روش (Discretization / Binning)
گسسته سازی به فرآیند تبدیل داده های پیوسته به مقادیر گسسته در قالب فواصل مجاوری که داده های پیوسته را درون خود قرار داده است، گفته می شود.
در صورتی که طیف اعداد ورودی بسیار متنوع باشد (برای نمونه دادههای مربوط به حقوق کارکنان)، در این حالت میتوان طبقههایی را برای دادهها در نظر گرفت و برای هر طبقه، یک نام انتخاب کرد. (برای نمونه عبارت حقوق اندک برای افراد دارای حقوق کمتر از یک میلیون تومان).
این طبقهها میتوانند جایگزین دادههای پیوسته قبلی یا همان مبلغ حقوق شده و با یک طیف گسسته (حقوق اندک، حقوق متوسط، حقوق بالا)، همان دادهها را شبیه سازی کنند. این تبدیل پیوسته به گسسته، به الگوریتمها کمک میکند تا با یک سادهسازی مختصر، با طیف محدودتری از دادهها مواجه باشند و از پیچیدگیهای محاسبات دادهکاوی کاسته شود.
دلایل انجام گسسته سازی در مبحث تبدیل داده ها چیست؟
- درک ساده تر از داده های اسمی در صورت تناسب با نوع مسئله؛ بطور مثال سطح درآمد کم، متوسط و زیاد
- تفسیر پذیری بیشتر مدل ها از طریق روابط معنادار آماری بین مقادیر گسسته و فیلد هدف
- تطابق بیشتر با برخی الگوریتم های یادگیری ماشین
- حذف نویز های موجود در ثبت اندازه های کمی
رویکرد های گسسته سازی
● Domain Knowledge
در بسیاری از موارد اطلاع از دانش زمینه ای و قواعد کسب و کار مرتبط با داده ها، جهت گسسته سازی ویژگی های کمی، تعیین کننده است.
● Custom discretization
به عنوان مثال استفاده از هیستوگرام توزیع داده ها، ابزار رایج و قدرتمندی در انتخاب بازه های مناسب هست.
● Unsupervised Approaches
Equal-width discretization
روش گسسته سازی عرض برابر، این روش اساس رسم هیستوگرام ها است، در هیستوگرام ها نرم افزار داده ها را به (25 تا معموماً) کلاس همسان تقسیم می کند و سپس نمودار را رسم می کند.
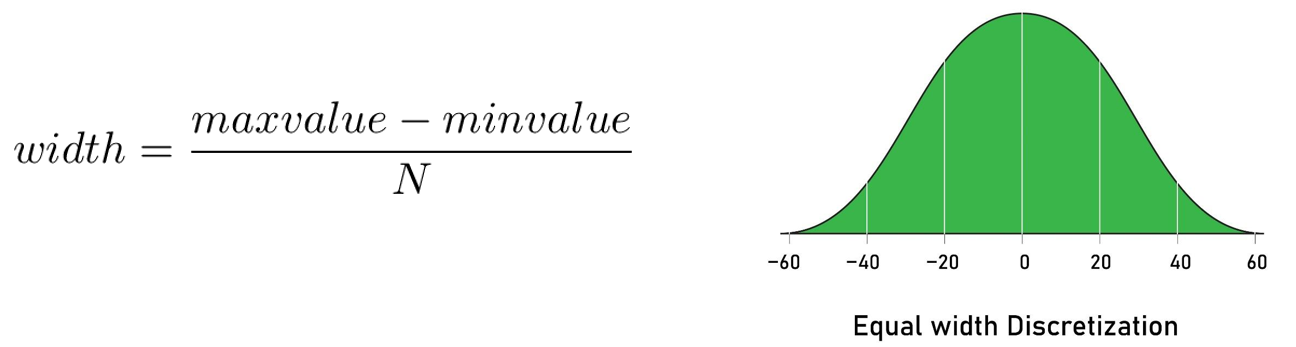
Equal-frequency discretization
در این روش جداسازی به شکلی انجام می شود که فراوانی در گروه ها یکسان شود، عملا نرم افزار بر اساس چندک ها عمل می نماید. یعنی علی رغم روش قبلی عرض رده ها یکسان نیست.
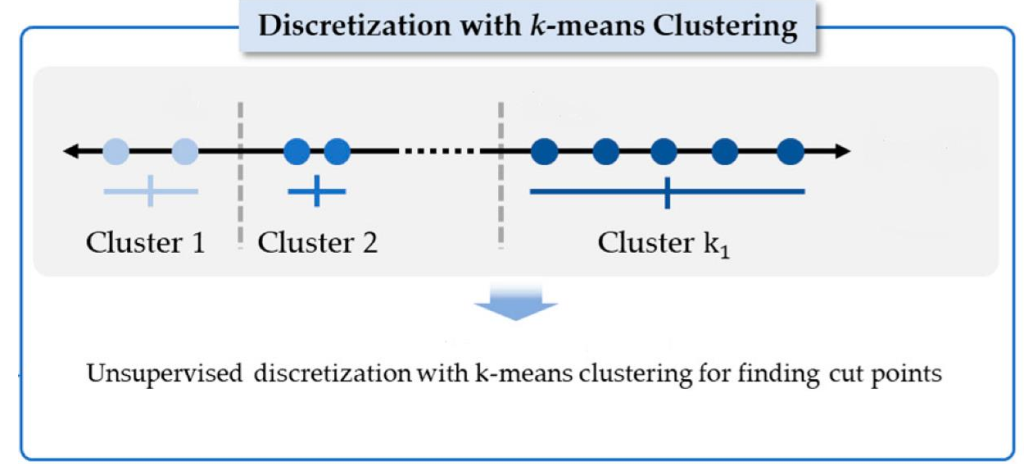
K-means discretization
خوشهبندی K-میانگین (k-means clustering) روشی در کمیسازی بردارهاست که در اصل از پردازش سیگنال گرفته شده و برای آنالیز خوشه بندی در داده کاوی محبوب است. کی-میانگین خوشهبندی با هدف تجزیه n مشاهدات به k خوشه است که در آن هر یک از مشاهدات متعلق به خوشه ای با نزدیکترین میانگین آن است، این میانگین به عنوان پیشنمونه استفاده میشود. این به پارتیشنبندی دادههای به یک دیاگرام ورونوی تبدیل میشود.
الگوریتم k-میانگین یکی از سادهترین و محبوبترین الگوریتمهایی است که در دادهکاوی (Data Mining) بخصوص در حوزه یادگیری نظارت نشده (Unsupervised Learning) به کار میرود.
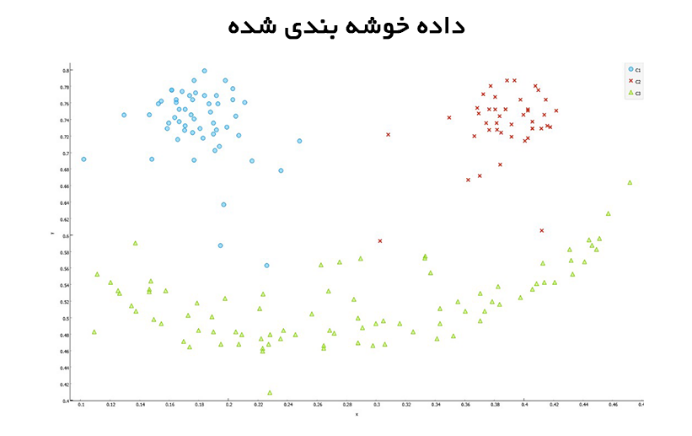
● Supervised Approach
در این روش گسسته سازی داده ها با در نظر گرفتن هدف انجام می شود و عملا فیلد هدف راهنمایی خواهد بود تا بیان کند داده ها چطور خوشه بندی شوند.
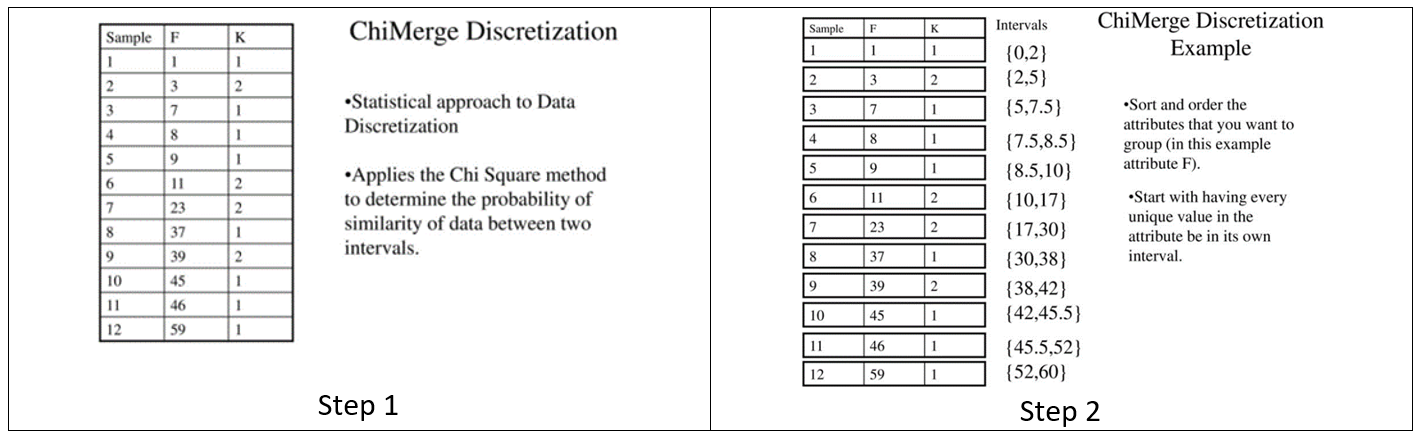
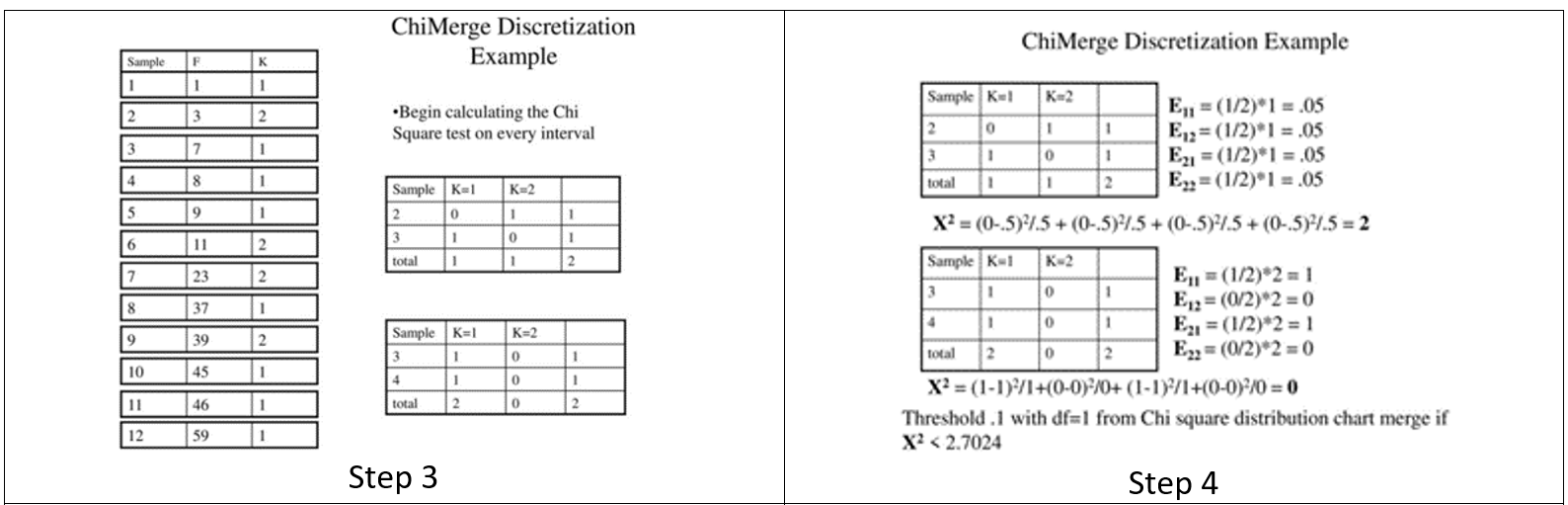
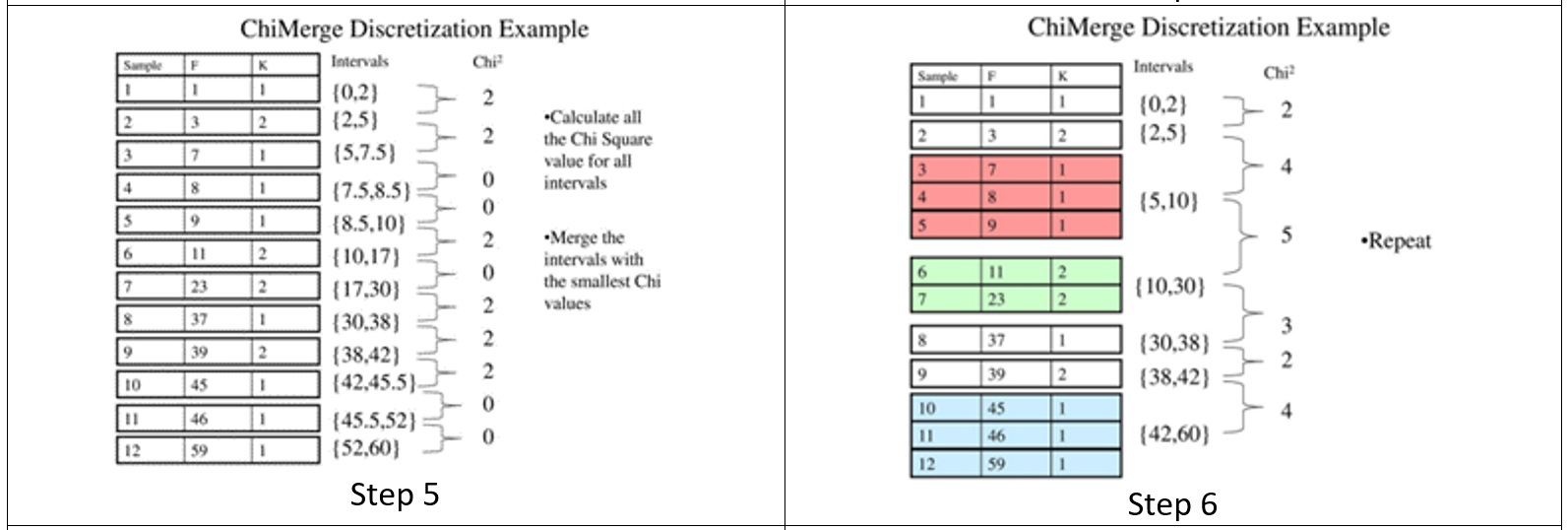
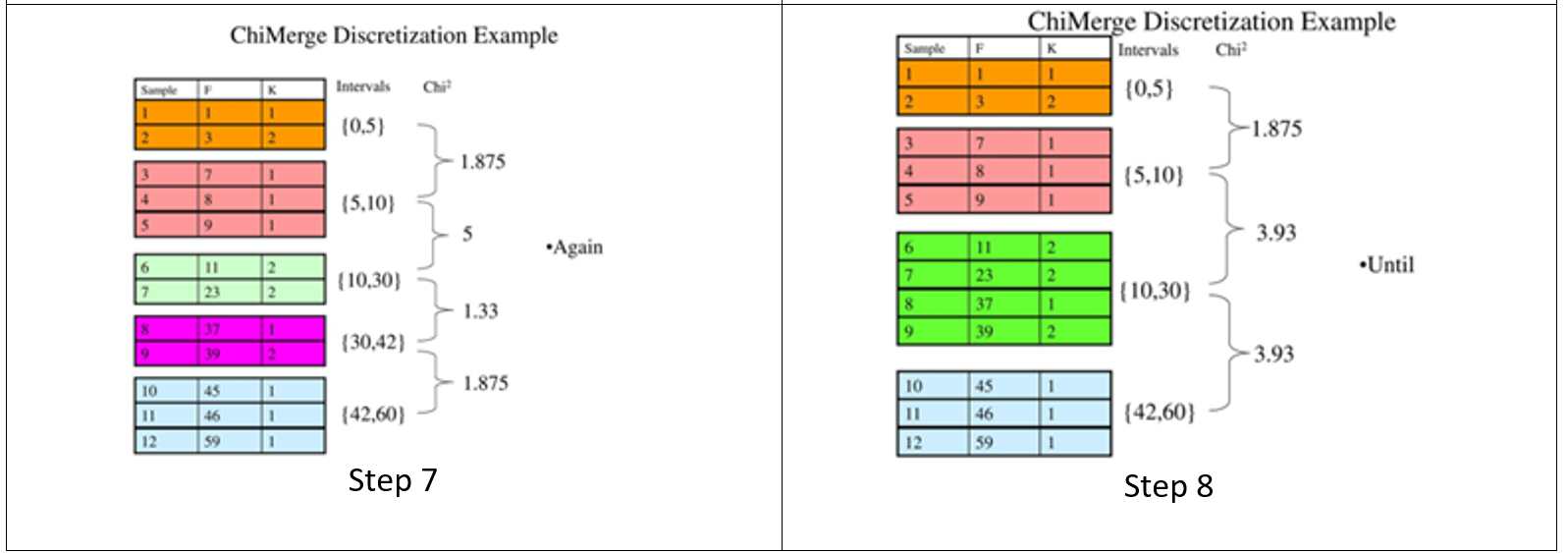
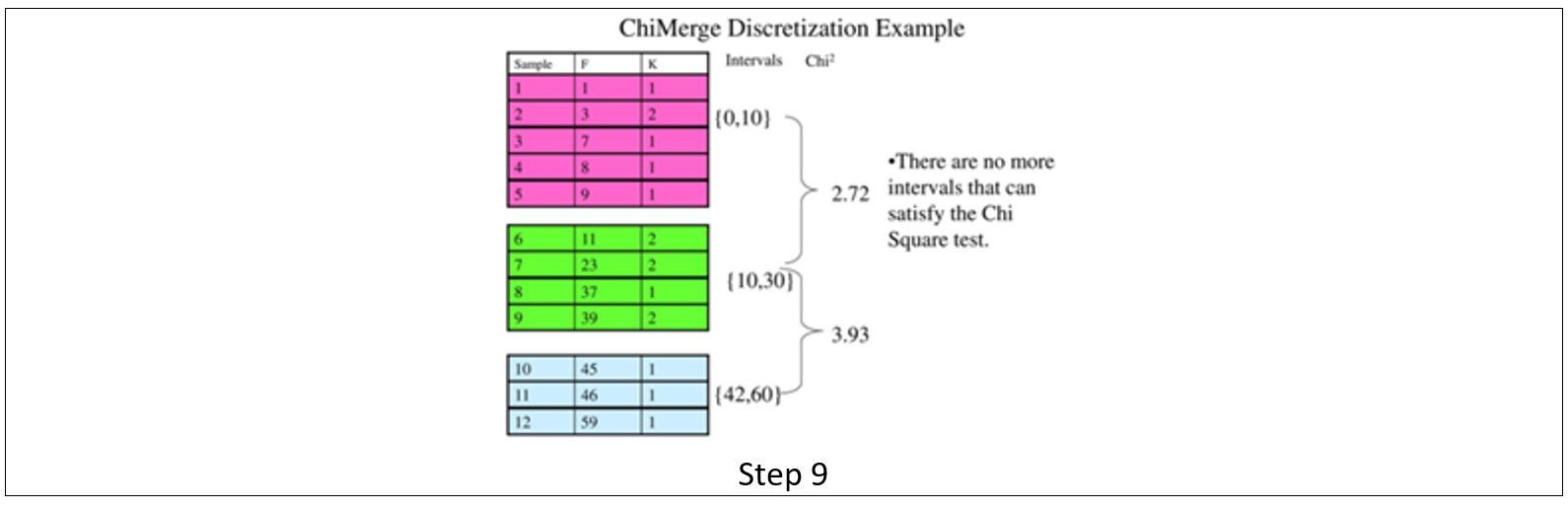
Discretization with correlation (ChiMerge Alg.)
این روش با استفاده از رویکرد آماری و استفاده از Chi-Square احتمال شباهت دو داده را محاسبه می کند.
این رویکرد به صورت هدایت شده بر اساس برچسب کلاس هدف، با ادغام فواصل مجاوری که میزان x2 کوچکی دارند ادامه پیدا میکند تا در نهایت دسته هایی را با توزیع آماری متمایز از برچسب کلاس هدف ایجاد نماید.
o Discretization with decision trees
گسستهسازی با درختهای تصمیم شامل استفاده از درخت تصمیم برای شناسایی نقاط تقسیم بهینه است که فواصل پیوسته را تعیین میکند:
مرحله 1: ابتدا یک درخت تصمیم با عمق محدود (2، 3 یا 4) را با استفاده از متغیری که میخواهیم گسسته سازی کنیم تا هدف را پیشبینی کنیم، آموزش میدهد.
مرحله 2: سپس مقادیر متغیر اصلی با احتمال برگردانده شده توسط درخت جایگزین می شوند.
بیشبرازش (Overfitting)
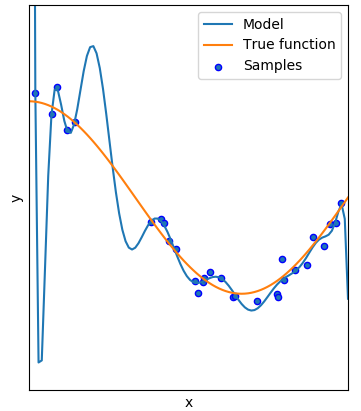
مدل بیشبرازش، مدلی بسیار پیچیده برای دادهها است. به این معنی که در تحلیل رگرسیونی، مدلی با بیشترین پارامترها ایجاد میشود. در چنین حالتی، مدل با تغییرات جهشی سعی در پوشش دادههای حاصل از نمونه و حتی مقدارهای نویز میکند. در حالیکه چنین مدلی باید منعکس کننده رفتار جامعه باشد. در این گونه موارد، اگر مدل رگرسیون بدست آمده، برای پیشبینی نمونه دیگری به کار رود، مقدارهای پیشبینی شده اصلا مناسب به نظر نخواهند رسید.
در تصویر زیر نمودار حاصل از بیشبرازش روی دادههای حاصل از نمونه دیده میشود. خط آبی، نشان دهنده منحنی برازش شده روی دادهها است و خط نارنجی تابعی است که مدل واقعی جامعه آماری را نشان میدهد. نقاط آبی رنگ نیز نمونههای تصادفی از جامعه آماری را نشان میدهند. در مدل بیشبرازش، نقطههای حاصل از نمونه بهترین برازش را دارند و خط آبی تقریباً از همه آنها عبور کرده است.