
ما تا اینجا درباره کلیات دیتا ساینس صحبت کردیم و با متدولوژی CRISP-DM آشنا شدیم؛ چارچوبی که به ما نشان میدهد چگونه از نقطه صفر شروع کنیم، مسئله را تعریف کنیم و قدمبهقدم پیش برویم تا آن مسئله را حل کنیم. اکنون وارد یکی از مهمترین بخشهای یادگیری علم داده میشویم: اجرای عملی اولین پروژه.
در این مسیر قرار است با یک مسئله واقعی روبهرو شویم، آن را تعریف کنیم و مراحل حل آن را مطابق با سناریوها و فرآیندهایی که قبلاً توضیح داده شد، پیش ببریم. هدف این است که یاد بگیریم چگونه از تئوری به عمل برسیم و با چالشهای واقعی حل مسئله مواجه شویم.
ضرورت اجرای پروژه عملی
تا کمتر از یک سال پیش، انجام چنین پروژهای در یک دوره آموزشی بسیار دشوار بود، زیرا معمولاً این سؤالات پیش میآمد:
- چگونه بدون دانستن تمام تکنیکها و روشها میتوانیم مسئله را حل کنیم؟
- اگر ابزارهای لازم را نمیشناسیم، چطور باید از آنها استفاده کنیم؟
- چگونه بدون دانش برنامهنویسی یا نصب نرمافزارهای خاص پروژهای را پیادهسازی کنیم؟
اما خوشبختانه امروز، به لطف پیشرفت تکنولوژی، مخصوصاً تکنولوژیهای مبتنی بر هوش مصنوعی، پاسخ این سؤالات سادهتر شده است. ابزارهای هوشمندی وجود دارند که میتوانند بهعنوان دستیار کنار ما باشند، راهنمایی کنند، کد بنویسند، و حتی برخی مراحل اجرا را انجام دهند. این ابزارها به ما اجازه میدهند بدون نگرانی از کمبود دانش فنی یا سختافزار مناسب، پروژهها را اجرا کنیم.
اهمیت یادگیری ابزارهای هوش مصنوعی
داشتن یک دستیار هوشمند میتواند فرآیند یادگیری و اجرای پروژهها را بسیار تسهیل کند. این ابزارها به شما اجازه میدهند:
- بدون نیاز به نصب نرمافزارهای خاص یا تهیه لپتاپهای قدرتمند، پروژه را اجرا کنید.
- با استفاده از پلتفرمهای آنلاین کدنویسی کنید و دادهها را تحلیل کنید.
- از تجربیات و راهنماییهای این دستیارها برای تصمیمگیریهای بهتر استفاده کنید.
این امکانات نهتنها در یادگیری مقدماتی کمک میکنند، بلکه در مسیر پیشرفتهتر و حتی در آینده شغلی شما نیز نقش بسیار مهمی دارند.
دو هدف اصلی این بخش از دوره
- درک فرآیند حل مسئله:
در این بخش، میخواهیم فرآیند حل مسئله را که قبلاً بهصورت تئوری توضیح دادیم، بهصورت عملی تجربه کنیم. از تعریف مسئله تا حل آن و مشاهده رفتوبرگشتها در مسیر حل مسئله. - آشنایی با تکنیکها و روشها:
در طول اجرای پروژه، با تکنیکها و ابزارهایی آشنا میشویم که در حوزه اجرا و تصمیمگیری به کار میروند. این آشنایی به ما کمک میکند که هنگام مطالعه مباحث پیشرفتهتر، درک بهتری از کاربرد آنها داشته باشیم.
شروع پروژه: تعریف مسئله
برای اجرای پروژه، یک سناریوی شبیهسازی شده طراحی شده است. فرض کنید شما بهعنوان یک متخصص دیتا ساینس به کلینیکی مراجعه کردهاید. مدیر کلینیک درباره مزایای دیتا ساینس شنیده است و اکنون به شما مراجعه کرده تا از دادههای موجود استفاده کنید و ارزش افزودهای برای کلینیک ایجاد کنید.
دادههایی که در اختیار دارید شامل اطلاعات پزشکی بیماران است: سن، جنسیت، فشار خون، کلسترول، میزان سدیم و پتاسیم در خون، و داروی تجویز شده. فرض بر این است که هر بیمار تنها یک دارو دریافت کرده است. مدیر از شما میپرسد: «چه مسئلهای میتوانیم با این دادهها حل کنیم که ارزش افزودهای برای کلینیک داشته باشد؟»
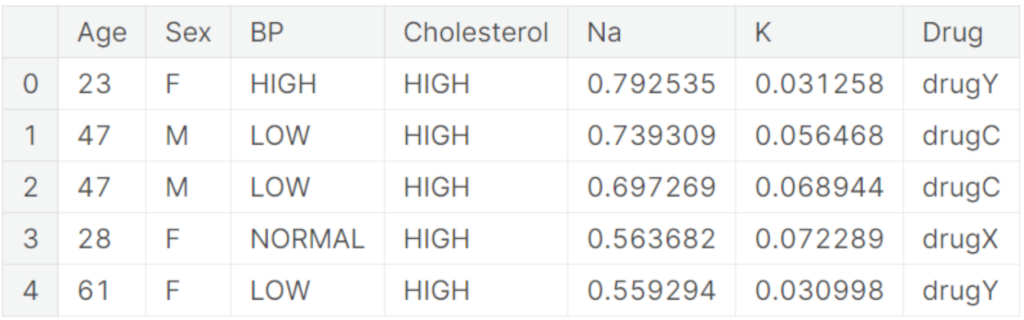
در ادامه، به توضیح دقیق فرآیند تعریف مسئله، روشهای تحلیل داده، و چگونگی یافتن راهحل میپردازیم. این بخش به شما نشان میدهد چگونه میتوانید بهعنوان یک دیتا ساینتیست مسئله را تعریف و راهکارهایی برای حل آن ارائه کنید.
تعریف دقیق مسئله
تعریف مسئله یکی از مهمترین مراحل اجرای پروژههای دیتا ساینس است. در سناریوی شبیهسازیشده کلینیک، شما باید ابتدا مسئلهای را که ارزش افزودهای برای کسبوکار ایجاد میکند، شناسایی و تعریف کنید.
در پروژههای واقعی، ممکن است این تعریف مسئله توسط مدیر کسبوکار انجام نشود، زیرا در بسیاری از سازمانها بلوغ لازم برای مشخص کردن چنین مسئلهای وجود ندارد. به همین دلیل، شما بهعنوان یک متخصص دیتا ساینس باید توانایی داشته باشید که از دادهها و شرایط موجود برای تعریف یک مسئله مناسب استفاده کنید.
رویکرد مهندسی معکوس در تعریف مسئله
یکی از روشهای مفید در این مرحله، استفاده از رویکرد مهندسی معکوس است. به این معنا که ابتدا به تسکها و اهدافی که میخواهید به آنها برسید فکر کنید و سپس به عقب برگردید تا ببینید آیا دادههای موجود میتوانند این اهداف را پشتیبانی کنند یا نه.
مثالهایی برای تعریف مسئله:
- تحلیل توزیع داروهای تجویز شده:
بررسی کنید که چه داروهایی بیشتر تجویز شدهاند. این تحلیل میتواند به مدیریت انبار و سفارشگذاری دارو کمک کند. - تحلیل جنسیت بیماران:
مشاهده کنید که چه درصدی از بیماران مرد یا زن هستند. این اطلاعات میتواند در استراتژیهای مارکتینگ کلینیک مورد استفاده قرار گیرد. - بررسی سن بیماران:
تحلیل کنید که چه ردههای سنی بیشتر به کلینیک مراجعه میکنند. این اطلاعات میتواند برای برنامهریزیهای آینده و همچنین بهبود خدمات مفید باشد. - شناخت الگوهای بیماری:
تحلیل کنید که آیا الگوهای خاصی در دادههای بیماران وجود دارد یا نه. مثلاً آیا بیماران با فشار خون بالا معمولاً داروی خاصی دریافت میکنند؟

ارزش افزوده در پروژههای دیتا ساینس
ارزش افزوده زمانی خلق میشود که پیشبینی یا تحلیلی که انجام میدهید، بتواند هزینهها را کاهش دهد، درآمد را افزایش دهد، یا تصمیمگیریها را بهبود بخشد. برای مثال:
- اگر بتوانید الگوی مشخصی از بیماریهایی که در فصول خاصی افزایش مییابند، شناسایی کنید، کلینیک میتواند آمادگی بیشتری داشته باشد.
- اگر بتوانید پیشبینی کنید که چه دارویی برای چه گروهی از بیماران بهتر عمل میکند، این پیشبینی میتواند به بهبود درمان کمک کند.

تحلیل دادهها و بررسی ارتباطات
پس از تعریف مسئله، نوبت به تحلیل دادهها میرسد. در این مرحله، باید بررسی کنید که آیا دادههای موجود میتوانند اطلاعات مورد نیاز برای حل مسئله را فراهم کنند یا نه. بهعنوان مثال:
- آیا ارتباط معناداری بین ویژگیهای بیماران (مانند سن، جنسیت، فشار خون) و داروی تجویز شده وجود دارد؟
- آیا دادهها بهطور کامل و دقیق جمعآوری شدهاند؟
نکته مهم در تعریف ستون هدف
هنگامی که مسئلهای را برای پیشبینی تعریف میکنید (مانند پیشبینی داروی تجویز شده)، باید مطمئن شوید که ستون هدف (Target Column) ارزش پیشبینی داشته باشد. بهعنوان مثال:
- پیشبینی سنی که بیمار در فرم خود پر کرده است، بیفایده است، زیرا این اطلاعات از قبل وجود دارد.
- اما پیشبینی داروی مناسب برای یک گروه خاص از بیماران، میتواند ارزشمند باشد، زیرا به تصمیمگیری بهتر کمک میکند.
تحلیل اکتشافی دادهها (EDA)
تحلیل اکتشافی دادهها (Exploratory Data Analysis یا EDA) یکی از مراحل حیاتی در هر پروژه دیتا ساینس است. این مرحله به شما کمک میکند تا دادههای خود را بهتر بشناسید، الگوهای پنهان را کشف کنید و ناهماهنگیها یا مشکلات موجود در دادهها را شناسایی کنید.
EDA معمولاً شامل مراحل زیر است:
- بررسی کلی دادهها:
شامل مشاهده تعداد رکوردها، نوع دادهها، و ویژگیهای موجود. - خلاصهسازی آماری:
محاسبه مقادیری مانند میانگین، میانه، و انحراف معیار برای درک بهتر توزیع دادهها. - بررسی دادههای گمشده:
شناسایی و جایگزینی دادههای گمشده یا ناقص. - مصورسازی دادهها:
استفاده از نمودارهایی مانند هیستوگرام، جعبهای (Boxplot)، و پراکندگی (Scatterplot) برای نمایش توزیع و روابط بین متغیرها.
مثال از تحلیل دادههای کلینیک
فرض کنید دادههای شما شامل اطلاعات زیر است:
- سن بیماران
- جنسیت
- فشار خون
- میزان کلسترول
- میزان سدیم و پتاسیم
- داروی تجویز شده
گامهای تحلیل اکتشافی:
- مشاهده دادهها:
ابتدا دادهها را بررسی کنید تا مطمئن شوید که هیچ مشکلی در ساختار دادهها وجود ندارد. آیا همه ستونها کامل هستند؟ آیا مقادیر غیرمنطقی وجود دارد؟ - بررسی توزیع ویژگیها:
- میانگین سن بیماران چقدر است؟
- آیا میزان فشار خون بیماران طبیعی است یا بیشترین مقدارها از محدوده طبیعی خارج شده است؟
- رسم نمودارها:
- با استفاده از نمودار هیستوگرام، توزیع سنی بیماران را بررسی کنید.
- نمودار جعبهای میزان کلسترول بیماران را نشان میدهد که آیا مقادیر غیرمعمول وجود دارد یا نه.
- ارتباط بین ویژگیها:
با استفاده از نمودار پراکندگی، رابطه بین فشار خون و میزان سدیم را بررسی کنید. آیا ارتباطی واضح بین این دو متغیر وجود دارد؟
آمادهسازی دادهها برای مدلسازی
بعد از تحلیل اکتشافی، دادهها باید برای مدلسازی آماده شوند. این مرحله شامل:
- تمیز کردن دادهها:
حذف یا جایگزینی مقادیر گمشده و اصلاح دادههای ناهماهنگ. - استانداردسازی دادهها:
نرمالسازی مقادیر برای اطمینان از مقیاس مشابه بین ویژگیها. - ایجاد ویژگیهای جدید:
استخراج یا محاسبه متغیرهای جدید که ممکن است در پیشبینی بهتر کمک کنند. - تقسیم دادهها:
تقسیم دادهها به دو مجموعه:- آموزشی (Training): برای ساخت مدل استفاده میشود.
- آزمایشی (Testing): برای ارزیابی عملکرد مدل.
اهمیت این مراحل
این مراحل نهتنها برای درک بهتر دادهها و آمادگی برای مدلسازی ضروری هستند، بلکه کمک میکنند تا از مشکلات احتمالی در مراحل بعدی جلوگیری شود.
مدلسازی و ارزیابی
پس از آمادهسازی دادهها، وارد مرحله مدلسازی میشویم. این مرحله شامل ساخت مدلهای پیشبینی و ارزیابی عملکرد آنهاست. هدف اصلی این است که مدلی بسازیم که بتواند بر اساس دادههای ورودی (ویژگیها یا Features)، خروجی (هدف یا Target) را با دقت بالا پیشبینی کند.
مراحل مدلسازی
- انتخاب نوع مدل:
با توجه به نوع مسئله، مدل مناسب را انتخاب میکنیم:- اگر هدف، پیشبینی یک مقدار عددی (مانند میزان پتاسیم) باشد، مدلهای رگرسیون (Regression) به کار میروند.
- اگر هدف، دستهبندی (مانند پیشبینی داروی مناسب برای بیمار) باشد، مدلهای دستهبندی (Classification) استفاده میشوند.
- آموزش مدل:
در این مرحله، دادههای آموزشی به مدل داده میشوند تا الگوهای موجود در دادهها را یاد بگیرد. - ارزیابی مدل:
برای ارزیابی دقت مدل، دادههای آزمایشی را استفاده میکنیم و پیشبینیهای مدل را با مقادیر واقعی مقایسه میکنیم. معیارهایی که معمولاً برای ارزیابی استفاده میشوند:- دقت (Accuracy): درصد پیشبینیهای صحیح.
- خطای میانگین مربعات (MSE): برای مدلهای رگرسیون.
- F1-Score: برای بررسی تعادل بین دقت و یادآوری در مدلهای دستهبندی.
- بهینهسازی مدل:
- انتخاب ویژگی: بررسی کنید که کدام ویژگیها بیشترین تأثیر را در پیشبینی دارند و ویژگیهای غیرضروری را حذف کنید.
- تنظیم هایپرپارامترها: با استفاده از روشهایی مانند Grid Search یا Random Search، پارامترهای مدل را بهینه کنید.
مثال عملی: پیشبینی داروی مناسب
در پروژه کلینیک، فرض کنید هدف ما پیشبینی داروی مناسب برای بیماران است.
- ستون هدف (Target): داروی تجویز شده.
- ویژگیها (Features): سن، جنسیت، فشار خون، کلسترول، سدیم و پتاسیم.
فرآیند اجرا:
- مدل دستهبندی (Classification) را انتخاب میکنیم، مثلاً مدل Random Forest یا Logistic Regression.
- دادهها را به دو بخش آموزشی (70٪) و آزمایشی (30٪) تقسیم میکنیم.
- مدل را با استفاده از دادههای آموزشی آموزش میدهیم.
- دادههای آزمایشی را برای ارزیابی به مدل میدهیم و دقت پیشبینی را محاسبه میکنیم.
ارزیابی نتایج
- اگر دقت مدل پایین باشد، ممکن است دادهها نیاز به پیشپردازش بیشتری داشته باشند یا مدل مناسبتری انتخاب شود.
- اگر دقت مدل قابلقبول باشد، میتوان آن را در محیط واقعی به کار گرفت.
کاربرد مدل در محیط واقعی
در محیط کلینیک، مدل میتواند بهعنوان یک ابزار کمکی برای پزشکان عمل کند. مثلاً:
- پزشک میتواند از مدل بهعنوان پیشنهاددهنده دارو برای بیماران استفاده کند.
- مدیریت کلینیک میتواند از الگوهای شناساییشده برای بهبود خدمات و کاهش هزینهها بهرهبرداری کند.
نکات تکمیلی و توصیهها برای اجرای پروژههای دیتا ساینس
1. اهمیت درک مسئله پیش از شروع
یکی از چالشهایی که ممکن است در پروژههای واقعی با آن روبهرو شوید، نداشتن تعریف دقیق و روشن از مسئله است.
- در بسیاری از سازمانها، مدیران نمیتوانند مسئله را بهدرستی تعریف کنند. به همین دلیل، شما بهعنوان متخصص دیتا ساینس باید با پرسشهای هدفمند و تجزیهوتحلیل دادهها، مسئله مناسب را تعریف کنید.
- اگر سازمان بلوغ کافی در استفاده از دادهها نداشته باشد، ممکن است مجبور شوید ابتدا اهمیت استفاده از دادهها را برای مدیران توضیح دهید و آنها را متقاعد کنید که پروژه ارزشمند است.
2. تحلیل اکتشافی دادهها (EDA) بهعنوان پایهای محکم
همانطور که در مراحل قبلی توضیح داده شد، EDA نقش مهمی در شناخت دادهها و آمادهسازی آنها برای مدلسازی دارد.
- سؤالاتی که باید در این مرحله پاسخ داده شوند:
- آیا دادهها کامل و بدون خطا هستند؟
- آیا دادهها شامل مقادیر پرت یا غیرمنطقی هستند؟
- چه الگوهایی در دادهها وجود دارد؟
3. استفاده از ابزارهای مناسب
ابزارهایی که برای تحلیل و مدلسازی استفاده میکنید، نقش مهمی در موفقیت پروژه دارند. برای شروع:
- از زبان برنامهنویسی پایتون و کتابخانههای آن مانند Pandas، NumPy، و Scikit-learn استفاده کنید.
- برای مصورسازی دادهها، از Matplotlib و Seaborn بهره ببرید.
- اگر دسترسی به سیستم قوی ندارید، از پلتفرمهای آنلاین مانند Google Colab یا Kaggle استفاده کنید.

4. توجه به ارزش افزوده
همیشه به این نکته توجه کنید که خروجی پروژه شما باید یک ارزش واقعی برای کسبوکار ایجاد کند. بهعنوان مثال:
- اگر تحلیل شما به مدیریت انبار دارو کمک میکند و از اتلاف منابع جلوگیری میکند، این یک ارزش واقعی است.
- اگر پیشبینیهای مدل شما به پزشکان کمک میکند تا تصمیمات بهتری بگیرند، این میتواند تأثیر زیادی بر کیفیت خدمات داشته باشد.
پرسشهای کلیدی در طول پروژه
- آیا دادههای کافی برای حل مسئله در اختیار دارید؟
اگر دادههای شما ناقص یا کم باشد، باید از روشهایی مانند جمعآوری دادههای بیشتر یا تکمیل دادههای گمشده استفاده کنید. - چگونه اطمینان حاصل میکنید که مدل شما کارآمد است؟
با استفاده از دادههای آزمایشی و محاسبه معیارهای ارزیابی مانند Accuracy، Precision، و Recall. - چگونه مدل را برای محیط واقعی آماده میکنید؟
پس از ارزیابی مدل، آن را در یک داشبورد یا سیستم قابلاستفاده برای کاربران نهایی پیادهسازی کنید.
5. پیادهسازی و استفاده از مدل در محیط واقعی
بسته به نیاز سازمان، میتوانید خروجی پروژه را در قالبهای زیر ارائه دهید:
- گزارشهای مدیریتی: شامل خلاصهای از تحلیلها و نتایج.
- داشبوردهای تعاملی: برای نمایش نتایج بهصورت بصری و پویا.
- سیستمهای پیشبینی: که بهطور خودکار از مدل شما برای تصمیمگیری استفاده میکنند.
نکته پایانی
این پروژه، یک شبیهسازی اولیه از دنیای واقعی است. هرچقدر زمان بیشتری برای درک دادهها، آزمایش مدلها، و اصلاح فرایندها صرف کنید، توانایی شما در حل مسائل واقعی افزایش خواهد یافت.
در پایان این دوره، شما نهتنها با ابزارها و تکنیکهای اساسی دیتا ساینس آشنا خواهید شد، بلکه مهارت تعریف و حل مسائل واقعی را نیز به دست خواهید آورد.