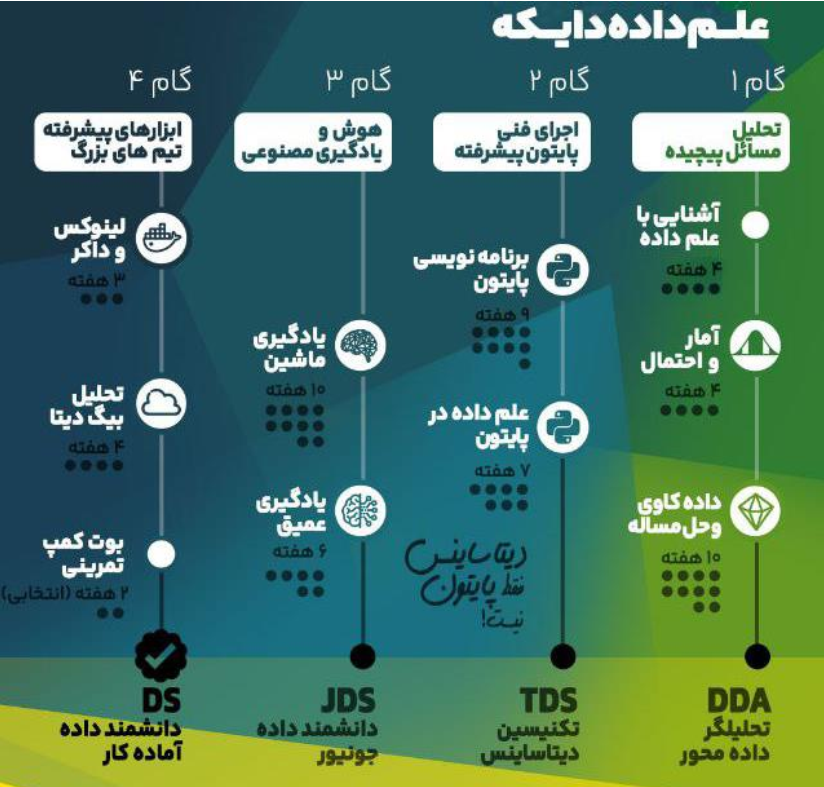
معرفی مسیر جامع:
مسیر جامع علم داده در دایکه بر اساس نیازهای بازار کار و اهداف شغلی دانشجویان طراحی شده است. این مسیر شامل چهار گام اساسی است که هرکدام از آنها با هدف دستیابی به دستاوردهای ملموس در انتهای هر مرحله طراحی شدهاند. استاد توضیح میدهد که این مسیر بهگونهای طراحی شده است که محتواها و کورسهای مختلف به شکل هدفمند و در یک خط سیر مشخص با یکدیگر مرتبط باشند.
هدف مسیر:
- آمادهسازی دانشجویان برای ورود به پوزیشنهای شغلی مانند دیتا ساینتیست.
- تمرکز بر مهارتهای تحلیلی و ابزارهای مورد نیاز برای حل مسائل دادهمحور.
- ایجاد توانمندی در تبدیل مسائل بیزینسی به مسائل قابل حل توسط علم داده.
ساختار کلی:
مسیر جامع شامل چهار گام اصلی و ۹ کورس است. هر گام به شکلی طراحی شده که دانشجو در انتهای آن بتواند با مهارتها و دانش کسبشده، وارد سطح مشخصی از بازار کار شود:
- گام اول: تمرکز بر مهارتهای حل مسئله و ایجاد توانمندی ورود به تیمهای دیتا ساینس.
- گام دوم: تقویت مهارتهای کدنویسی و کار با ابزارهای تحلیلی مانند پایتون.
- گام سوم: یادگیری ماشین و یادگیری عمیق برای تحلیل دادههای پیچیده.
- گام چهارم: تسلط بر ابزارهای پیشرفته و زیرساختهای حرفهای داده مانند لینوکس، داکر، و پایگاههای داده توزیعشده.

گام اول – حل مسئله دادهمحور
اهمیت گام اول:
گام اول بهعنوان قلب مسیر جامع علم داده شناخته میشود. در این مرحله، بیش از ۵۰ درصد مهارتها و دانش مورد نیاز برای ورود به بازار کار پوشش داده میشود. دانشجویان یاد میگیرند که چگونه مسائل بیزینسی را به مسائل علم داده تبدیل کنند و فرآیند حل آنها را بهدرستی مدیریت کنند.
محوریت حل مسئله:
- تمرکز اصلی این گام بر یادگیری هنر حل مسئله دادهمحور است.
- ابزارها و تکنیکهای مورد استفاده در اولویت دوم قرار دارند.
- دانشجو باید بتواند ارزش افزوده ایجاد کند و مسائل را بهدرستی تحلیل و حل کند.
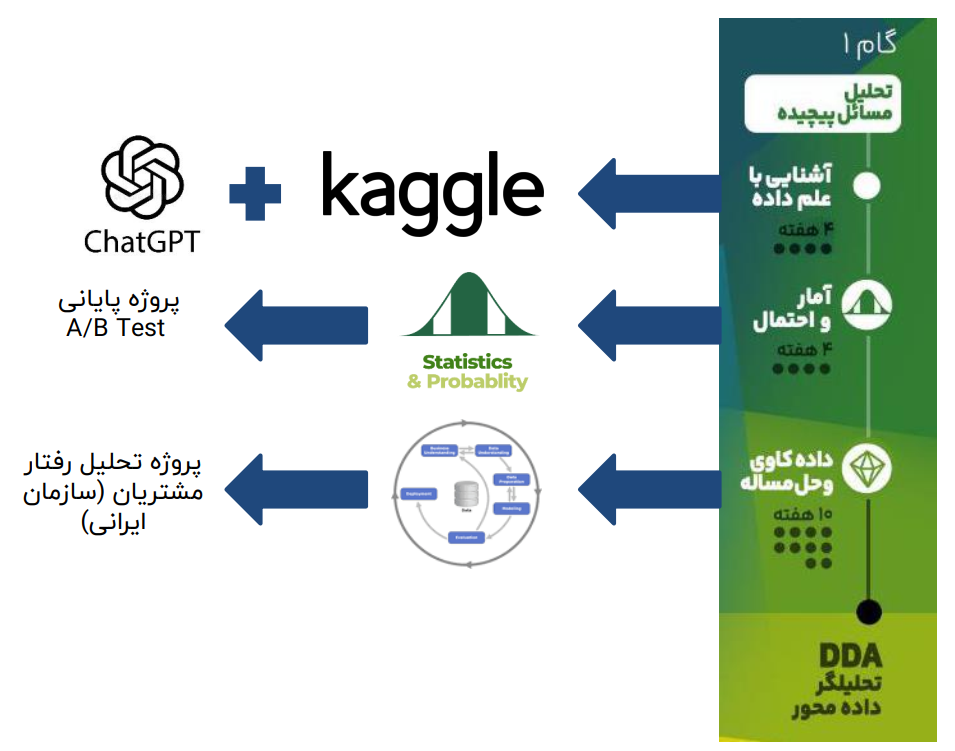
ابزارهای استفادهشده:
- چت جیپیتی (ChatGPT):
- یک دستیار هوشمند که در تمام مراحل یادگیری و حل مسائل همراه دانشجو خواهد بود.
- امکان رفع اشکال، ارائه کدهای پیشنهادی، و بهبود کیفیت کار را فراهم میکند.
- کگل (Kaggle):
- پلتفرمی جهانی برای کار با داده و انجام پروژههای علمی.
- امکان ایجاد پروفایل حرفهای و مستندسازی دستاوردها.
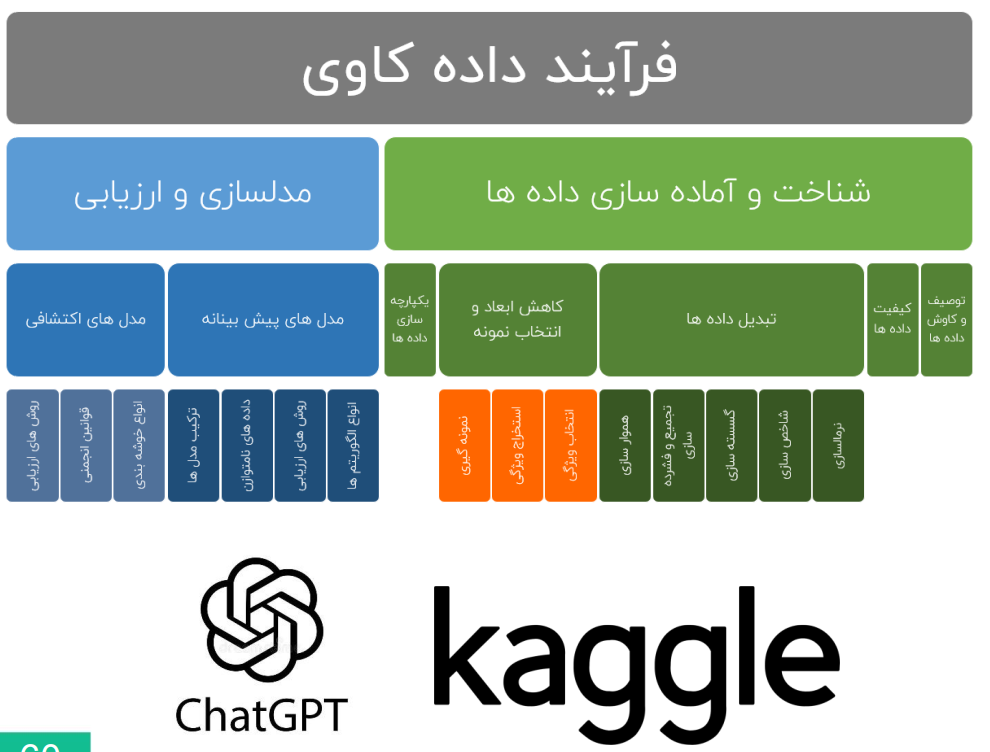
کورسهای اصلی گام اول:
- آشنایی با علم داده:
- یادگیری ابزارهای اولیه مانند چت جیپیتی و کگل.
- تمرین حل مسائل بهصورت عملی و پرکتیس.
- آمار و احتمال:
- یادگیری مفاهیم آماری مورد نیاز برای تحلیل داده.
- اجرای پروژههایی مانند A/B Testing.
- دادهکاوی و حل مسئله:
- یادگیری فرآیند کامل حل مسئله از شناخت داده تا ارزیابی مدل.
- انجام پروژههای واقعی مانند تحلیل رفتار مشتریان.
دستاوردهای گام اول:
- توانایی ورود به تیمهای دیتا ساینس بهعنوان تحلیلگر دادهمحور.
- ایجاد رزومه فنی در پلتفرم کگل.
- آمادگی برای حل مسائل دادهمحور با استفاده از تکنیکها و ابزارهای حرفهای.
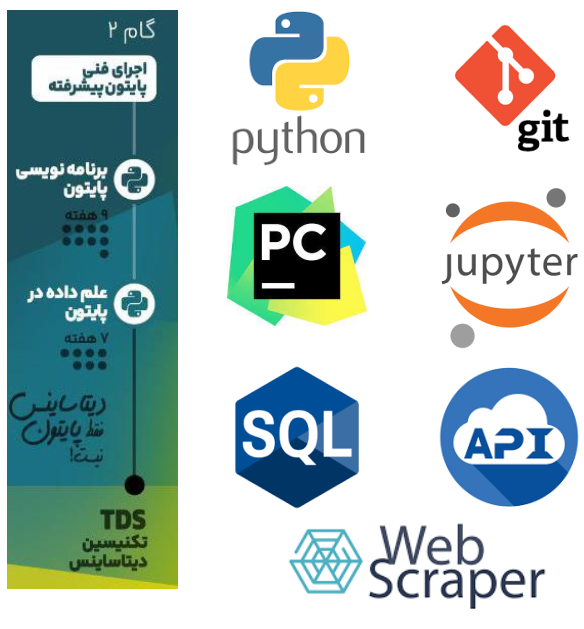
گام دوم – تقویت مهارتهای برنامهنویسی و ابزارهای تحلیلی
هدف گام دوم:
در این گام، دانشجویان مهارتهای برنامهنویسی و کار با ابزارهای تحلیلی را به سطح بالاتری میرسانند. تمرکز اصلی بر یادگیری پایتون و ابزارهای مرتبط است تا دانشجو بتواند بهعنوان تکنسین علم داده فعالیت کند. این مرحله برای تسلط بیشتر بر ابزارها و آمادهسازی برای پروژههای پیچیدهتر طراحی شده است.
ویژگیهای گام دوم:
- ارتقای توانایی کدنویسی با پایتون و بهینهسازی عملکرد کدها.
- آشنایی با انواع دیتا سورسها و نحوه استفاده از آنها در پروژههای دادهمحور.
- یادگیری ابزارهایی برای کار تیمی و مدیریت کدها.
موضوعات کلیدی:
- برنامهنویسی پیشرفته با پایتون:
- یادگیری اصول برنامهنویسی پایتون برای علم داده.
- نوشتن کدهایی با کیفیت بالا و بهینه برای پروژههای بزرگ.
- کار با کتابخانههای تخصصی پایتون برای پردازش داده، مانند pandas و NumPy.
- مدیریت منابع داده:
- یادگیری نحوه واکشی داده از منابع مختلف:
- پایگاههای داده مبتنی بر SQL (مانند MySQL).
- پایگاههای داده NoSQL (مانند MongoDB).
- APIها برای واکشی داده از وب.
- وب اسکرپینگ برای جمعآوری دادههای آنلاین.
- یادگیری نحوه واکشی داده از منابع مختلف:
- ابزارهای مدیریت پروژه و تیم:
- آشنایی با Git برای مدیریت نسخهها و کار گروهی.
- یادگیری نحوه استفاده از ابزارهای توسعه حرفهای مانند PyCharm و Jupyter Notebook.
ساختار کورسها:
- برنامهنویسی مقدماتی پایتون:
- تمرکز بر مفاهیم پایه برنامهنویسی و حل مسائل ساده.
- آشنایی با نحوه استفاده از محیطهای توسعه (IDEها).
- برنامهنویسی پیشرفته پایتون:
- کار با ساختارهای پیچیده داده، مدیریت خطاها و بهینهسازی کد.
- توسعه اسکریپتهایی برای واکشی داده از منابع مختلف.
- کار با SQL و پایگاههای داده:
- یادگیری نحوه طراحی و کوئرینویسی در پایگاههای داده.
- آشنایی با ابزارهای پیشرفته برای مدیریت دادههای ساختاریافته.
- کار با دادههای غیرساختاریافته:
- واکشی و تحلیل دادههای متنی، تصویری و سایر دادههای غیرساختاریافته.
دستاوردهای گام دوم:
- توانایی نوشتن کدهای حرفهای و بهینه در پایتون.
- تسلط بر واکشی و مدیریت داده از منابع متنوع.
- آمادگی برای کار در محیطهای حرفهای و پروژههای تیمی.
گام دوم دانشجو را به یک تکنسین علم داده تبدیل میکند که توانایی کار با ابزارهای متنوع و حل مسائل پیچیده را دارد.
گام سوم – یادگیری ماشین و یادگیری عمیق
هدف گام سوم:
در این گام، دانشجویان مهارتهای پیشرفتهتر در یادگیری ماشین و یادگیری عمیق را کسب میکنند. تمرکز اصلی بر تسلط بر الگوریتمها و مدلهای پیشرفته است تا دانشجو به یک جونیور دیتا ساینتیست تبدیل شود. در این مرحله، دانشجویان از ابزارهای یادگیری ماشین برای حل مسائل پیچیدهتر استفاده میکنند و مفاهیم پیشرفته را با پروژههای واقعی تجربه میکنند.
ویژگیهای گام سوم:
- یادگیری عمیق مفاهیم و تئوریهای الگوریتمهای یادگیری ماشین.
- تمرکز بر دادههای غیرساختاریافته مانند متن، تصاویر و صدا.
- درک عمیقتر از ریاضیات و بهینهسازی برای طراحی و بهبود مدلها.
موضوعات کلیدی:
- یادگیری ماشین (Machine Learning):
- مرور الگوریتمهای پایهای مانند رگرسیون خطی و لجستیک.
- آشنایی با الگوریتمهای پیشرفتهتر مانند جنگل تصادفی، SVM و KNN.
- یادگیری روشهای کاهش ابعاد مانند PCA.
- درک فرآیند ارزیابی مدلها و بهینهسازی آنها.
- ریاضیات و بهینهسازی:
- یادگیری مبانی جبر خطی و حسابان برای درک بهتر مدلهای یادگیری ماشین.
- مطالعه روشهای بهینهسازی مانند گرادیان کاهشی (Gradient Descent).
- یادگیری عمیق (Deep Learning):
- آشنایی با شبکههای عصبی مصنوعی (ANN) و معماریهای پیشرفته مانند CNN و RNN.
- تحلیل و پردازش دادههای متنی (NLP) و دادههای تصویری.
- یادگیری نحوه آموزش مدلهای یادگیری عمیق با استفاده از ابزارهایی مانند TensorFlow و PyTorch.
ساختار کورسها:
- یادگیری ماشین:
- تمرکز بر مبانی و پیادهسازی الگوریتمهای پایه.
- پروژههایی برای ارزیابی و انتخاب مدل مناسب برای مسائل مختلف.
- یادگیری عمیق:
- طراحی و آموزش شبکههای عصبی برای دادههای پیچیده.
- کار با دادههای تصویری و متنی در پروژههای واقعی.
- پروژههای عملی:
- حل مسائل واقعی با دادههای غیرساختاریافته.
- تحلیل رفتار مشتری، طبقهبندی تصاویر و پردازش زبان طبیعی.
دستاوردهای گام سوم:
- درک عمیق الگوریتمهای یادگیری ماشین و یادگیری عمیق.
- توانایی حل مسائل پیچیده با استفاده از دادههای ساختاریافته و غیرساختاریافته.
- کسب تجربه در استفاده از ابزارهای پیشرفته مانند TensorFlow و PyTorch.
گام سوم به دانشجویان کمک میکند تا از یک تکنسین علم داده به یک جونیور دیتا ساینتیست تبدیل شوند و آماده ورود به پروژههای پیچیدهتر شوند.
گام چهارم – مهارتهای پیشرفته و ابزارهای زیرساختی
هدف گام چهارم:
این گام برای آشنایی با ابزارها و فناوریهای پیشرفته طراحی شده است که در محیطهای حرفهای و تیمهای بزرگ مورد نیاز است. دانشجویان در این مرحله با مفاهیمی مانند مدیریت زیرساختهای داده، استفاده از ابزارهای توزیعشده، و بهینهسازی کدها آشنا میشوند. گام چهارم بهعنوان چاشنی تکمیلی مسیر جامع، دانشجویان را برای ورود به سطوح پیشرفتهتری از دیتا ساینس آماده میکند.
ویژگیهای گام چهارم:
- یادگیری ابزارهای تخصصی مورد نیاز برای مدیریت دادههای حجیم و توزیعشده.
- آشنایی با زیرساختهای مرتبط با بیگ دیتا و تحلیل داده در محیطهای مقیاسپذیر.
- آمادگی برای کار در محیطهای حرفهای با استفاده از لینوکس و داکر.
موضوعات کلیدی:
- لینوکس و مدیریت سیستم:
- یادگیری اصول لینوکس و استفاده از خط فرمان برای مدیریت سیستمها.
- آشنایی با زیرساختهای سازمانی مبتنی بر لینوکس.
- داکر و کانتینرها:
- درک مفاهیم داکر و کانتینریسازی کدها.
- یادگیری نحوه داکرایز کردن پروژهها برای استقرار در محیطهای مختلف.
- بیگ دیتا و تحلیل دادههای حجیم:
- آشنایی با ابزارهای بیگ دیتا مانند Apache Spark و Hadoop.
- کار با پایگاههای داده توزیعشده مانند HBase و MongoDB.
- یادگیری اصول کار با NoSQL و مقایسه آن با پایگاههای داده سنتی.
- کار با دادههای توزیعشده:
- استفاده از Spark SQL برای تحلیل دادهها.
- آشنایی با مفاهیم پردازش موازی و توزیعشده.

ساختار کورسها:
- لینوکس و اصول مدیریت سیستم:
- یادگیری دستورات اصلی لینوکس.
- مدیریت فایلها و فرآیندها در محیطهای لینوکسی.
- کار با داکر:
- ایجاد و مدیریت کانتینرها.
- استقرار پروژهها در محیطهای عملیاتی با استفاده از داکر.
- بیگ دیتا و ابزارهای توزیعشده:
- استفاده از Spark برای پردازش دادههای حجیم.
- یادگیری نحوه مدیریت پایگاههای داده NoSQL مانند MongoDB و HBase.
دستاوردهای گام چهارم:
- توانایی کار در زیرساختهای حرفهای و سازمانی.
- آشنایی با ابزارهای بیگ دیتا و مدیریت دادههای حجیم.
- تسلط بر مفاهیم و ابزارهای کانتینریسازی و پردازش موازی.
جمعبندی گام چهارم:
گام چهارم تکمیلکننده مسیر جامع علم داده است و دانشجویان را برای فعالیت در محیطهای حرفهای و تیمهای بزرگ آماده میکند. این گام با ارائه ابزارها و مهارتهای پیشرفته، امکان انجام پروژههای دادهمحور در مقیاس سازمانی را فراهم میکند.