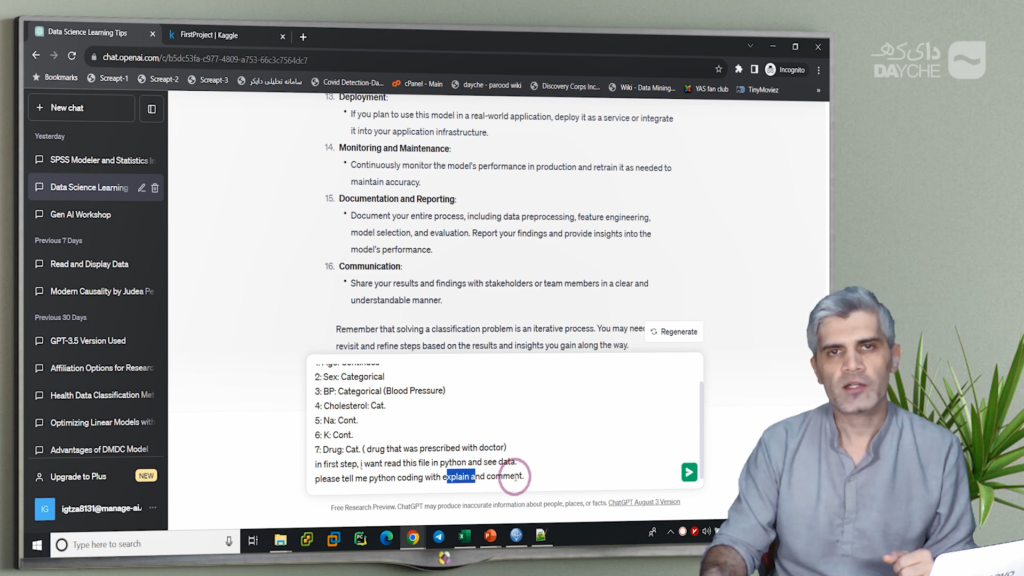
کدی که مدل ارائه میدهد شامل وارد کردن کتابخانهی pandas، مشخصکردن مسیر فایل، بارگذاری فایل با استفاده از تابع read_csv، ذخیرهی آن در یک DataFrame و نمایش پنج ردیف اول دادهها بهوسیلهی head() است. همچنین، با استفاده از تابع info() اطلاعات کلی دربارهی ساختار دادهها مانند نوع ستونها و وجود یا عدم وجود دادههای گمشده نمایش داده میشود.
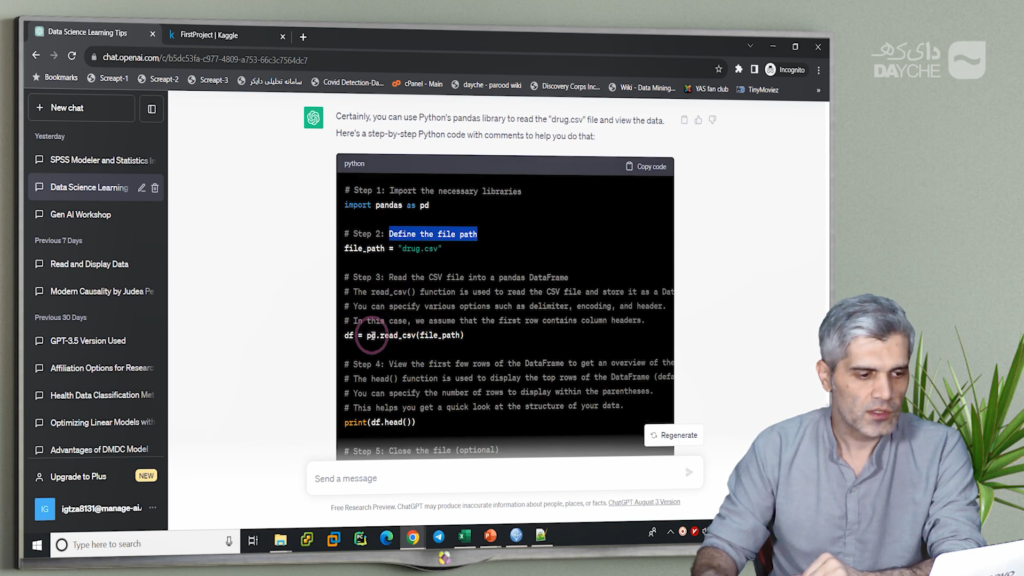
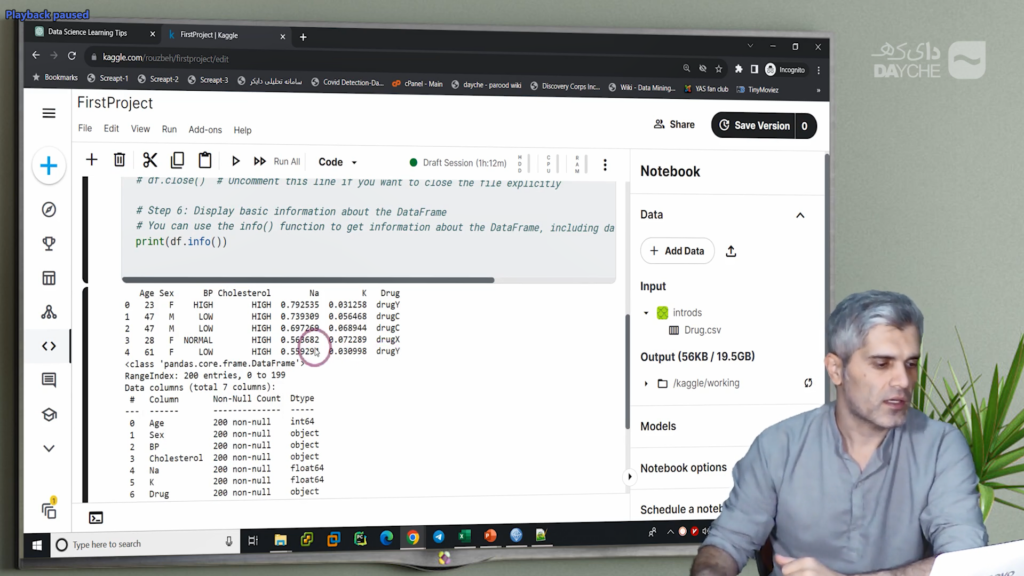
با اجرای این کد در محیط نوتبوک Kaggle، متوجه میشویم که باید مسیر فایل را بهدرستی تنظیم کنیم. در محیط Kaggle، فایلهای بارگذاریشده در مسیر خاصی قرار میگیرند؛ در این مثال، فایل داده در پوشهای با نام intro-ds قرار داشت و لازم بود مسیر آن را به صورت /kaggle/input/intro-ds/drug.csv اصلاح کنیم.
پس از اجرای موفق کد، مشخص شد که هیچیک از ستونها دارای مقدار گمشده نیستند و انواع دادهها نیز تعیین شدند. برای مثال، ستون سن از نوع int64، ستونهای سطح سدیم و پتاسیم از نوع float64 و سایر ستونها مانند جنسیت، فشار خون، کلسترول و دارو از نوع object هستند.
در ادامه، از ChatGPT میخواهیم گزارشی آماری از دادهها ارائه دهد. مدل، کدی را پیشنهاد میدهد که برای ستونهای عددی از تابع describe() استفاده میکند و برای ستونهای کیفی از value_counts() و محاسبهی درصد فراوانی بهره میگیرد. اجرای این کدها منجر به تولید اطلاعات مفیدی میشود.
بهعنوان مثال، میانگین سن بیماران در حدود ۴۴ سال و میانهی آن ۴۵ سال است که نشاندهندهی تقارن توزیع داده در این ستون است. انحراف معیار نیز حدود ۱۶ سال گزارش شده است. این عدد میزان پراکندگی دادهها را حول میانگین نشان میدهد.
در تحلیل ستونهای کیفی، مشاهده میشود که نسبت مردان به زنان تقریباً برابر است. در ستون فشار خون، ۳۸٪ افراد در دستهی High، حدود ۳۲٪ در حالت Normal و ۲۹٪ در دستهی Low قرار دارند. در مورد کلسترول، ۵۱٪ افراد سطح کلسترول بالا دارند و ۴۹٪ در سطح نرمال هستند.
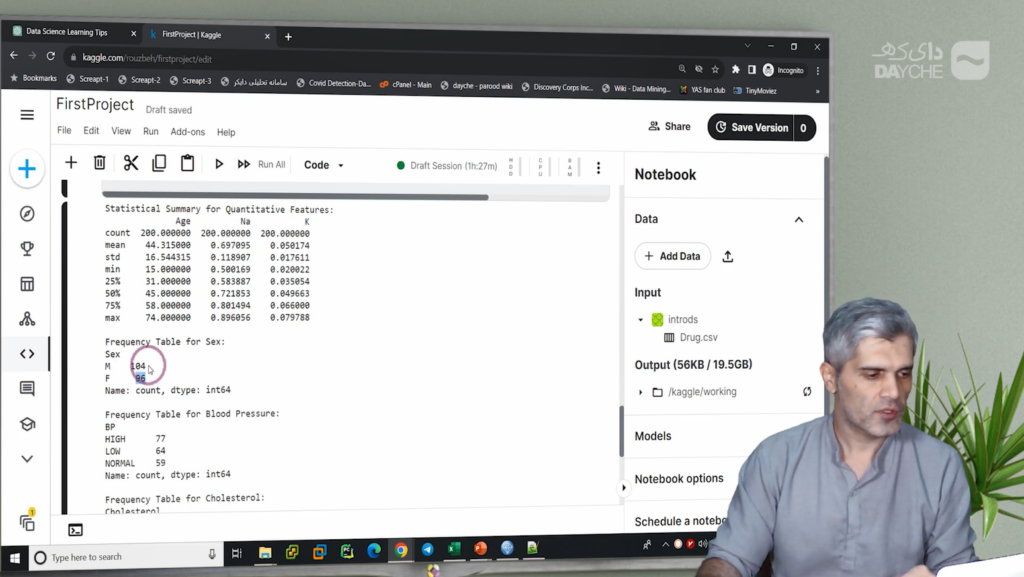
ستون داروی تجویزشده نیز بهعنوان متغیر هدف در مسئلهی ما نقش دارد. در این ستون، داروی Y حدود ۴۵٪ از کل دادهها را تشکیل میدهد و سایر داروها با درصدهای کمتر در رتبههای بعدی قرار دارند.
نکتهی قابلتوجه در این مرحله، بحث مربوط به توزیع نامتوازن کلاسها یا همان Imbalanced Classes است. اگر برخی کلاسها، مانند یک نوع داروی خاص، سهم بسیار کمی از دادهها را داشته باشند، ممکن است مدل یادگیری ماشین در تشخیص و پیشبینی آنها دقت کافی نداشته باشد. این موضوع در حوزههایی مانند پزشکی، که دقت در طبقهبندی اهمیت حیاتی دارد، از اهمیت زیادی برخوردار است.
در این شرایط، مدل ممکن است بهشدت تحت تأثیر کلاسهایی با فراوانی بیشتر قرار گیرد و در نتیجه، عملکرد کلی آن بهظاهر مناسب باشد، اما در پیشبینی کلاسهای نادر ضعیف عمل کند. برای مقابله با این مسئله، راهکارهایی مانند حذف کلاسهای کمنمونه، استفاده از الگوریتمهای خاص برای مدیریت عدم توازن، یا بالانس کردن دادهها از طریق تکنیکهایی مانند Oversampling و Undersampling پیشنهاد میشود.
در مجموع، این جلسه به بررسی آماری اولیهی دادهها اختصاص داشت. با استفاده از قابلیتهای ChatGPT و محیط Kaggle، توانستیم به شکلی ساختیافته دادهها را بررسی کرده، کیفیت آنها را بسنجیم و برای مراحل بعدی مانند پاکسازی و آمادهسازی دادهها آماده شویم.
در جلسهی بعدی، وارد مرحلهی پیشپردازش (Data Preprocessing) و مهندسی ویژگی خواهیم شد.