
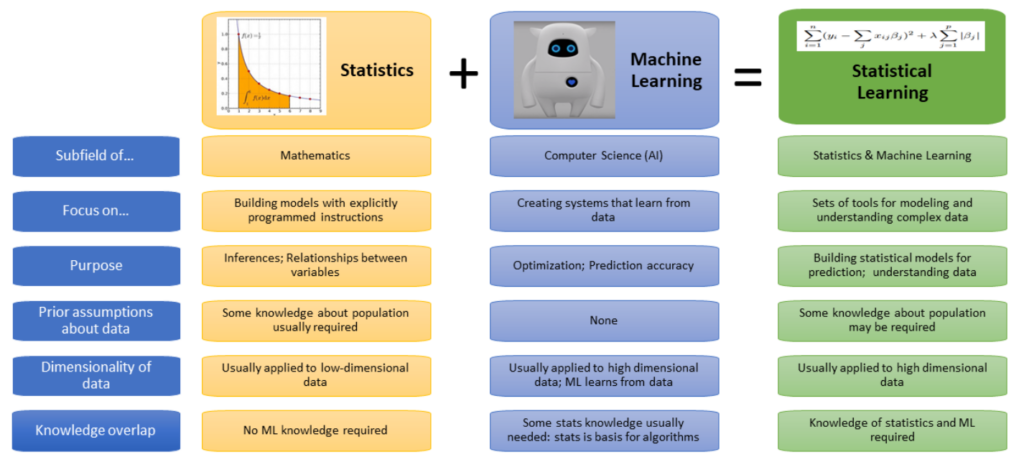
بال دوم از رویکردهای تحلیلی در حوزه دیتا ساینس یادگیری ماشین است. یادگیری ماشین اغلب مترادف با هوش مصنوعی شنیده میشود یا بهعنوان زیرشاخهای از هوش مصنوعی معرفی میشود. حالا وارد بحث ماشین لرنینگ و موضوعات مرتبط با آن میشویم.
تعریف هوش مصنوعی: هوش مصنوعی مجموعهای از تکنیکها و روشهایی است که کمک میکند کامپیوترها از انسان تقلید کنند. انسانها بر اساس چیزی که میبینند یا میشنوند، تحلیل کرده و تصمیمگیری میکنند. هدف هوش مصنوعی این است که کامپیوترها نیز این تواناییها را پیدا کنند. برای رسیدن به این هدف، سه مرحله کلی تعریف شده است:
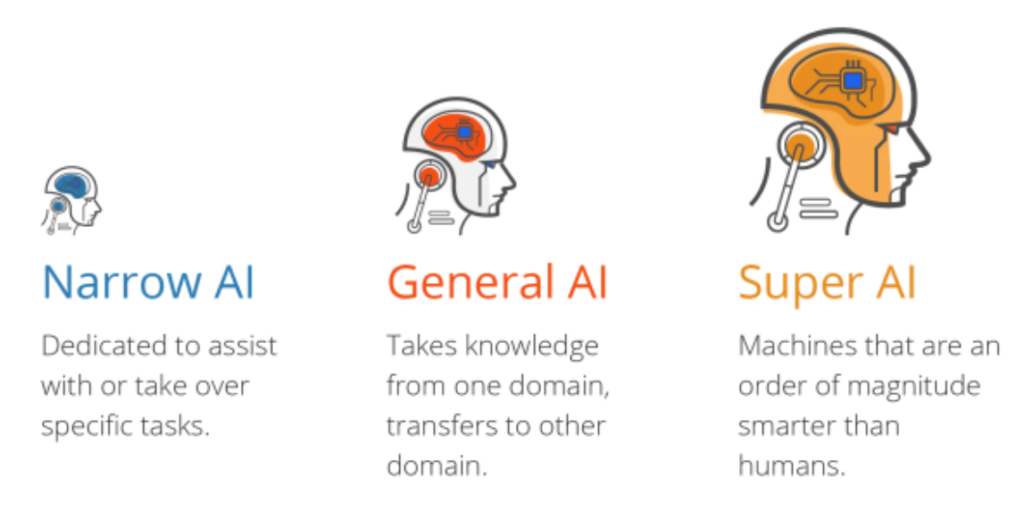
- هوش مصنوعی ضعیف: سیستمی که تنها روی یک وظیفه مشخص تمرکز دارد. برای مثال، اگر وظیفه سیستم تشخیص سگ و گربه در تصاویر باشد، این سیستم تنها میتواند عکسهای سگ و گربه را شناسایی کند. اگر تصویر یک اسب به آن داده شود، نمیتواند آن را تشخیص دهد و به اشتباه ممکن است آن را شبیه سگ یا گربه برچسبگذاری کند.
- هوش مصنوعی قوی (جنرال): سیستمی که توانایی دارد مشابه انسان رفتار کند و دانش حوزههای مختلف را منتقل کند. بهعنوان مثال، انسان اگر برای اولین بار موجودی عجیب و غریب را ببیند، مغز او این موجود را نادیده نمیگیرد یا آن را به دستههای تعریفشده قبلی محدود نمیکند. انسان میتواند ویژگیهای جدید را تحلیل کند و آن را بهطور مستقل درک کند.
- سوپر هوش مصنوعی: سیستمی که فراتر از تواناییهای انسانی عمل میکند. هدف این نوع هوش مصنوعی خلاقیت و هوشمندی بیشتر از انسان است.
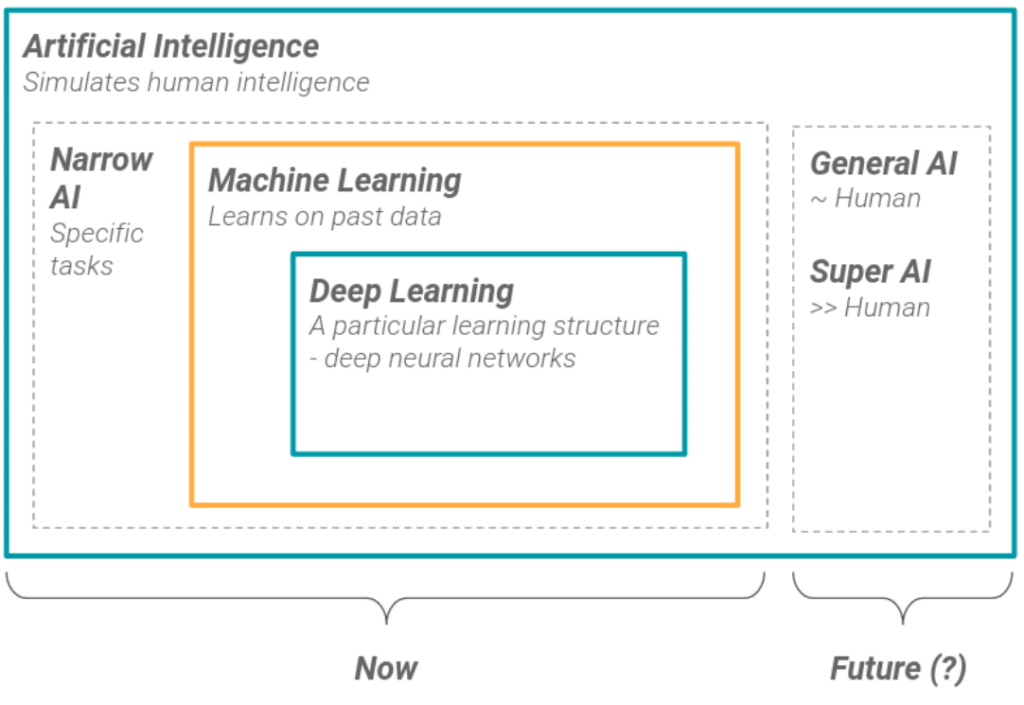
وضعیت فعلی: اکثر پیشرفتهای فعلی در حوزه هوش مصنوعی در محدوده هوش مصنوعی ضعیف است. سیستمهای جنرال و سوپر هنوز در مرحله تحقیقاتی هستند. بسیاری از تحقیقات در تلاش برای نزدیک شدن به هوش مصنوعی قوی هستند، اما هنوز تا دستیابی به این اهداف فاصله زیادی داریم.
ارتباط ماشین لرنینگ با هوش مصنوعی: ماشین لرنینگ زیرمجموعهای از هوش مصنوعی ضعیف است. در این دستهبندی، دیپ لرنینگ بهعنوان زیرمجموعهای از ماشین لرنینگ قرار میگیرد. در نتیجه، دیپ لرنینگ نیز بخشی از هوش مصنوعی ضعیف محسوب میشود.
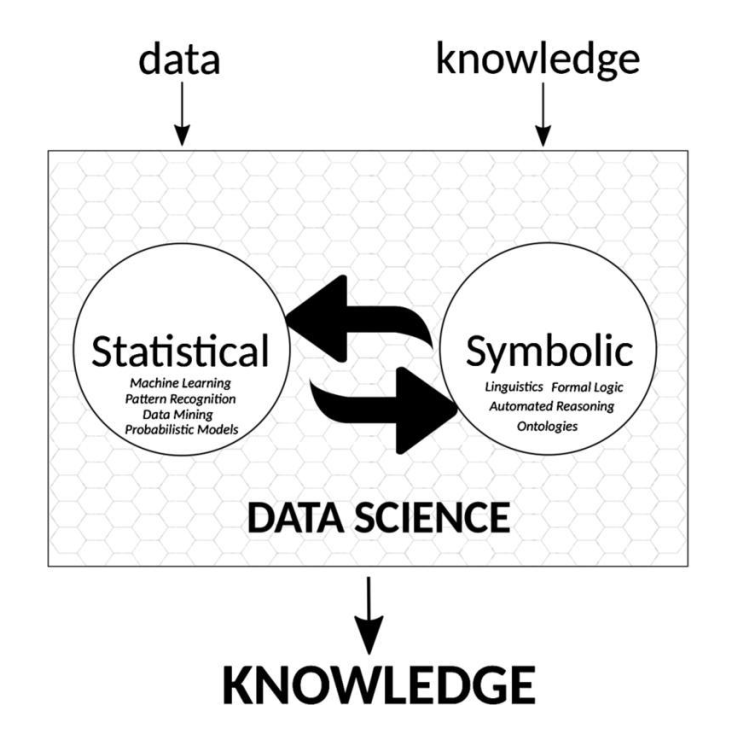
دو رویکرد در هوش مصنوعی:
1. رویکرد دانشمحور (Symbolic): این رویکرد مبتنی بر دانش و اطلاعاتی است که انسانها تولید کردهاند. هدف آن انتقال دانش به سیستمها است تا بتوانند وظایف مشابه انسان را انجام دهند.
2. رویکرد دادهمحور (Connectionist): این رویکرد مبتنی بر دادههای خام است و تلاش میکند از طریق مشاهده دادهها و نتایج، الگوها و دانش جدید استخراج کند. در این روش از آمار، احتمال و مدلهای ریاضیاتی استفاده میشود تا سیستم بهطور خودکار یاد بگیرد و تصمیمگیری کند.
این دو رویکرد پایه و اساس روشهای توسعه هوش مصنوعی را تشکیل میدهند و هرکدام کاربردها و فلسفههای خاص خود را دارند.
پیدایش و دورههای اولیه هوش مصنوعی
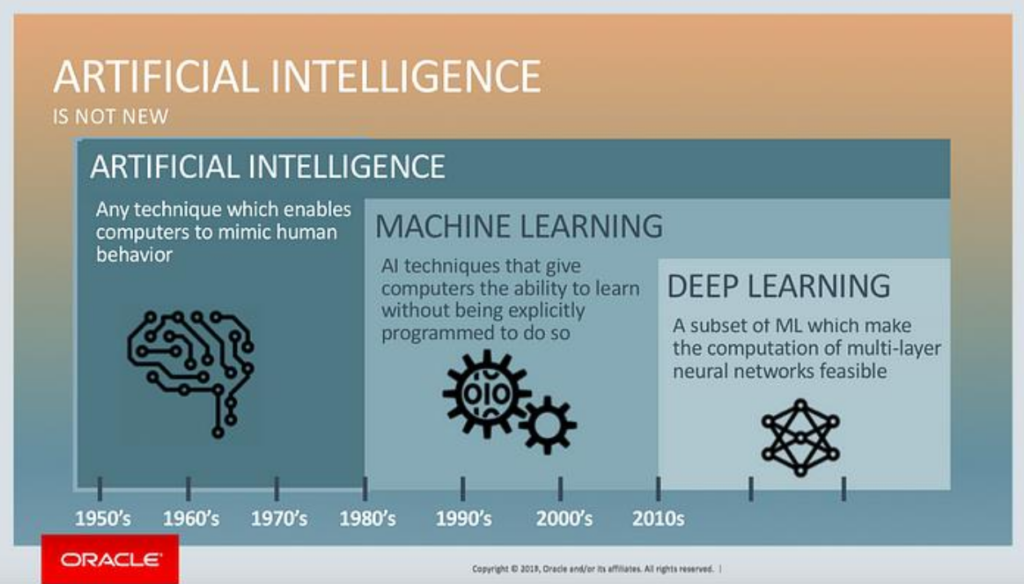
هوش مصنوعی بهعنوان یک حوزه علمی تقریباً از سال ۱۹۵۰ به بعد به شکل جدی متولد و توسعه پیدا کرد. قدمت این علم نسبت به رشتههایی مانند آمار، جدیدتر و متأخرتر است. در دوران اولیه، روشهای دانشمحور بخش عمده و قالب هوش مصنوعی را تشکیل میدادند. از دهه ۸۰ میلادی به بعد، با ظهور روشهای ماشین لرنینگ، این علم بهتدریج از رویکرد دانشمحور فاصله گرفت و به سمت دادهمحوری حرکت کرد.
دهه ۱۹۵۰ تا ۱۹۷۰: هوش مصنوعی نمادین (عصر طلایی)
در اوایل کار، هوش مصنوعی با رویکرد سمبولیک (Symbolic AI) و قوانین از پیش تعریفشده کار میکرد. گروههای اقلیتی که رویکردهای آماری یا شبکههای عصبی اولیه را پیشنهاد میکردند، چندان جدی گرفته نمیشدند. در این دوران، پروژههای عظیمی با بودجههای کلان تعریف شدند که امید زیادی به آنها بسته شده بود. اما در دهه ۱۹۷۰، این امیدها به شکست انجامید و دورهای به نام “زمستان اول هوش مصنوعی” آغاز شد.
در این دوره، بسیاری از پروژهها به دلیل عدم دستیابی به خروجی مناسب تعطیل شدند و سرمایهگذاری در این حوزه کاهش یافت. ناامیدی گستردهای در جامعه علمی ایجاد شد و هوش مصنوعی بهعنوان رؤیایی بلندپروازانه و دستنیافتنی در نظر گرفته شد.
دهه ۱۹۸۰: زمستان اول هوش مصنوعی
با ورود به دهه ۸۰، دوباره سرمایهها به حوزه هوش مصنوعی برگشتند. در این دوره، رویکرد غالب همچنان سیستمهای خبره (Expert Systems) بود که بر مبنای قوانین و دانش متخصصان کار میکردند. این رویکرد در صنایع مختلف از جمله پزشکی، مهندسی و مدیریت پروژههای کلانی پیدا کرد.
با وجود اینکه گروههای دادهمحور و ارتباطگرایان همچنان در حاشیه بودند، به بهبود روشهای خود ادامه دادند. ضعفهایی که در مدلهای قبلیشان وجود داشت را رفع کرده و الگوریتمهای بهتری ارائه دادند. اما این تغییرات هنوز نتوانست رویکرد غالب را تغییر دهد.
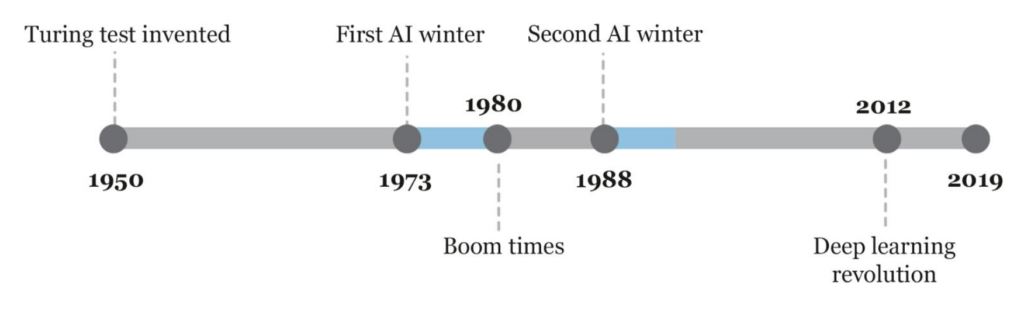
دهه ۱۹۸۰: رونق دوباره هوش مصنوعی با ورود به دهه ۱۹۸۰، هوش مصنوعی بار دیگر مورد توجه قرار گرفت. در این دوران، سیستمهای خبره (Expert Systems) بهعنوان رویکردی غالب مطرح شدند. این سیستمها بر اساس قوانین “اگر-آنگاه” طراحی شده بودند و توانستند در برخی حوزهها عملکرد خوبی داشته باشند.
از دیگر رویدادهای این دوره میتوان به:
- تخصیص بودجه کلان توسط دولت ژاپن برای پروژه نسل پنجم کامپیوتر.
- احیای ارتباطگرایی و توسعه شبکههای عصبی نوین توسط هاپفیلد و روملهارت اشاره کرد.
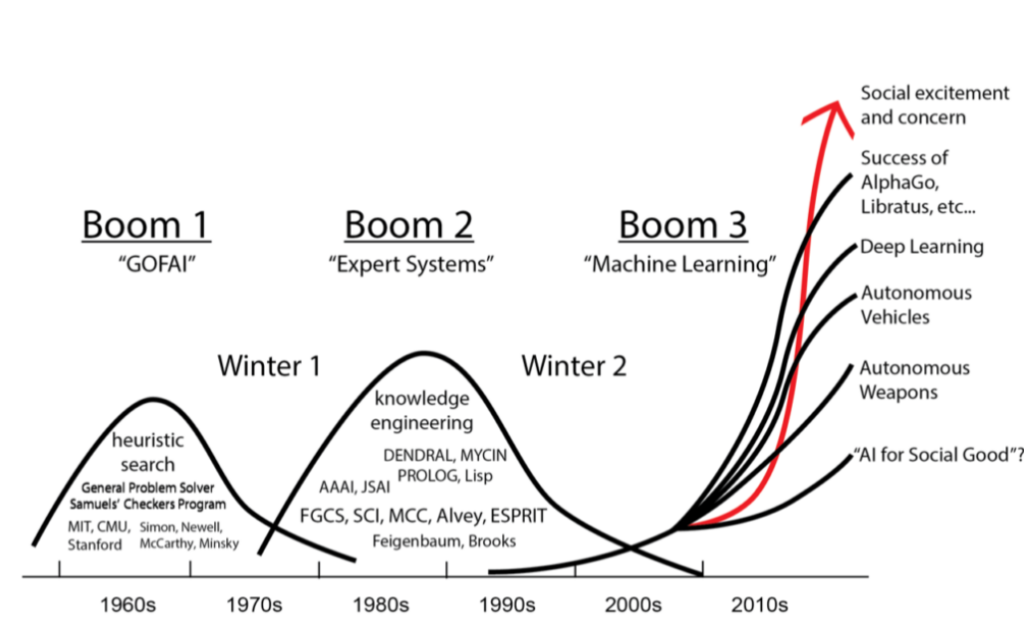
دهه ۱۹۹۰: زمستان دوم هوش مصنوعی
در اواخر دهه ۸۰ و اوایل دهه ۹۰، شکستهای متعدد پروژهها بار دیگر منجر به کاهش سرمایهگذاری شد. این دوره به نام “زمستان دوم هوش مصنوعی” شناخته میشود. در این دوره، بار دیگر جامعه علمی به هوش مصنوعی با تردید نگاه کرد و حتی آن را خیالی خام دانست.
اما این دوره نیز با ظهور تغییراتی پایان یافت. از سال ۱۹۹۳ به بعد، توجهها به سمت روشهای دادهمحور و ارتباطگرا جلب شد. شبکههای عصبی و الگوریتمهای جدید توانستند امید تازهای به این حوزه تزریق کنند.
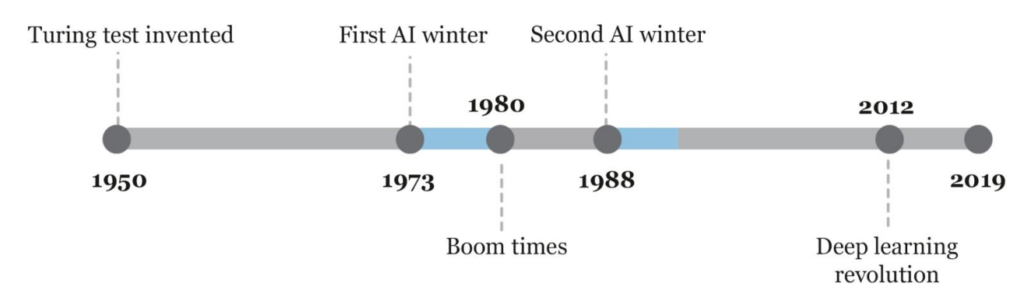
تحولی در دهه ۱۹۹۰: هوش مصنوعی داده محور- یادگیری ماشین
با ظهور رویکردهای دادهمحور، نقش آمار، ریاضیات، و تکنیکهای بهینهسازی در هوش مصنوعی پررنگتر شد. برای اولین بار، ابزارهایی برای شناسایی الگوها و تصمیمگیری خودکار معرفی شدند. این تحولات زمینهساز ظهور یادگیری ماشین (Machine Learning) شدند که توانست از محدودیتهای روشهای قبلی عبور کند.
دهه ۲۰۰۰: اوجگیری یادگیری ماشین
با ورود به دهه ۲۰۰۰، یادگیری ماشین به یکی از ستونهای اصلی هوش مصنوعی تبدیل شد. پیشرفتهای محاسباتی، ظهور کلاندادهها (Big Data) و توسعه الگوریتمهای کارآمدتر باعث شد که هوش مصنوعی از محدودیتهای قدیمی عبور کند.
در این دهه، الگوریتمهایی مانند جنگل تصادفی (Random Forest)، ماشین بردار پشتیبان (SVM) و الگوریتمهای خوشهبندی، برای کاربردهایی مانند تشخیص چهره، پیشبینی بازار و تجزیهوتحلیل دادههای پزشکی بهکار گرفته شدند.
یکی از عوامل کلیدی در این پیشرفت، رشد سریع قدرت محاسباتی بود. کارتهای گرافیکی (GPUs) که ابتدا برای بازیهای ویدئویی طراحی شده بودند، به محاسبات یادگیری ماشین سرعت بخشیدند. این تغییر، مقدمهای برای ظهور دیپ لرنینگ بود.

دهه ۲۰۱۰:
دهه ۲۰۱۰ را میتوان نقطه عطف هوش مصنوعی دانست. الگوریتمهای دیپ لرنینگ (Deep Learning) که بر اساس شبکههای عصبی عمیق کار میکردند، توانستند انقلابی در این حوزه ایجاد کنند. این الگوریتمها قابلیت شناسایی الگوهای پیچیده را داشتند و در مسائلی مانند پردازش زبان طبیعی (NLP)، بینایی ماشین (Computer Vision) و بازیهای رایانهای به کار گرفته شدند.
در سال ۲۰۱۲، الگوریتمهای دیپ لرنینگ توانستند در رقابت ImageNet که برای تشخیص تصاویر طراحی شده بود، برتری چشمگیری بهدست آورند. از این نقطه، استفاده از شبکههای عصبی عمیق بهسرعت در تمام صنایع گسترش یافت.
موارد برجسته در دهه ۲۰۱۰:
- خودروهای خودران: شرکتهایی مانند تسلا و ویمو از هوش مصنوعی برای توسعه سیستمهای خودران استفاده کردند. این خودروها با استفاده از حسگرها، دوربینها و یادگیری ماشین، محیط اطراف را تحلیل کرده و تصمیمگیریهای خودکار انجام میدهند.
- دستیارهای مجازی: ابزارهایی مانند سیری (Siri)، گوگل اسیستنت (Google Assistant) و الکسا (Alexa) نمونههای موفق از پردازش زبان طبیعی بودند که زندگی روزمره را متحول کردند.
- تشخیص بیماری: الگوریتمهای یادگیری عمیق در شناسایی بیماریهایی مانند سرطان و پیشبینی روند بیماریها به کار گرفته شدند.

دهه ۲۰۲۰: مدلهای مولد و آیندهنگری هوش مصنوعی
در دهه ۲۰۲۰، مدلهای مولد (Generative Models) مانند GPT و DALL-E به مرکز توجه قرار گرفتند. این مدلها، با استفاده از معماریهای پیشرفته مانند ترنسفورمرها (Transformers)، توانایی تولید متن، تصویر و حتی ویدیو را پیدا کردند.
مدلهای GPT مانند GPT-3 و نسخههای پیشرفتهتر، نشان دادند که هوش مصنوعی میتواند در نوشتن متون، ترجمه، کدنویسی و حتی خلاقیت هنری عملکردی بینظیر داشته باشد.
ویژگیهای بارز این دوره:
- تعامل انسانی طبیعیتر: مدلهای پیشرفته، قابلیت درک زبان انسانی و تولید پاسخهای هوشمندانه را به سطحی رساندند که شباهت زیادی به مکالمات انسانی پیدا کردند.
- استفاده گسترده در صنایع: از صنایع پزشکی گرفته تا کشاورزی و تبلیغات، هوش مصنوعی به ابزاری ضروری تبدیل شده است.
- اخلاق و چالشها: با قدرت گرفتن هوش مصنوعی، مباحثی مانند شفافیت، حریم خصوصی و اثرات اجتماعی مورد توجه قرار گرفتند.