
در فضای دیتاساینس، با فرض اینکه ما مسئله مورد نظر را شناسایی کرده باشیم، می خواهیم ببینیم که با چه گام هایی و در چه فازهایی می توانیم مسئله را حل کنیم و چه استاندارد ها و متدولوژی هایی در این روش وجود دارد.
استانداردهای قابل استفاده:
استقرار و توسعه نتایج (Deployment)
متدولوژی (Methodology)

فاز توسعه و استقرار:
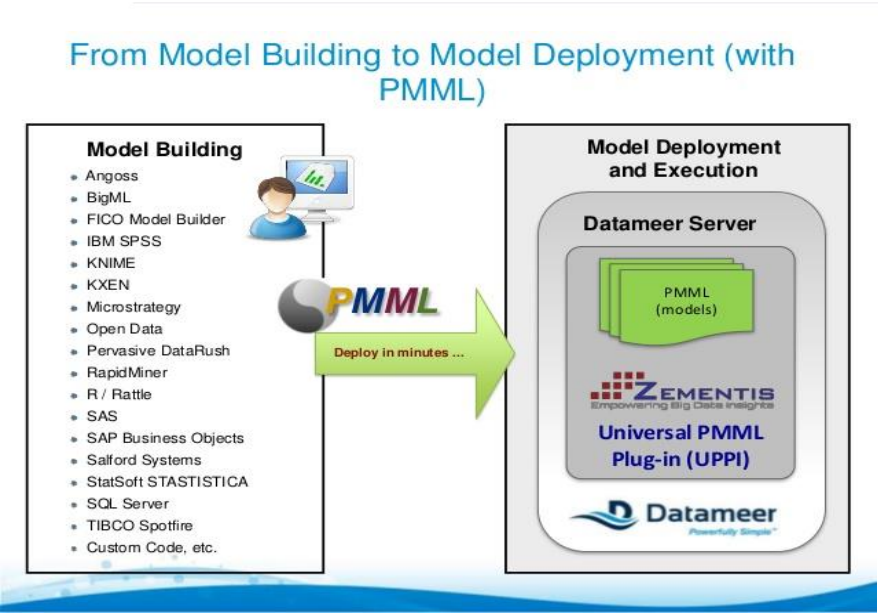
استاندارد هایی مثل PMML و PFA به نوعی یک واسط و یک رابط هستند بین فضای حل مسئله و ابزارهایی که مسئله را در فضای دیتا ساینتیست حل میکند با فضای عملیاتی یک نرم افزار یا … که میخواهیم در محلی مستقر کنیم.
زیرا معمولا ابزار و زبان برنامه نویسی در توسعه نرم افزار ممکن است زبانهای عمومی مانند C یا Java و … باشد در صورتی که شما به عنوان یک تحلیلگر داده یا یک دانشمند داده ممکن است از زبان هایی مانند R یا پایتون و یا حتی ابزارهایی مانندIBM SPSS modeler یا متلب و …. استفاده کرده باشید و مدل سازی کرده باشید.
به همین دلیل برای اینکه ما بتوانیم کدهای نوشته شده یا کد های حاصل از الگوریتمی که در داده های آن مسئله به یک مدل رسیده است را به ابزاری که بر پایه زبان C یا Java و … نوشته شده است انتقال دهیم و از آن استفاده کنیم. PMML و PFA به ما کمک می کنند که این انتقال به راحتی و طی یک استاندارد انجام شود.
این ابزارها توسط گروه DMG توسعه یافتند. (www.dmg.org)
PMML: Predictive Model Markup Language
خروجی این بر اساس استانداردهایی که تعریف کردیم به زبان XML است و به این شکل فرمت تنهایی مدل استخراج شده در قالب یک فایل XML آماده می شود و می توانیم این فایل XML را که رایگان هم هست، به راحتی در هر نرم افزار، طرح توسعه ای و … دیگری استفاده کنیم.
PFA: Portable Format for Analytics
PFA توسعه یافته و ارتقا یافته PMML است چون فایل های xml به دلیل شمای کلی که باید از قبل برای آن تعریف شود مقداری محدودیت ایجاد میکند اما فرمت Json که خروجی PFA است این محدودیت ها را ندارد و توانسته یک فرمت منعطف باشد. از آنجایی که این فرمت توسعه یافته و ارتقا یافته فرمت XML است بنابراین تمامی مدل هایی که طی سال های قبل با فرمت XML آماده شده بود به راحتی تبدیل به PFA شد. اما معکوس این امکان پذیر نیست.

فرض کنید یک شرکتی از لایسنس IMB استفاده کرده و مدل هایی را توسعه داده و به هر دلیلی سال بعد لایسنس را تمدید نکرده باشد. حالا تکلیف آن مدل ها چه می شود ؟ این استاندارد به ما کمک می کند که بتوانیم آن مدل ها را خارج کنیم و در محیط های عملیاتی دیگری مورد استفاده قرار دهیم و آنها را حفظ کنیم.
فرآیند استاندارد فرا صنعتی برای داده کاوی(CRISP-DM):
یکی از جامع ترین و شاید پرکاربردترین استانداردهایی است که در حل مسائل داده کاوی و دیتا ساینس وجود دارد.
محصول کنسرسیومی متشکل از ۳ شرکت است (1993):
- دایملر-کرایسلر
- SPSS
- NCR
این کنسرسیوم با هدف کاهش ریسک اجرای پروژه های داده کاوی انجام شد.
- ارائه متدولوژی جهت پیاده سازی گام به گام بر اساس تجربیات جهانی
- برای چارچوبی برای مستند سازی پروژه های داده کاوی
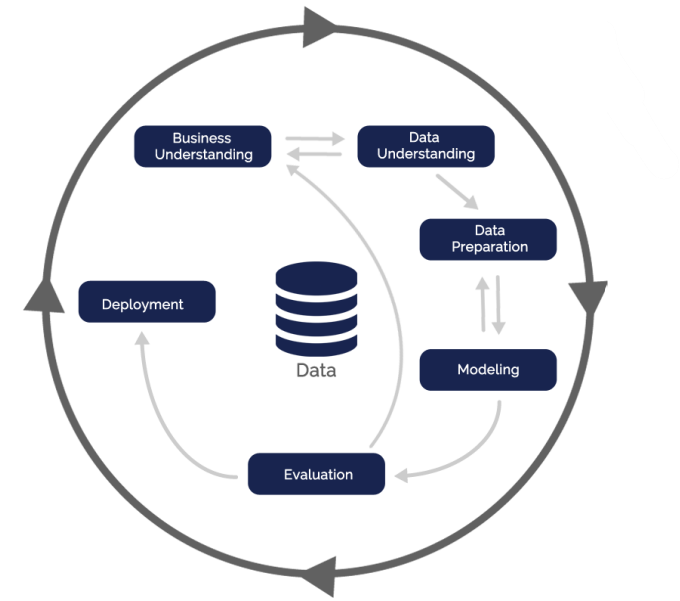
برای متدولوژی CRISP-DM شش فاز تعریف شده است که هر کدام از آنها تسکهایی دارند تا بر اساس این تسکها بتوانیم بفهمیم که در هر فاز در کجا قرار داریم؟ چه تسکهایی را لازم است که انجام دهیم؟ برای هر کدام از این تسکها فعالیت هایی به صورت ریز نوشته شده است که متناسب با آن فعالیت ها یک سری خروجی تعریف شده است. به این شکل ساختار این استاندارد شکل گرفته است.
ترجمه این استاندارد در گروه دایکه انجام شده است که از لینک زیر می توانید فایل pdf آن را دانلود کنید:
فرآیند استاندارد فراصنعتی داده کاوی CRISP
به خصوص در پروژههای اول که در حال کسب تجربه هستید تاکید میشود که این استاندارد را به عنوان یک رفرنس و مرجع در کنار دست خود داشته باشید تا تسک ها، فعالیت ها و … را به طور مداوم از روی این استاندارد چک کنید تا مسیر حل مسئله در ذهن شما نهادینه شود و بتوانیم یک پروژه را در حوزه دیتا ساینس به درستی تعریف کنیم، پیش ببریم، از نظر زمانبندی و کارهای اجرایی مدیریت بکنیم و ریسک پروژه را به حداقل برسانیم.
استاندارد CRISP-DM یک فرایند استاندارد فرا صنعتی برای دادهکاوی محسوب می شود. علت آنکه این استاندارد فرا صنعتی است این است که آن کنسرسیوم تاکید داشت که یک متدولوژی و یک روش شناسی برای پروژه ها معرفی شود که فارغ از اینکه در چه لایه ای از بیزینس می خواهیم مسئله را حل کنیم، بتوانیم از آن ابزار ها در قالب یک نقشه راه استفاده کنیم.
این استاندارد در چهار فصل طراحی شده است؛
فصل اول کلیات استاندارد و روش ها و متدولوژی ها را که بر مبنای آن شکل گرفته است توضیح داده است.
فصل دوم که مدل مرجع است و جلوتر توضیح داده خواهد شد.
فصل سوم راهنمای کاربری است و مانند یک چک لیست در اختیار ما قرار میگیرد تا بتوانیم بدانیم که در هر فاز بنابر این که در چه تسکی قرار داریم و کدام تسک را قصد داریم انجام دهیم، چه فعالیت هایی را باید انجام دهیم و متناسب با آن چه خروجی هایی را باید گردآوری کنیم و به سمت آن برویم.که این قطعاً یکی از مهمترین بخش ها است؛ به خصوص در پروژه های ابتدایی و پروژه های اولیه که انجام میدهیم.
فصل چهارم بیشتر روی مستندسازی نتایج متمرکز است و خروجی های هر دست را جدا کرده است. به دلیل عمومی بودن این استاندارد، الزامی ندارد که تمامی تسک ها و فعالیت های موجود در این استاندارد را برای تمامی پروژه ها عملی کنیم بلکه صرفاً موارد مورد نیاز پروژه خودمان را استفاده می کنیم.

همانطور که در چرخه CRISP-DM میبینید این ۶ فاز تعامل هایی نیز با یکدیگر دارند. به عنوان مثال در فاز اول شناسایی و درک کسب و کار (Businesses Understanding) که هدف اصلی آن تعریف دقیق مسئله و چارچوب های آن است.
زمانی که مسئله را به درستی توانستند تعریف کنیم می توانیم وارد مرحله بعدی یعنی شناسایی و درک داده ها (Data Understanding) میشویم. یعنی جایی که مبنای کار ما به عنوان یک دیتا ساینتیست یا دیتاآنالیست یا هر نقشه دیگری که باشیم خوراک اولیه ما اینجا باید تامین شود و از نظر ارتباط آنها و کیفیت آن ها و موارد دیگر مورد بررسی قرار میگیرند.
ارتباط دوطرفه ای بین این مرحله به مرحله قبل وجود دارد که یعنی با اطلاعات جدیدتری که از داده ها به دست آورده ایم، مرحله قبل ممکن است چکش کاری شود و تغییراتی در آن ایجاد شود.
زمانی که فاز دوم به درستی انجام شد وارد فاز سوم می شویم آماده سازی دیتا ها (Data Preparation) نامیده می شود. این مرحله یکی از بخشهای زمانبر و بسیار مهم است. حالا دیتا هایی را که از مرحله ۳ خارج میشوند و آماده استفاده از الگوریتم ها هستند وارد فاز چهارم (Modeling) می کنیم و آنجا مسئله ها حل می شوند.
بهترین روش ها و بهترین مدل های استخراج شده را انجام میدهیم و در فاز پنجم (Evaluation) همه آنها ارزیابی می شوند. این ارزیابی بر اساس اهدافی است که در فاز اول مشخص کرده بودیم. اگر تایید شدند وارد فاز نهایی می شوند که مرحله استقرار و توسعه مدل ها (Deployment) است.
فاز اول: شناسایی و در کسب و کار
مهمترین هدف و یکی از تسک های اصلی این فاز، تعریف دقیق مسئله است؛ اهداف و ابعاد پروژه، معیارهای موفقیت به همراه شرح کامل از وضعیت موجود و راهکارهای فعلی
یعنی باید به یک تعریف مشترک با کارفرما و ذینفعان آن پروژه برسیم. ما باید بتوانیم آن مسئله را با ادبیاتی که آن بیزینس دارد بیان کنیم تا باعث اطمینان خاطر کارفرما نیز بشود و همینطور برای آنها قابل استفاده باشد. برای اینکه به هدف این مرحله برسیم لازم است که فعالیتهایی انجام شود مثلاً جلساتی را داشته با کارفرما داشته باشیم یا گاهی ممکن است آموزشهایی را در آن زمینه ببینیم.

- ارزیابی وضعیت
- شناسایی ذینفعان، افراد موثر در پیشبرد پروژه، منابع داده، محدودیت ها و ریسک ها
- اهداف داده کاوی: ترجمه دقیق و طراحی سناریو داده کاوی بر اساس نوع یادگیری و انتخاب وظایف و الگوریتم های احتمالی.
- ارائه طرح پروژه: مستندسازی نتایج و نقشه راه حل مسئله
توضیحات این ۲مرحله:
تمام شناختی که در دو تسک قبلی به دست آوردیم به همراه نوع و روشهای داده کاوی در کنار یکدیگر قرار میگیرند و نگاه می کنیم ببینیم چطور میشود آن مسائل را به ادبیات داده کاوی ترجمه کرد؟ در این صورت ما میتوانیم یک نقشه راه را در چارچوب داده کاوی یا دیتاساینس داشته باشیم.

زمانی که این نقشه راه ثبت شود تبدیل به پروژه می شود. یعنی یک مستند است که بعد از تایید کارفرما عملاً ثابت میکند که ما مسئله را به شکلی فهمیدیم؟ قرار است با چه روش هایی آن را حل کنیم؟ با چه روش هایی می توانیم آن را ارزیابی کنیم؟ و بر اساس آن ارزیابی اگر اطلاعات تایید شد و به آن اهداف رسیدیم، پروژه را مختومه کنیم و پروژه را به عنوان یک پروژه موفق اعلام کنیم.
اهمیت این مسئله بسیار مشخص است ما در اینجا به درستی عمل نکنیم و وارد جزئیات نشویم ممکن است منِ نوعی به عنوان دیتا ساینتیست برداشت اشتباهی از مسئله داشته باشم و اگر بهترین روش ها را هم برای حل مسئله به کار ببرم و درست ترین جواب ها را هم داشته باشم اما در نهایت یک جواب درست برای یک سوال نادرست خواهم داشت. و این یعنی شکست پروژه چون سوال و دغدغه ذینفعان پروژه چیز دیگری بوده است که ما به درستی متوجه آن نشده بودیم.
در صورتی که در این مرحله به درستی عمل نکنیم و وارد جزئیات نشویم، اگر بهترین روش ها را هم برای حل مسئله به کار ببریم و درست ترین جواب ها را هم داشته باشیم، در نهایت یک جواب درست برای یک سوال نادرست خواهیم داشت!
فاز دوم: شناسایی و درک داده ها
گردآوری داده ها: در اغلب موارد داده های مورد نیاز در حل مسئله در جاهای مختلف و با فرمت های متنوع پراکنده هستند.
این مرحله یکی از مراحل زمان بر در پروژه ها است که با چالش های متنوعی روبرو است. گاهی برخی از داده ها به صورت دست نویس هستند که نیاز است به نرم افزار ها وارد شوند. یا گاهی برای دسترسی به داده ها به مجوزهای خاصی نیاز داریم که گرفتن آن مجوز ها بسیار طولانی مدت خواهد شد.
توصیف داده ها: استفاده از روش های آماری توصیفی و مستندسازی نحوه دسترسی به داده ها و چارچوب آنها تاثیر زیادی در شناخت اولیه و دید شهودی نسبت به داده ها می گردد.

کیفیت داده ها: بررسی کیفیت داده های موجود، باعث می گردد تا با تعیین استراتژی های مناسب به پاکسازی داده بپردازیم و بهبود کیفیت داده ها اقدام به یادگیری مدل کنیم.
بخشی از کیفیت داده ها به ناسازگاری و عدم انطباقا داده ها برمی گردد به عنوان مثال فرض کنید در یک شرکت خودروسازی برای رنگ سفید خودرو قبلا از یک کد رنگ دیگر استفاده می کردند و حالا از یک کد دیگر برای رنگ سفید استفاده می کنند. یعنی زمانی که رنگ خودرو را در بازی زمانی چند ساله بررسی می کنیم متوجه میشویم که برای رنگ سفید ۲ کد متفاوت وجود دارد اینها باید حتماً شناسایی و برطرف شوند و داده های استاندارد را داشته باشند.
یا گاهی اوقات داده های پرت را داریم حواسمان باشد که داده های پرت به معنای داده های اشتباه نیستند بلکه از توزیع بدنه داده های ما تبعیت نمی کنند. عنوان مثال میزان حقوق دریافتی هیئت مدیره یک سازمان که احتمالا چند برابر پرسنل آن سازمان است. زمانی که ما توزیع داده های مربوط به حقوق دریافتی را رسم کنیم میزان حقوق اعضای هیئت مدیره بسیار دورتر از پرسنل این سازمان خواهد بود و اصطلاحاً داده های پرت هستند و نه اشتباه!
کاوش در داده ها: بررسی آماری دقیق از همبستگی های موجود بر روابط معنادار بین آنها قدم اول در انتخاب ایجاد و تغییر مجموعه داده ها است.
درست است که در این استاندارد فاز دوم و سوم از یکدیگر تفکیک شده اند اما در اجرا این دو در هم تنیده اند و امکان جداسازی آنها وجود ندارد. به عنوان مثال زمانی که ما دو منبع داده را پیدا کردیم ممکن است آن دو را با یکدیگر ادغام کنیم و این اقدام در واقع به معنای آماده سازی داده ها است که در گام سوم است.

اگر در دیتا ها عددی را دیدیم که اشتباهاً درصد منفی خورده یا عددی که متوجه شدیم به هر دلیلی اشتباه واضحی است آن داده را پاک میکنیم و این در واقع پاکسازی داده هاست که در فاز سوم قرار دارد.
بنابراین فاز دوم و سوم از هم قابل تفکیک نیستند و صرفاً برای مستند سازی به صورت جداگانه نوشته میشوند.
فاز سوم: آماده سازی داده ها
ما هرگز نباید داده های خام یا داده هایی با حداقل تغییر را وارد فاز مدلسازی بکنیم. در واقع دلیل آنکه این فرایندها هنوز نتوانسته است به طور صددرصد مکانیزه و با سیستم انجام شود همین مرحله آماده سازی داده ها است.
زیرا به دیتاآنالیزرها و دیتاساینتیست ها و غیره وابسته است که باید به عنوان یک هوش انسانی و یک تحلیلگر و با شناختی که از بیزینس به دست آورده ایم و دغدغه ها و چالش ها و اهمیت های آن را میدانیم و با شناختی که از داده ها پیدا کردیم یعنی کیفیت داده ها، روابط داده ها و … را می دانیم، می آییم ایده پردازی میکنیم، شاخص سازی می کنیم و کیفیت داده ها را افزایش می دهیم و سپس آنها را وارد فاز مدلسازی میکنیم.
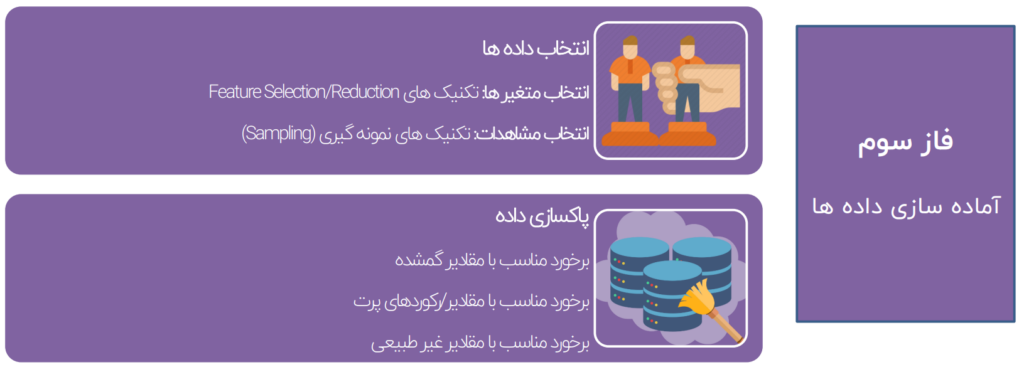
انتخاب داده ها:
- انتخاب متغیرها: تکنیکهای Feature Selection/Reduction
- انتخاب مشاهدات: تکنیک های نمونه گیری Sampling
پاکسازی داده ها
- برخورد مناسب با مقادیر گمشده
- برخورد مناسب با مقادیر/رکوردهای پرت
- برخورد مناسب با مقادیر غیر طبیعی
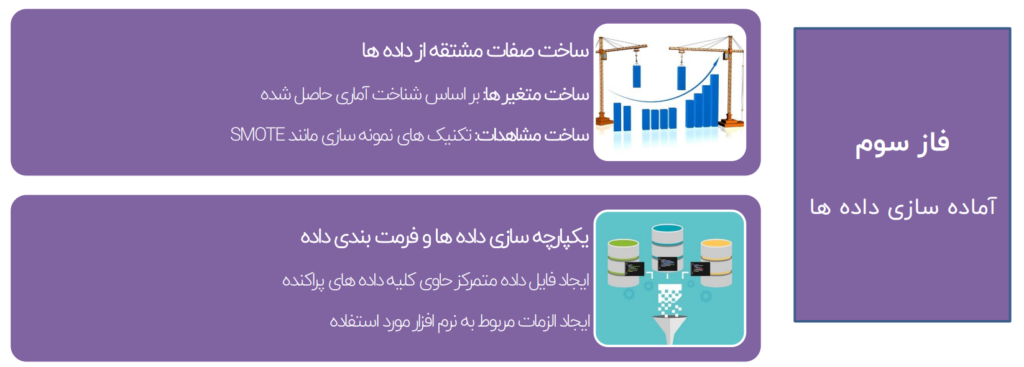
ساخت صفات مشتق از داده ها
ساخت متغیرها: بر اساس شناخت آماری حاصل شده
ساخت مشاهدات: تکنیک های نمونه سازی مانند SMOTE به عنوان مثال زمانی که با ضایعه یا یک تومور مواجه هستیم که حجم داده ها بسیار پایین است ما می توانیم با در نظر گرفتن میانگین بین نقاط مختلف تومور و یک داده شبیه سازی شده در حد واسط بین ۲ رکورد واقعی، داده های مربوط به تورم آن بخش از تومور را افزایش دهیم تا شانس دیده شدن و دنبال کردن بیشتری به مدل ها و الگوریتم های خودمان بدهیم.
یکپارچه سازی داده ها و فرمت بندی داده
ایجاد فایل داده متمرکز حاوی کلیه داده های پراکنده
ایجاد الزامات مربوط به نرم افزار مورد استفاده
تجربه نشان داده است که حدود ۷۰ درصد زمان کل یک پروژه صرف پیشرفت پروژه تا پایان فاز سوم می شود. یعنی این مراحل بسیار زمان بر هستند و البته بسیار مهم هستند. نگاه ما در حوزه دیتاساینس مانند همان چرخه فرآیند استاندارد فراصنعتی برای داده کاوی است یعنی همیشه بایستی ساده ترین تصمیمات و کمهزینهترین تصمیمات گرفته شود و به سرعت ۰ تا ۱۰۰ مسئله انجام شود.
یعنی ما به شکل نه خیلی عمیق، اما با سرعت بالا مسئله را تا آخر پیش ببریم و به نقطهای برسیم که قابلیت اجرای مدل را داشته باشد و بعد از آن که مدل را ساختیم و خروجی گرفتیم، به مرحله اول باز می گردیم و تصمیمات پیچیدهتری را می گیریم و با شناختی که با استفاده از کلیات مسیر به دست آوردهایم مسئله بهتری را انتخاب می کنیم و مجدداً پیش می رویم.
این شیوه ۲ مزیت مهم دارد: ابتدا اینکه همیشه گزارش هایی برای ارائه دادن داریم؛ هر چند که تحت یک سری فرضیات و محدودیت هایی گفته می شوند. دوم آن که برای خود ما به عنوان یک دیتا ساینتیست و کسی که در حال حل مسئله است به ما کمک می شود که بدانیم آیا گامهایی که در حل مسئله انجام می دهیم درست است یا خیر؟ و آیا وضعیت الگوریتم های ما را بهبود می بخشد یا خیر؟ و شاید بهتر باشد استراتژی خود را تغییر دهیم؟
فاز چهارم: مدلسازی
انتخاب الگوریتم و طرح آزمون
مبنی بر گام هایی که قبلا بیان شد الگوریتم های مناسب انتخاب و متناسب با حجم و توزیع داده ها طرح آزمون برای ارزیابی مدل ها تعیین میگردد.
آموزش الگوریتم و ساخت مدل
تنظیم پارامترها و توصیف مدل های ایجاد شده
ارزیابی مدل ها
بررسی نتایج مدل ها و انتخاب بهترین مدل
اگر مسیر را تا به اینجا به درستی پیش رفته باشیم در فاز چهارم کار پیچیده ای نداریم. زیرا انتخاب الگوریتم و طرح آزمون که یکی از مراحل اصلی این فاز است عملا در نقشه راهی که قبلا تعیین کرده ایم شکل گرفته است. زمانی که ما آن مسئله بیزینسی را تبدیل به مسئله داده کاوی کردیم عملا تا حد زیادی نقشه راه را چیده ایم.
در طرح پروژه مشخص شده است که ما قرار است چه کارهایی انجام دهیم و در زیر مجموعه آنها، چه الگوریتم هایی را قرار است انجام دهید؟ با توجه به آن الگوریتم چه روشهای ارزیابی و چه مترهای ارزیابی در آمار، ماشین لرنینگ و غیره وجود دارد که بتوان آن را به درستی ارزیابی کنیم بنابراین اینجا کار پیچیدهای نداریم و با مراجعه به طرح پروژه که در ابتدا نوشته شده است می توانیم این مرحله را به خوبی طی کنیم.
اینجا کار با نرم افزار و دیتا به پایان می رسد و وارد فازهای مدیریتی پروژه میشویم.

فاز پنجم: ارزیابی
ارزیابی کلیات راه حل
- ارزیابی نتایج به دست آمده با طرح اولیه پروژه و معیارهای موفقیت
- مروری بر فرایند طی شده و مستند سازی

فاز ششم: توسعه و استقرار
- طرح توسعه و مانیتورینگ فرایند انجام شده
- مستند سازی روال انجام شده و نتایج به دست آمده
- بهره برداری از نتایج در قالب پرزنتیشن، داشبورد، سرویس یا نرم افزار