
الگوریتم درخت تصمیم یکی از پرکاربردترین الگوریتم های مبتنی بر قانون است که با ایجاد مرزهای تصمیم گیری به صورت شفاف، قابلیت حل مسائل رده بندی و رگرسیون را به همراه تفسیرپذیری زیاد فراهم می کند.
استخراج قوانین در قالب اگر -آنگاه از دلایل مهمی که باعث شده الگوریتم های درخت تصمیم در حل مسائلی که به دنبال توصیف مفهوم و چرایی یک پدیده هستند موفق و پرکاربرد شود، نمایش الگوهای بدست آمده در قالب اگر–آنگاه می باشد.
درخت تصمیم ابزاری برای اتخاذ تصمیم مناسبتر است بطوری که شکل و ساختاری درختی (Tree Structure) یا سلسله مراتبی (Hierarchical) به تصمیمات و نتایج آنها میبخشد. ساختار این درخت میتواند برمبنای شانس و احتمال نیز باشد، بطوری که انتخاب هر تصمیم به طور تصادفی میتواند ریسک یا مزایایی به همراه داشته باشد.
گاهی اوقات برای نمایش گزارههای شرطی و نتایج حاصل از ترکیب آنها از درخت تصمیم نیز استفاده میشود. امروزه از درخت تصمیم برای نمایش عملیات سلسله مراتبی (Hierarchical Operators) و به خصوص تحلیل تصمیمات صورت گرفته برای رسیدن به هدف (Hierarchical Decision Making) استفاده میشود.
به این ترتیب میتوان درخت تصمیم را یکی از ابزارهای مناسب در حوزه یادگیری ماشین و حتی مدیریت سطح بالا، در نظر گرفت.
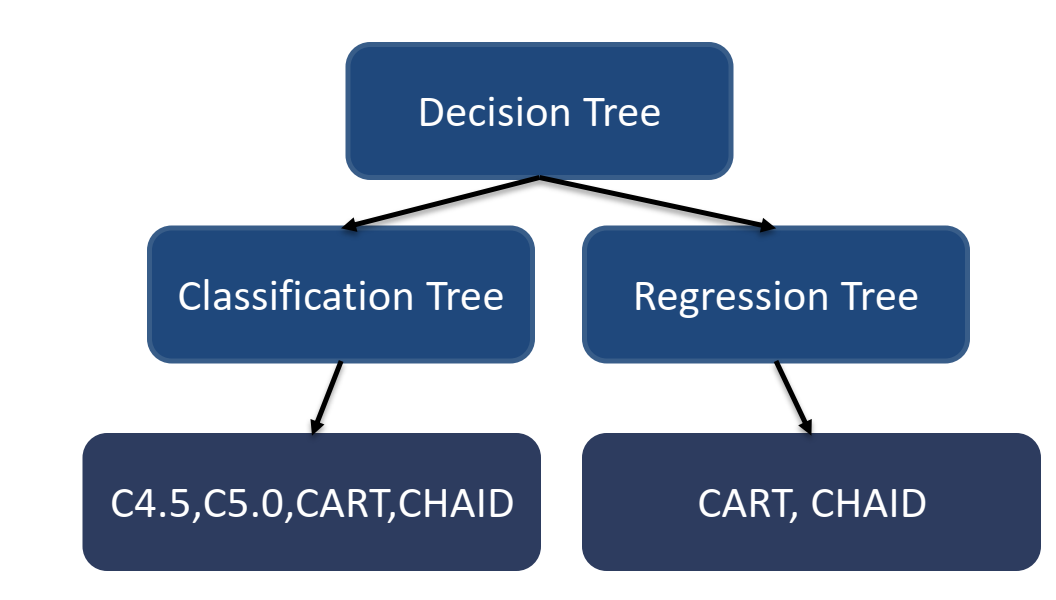
مفاهیم اولیه درخت تصمیم
همانطور که اشاره شد، درخت تصمیم دارای گرههای متفاوتی است که در ادامه با انواع آنها به عنوان ابزارهای اولیه رشد درخت تصمیم آشنا میشویم. در حقیقت یک درخت تصمیم از گرههای مختلفی تشکیل شده است. اتصال گرههای مختلف و البته با وظایف متفاوت، یک درخت تصمیم را تشکیل میدهد.
● گره (Node): گره ساختاری است که میتواند دارای یک ارزش یا مقدار خاص یا بیان یک شرط باشد.
● ریشه (Root): اولین و بالاترین گره در یک درخت تصمیم، ریشه نامیده میشود. بخشهای دیگر درخت تصمیم از ریشه آغاز و نشأت میگیرند.
● والد (Parent): گرهای که دارای فرزند باشد. به این معنی که گرهای در سطح پایینتر به آن متصل است.
● فرزند (Child): گرهای است که به طور مستقیم به گره دیگری متصل است و در سطح پایینتری از گره والد قرار گرفته است.
● شاخه (Branch): شاخه، گرهای است که حداقل دارای یک فرزند (Child) است.
ساختار فلوچارتی درخت تصمیم دارای سه جزء اصلی زیر می باشد:
- گره ریشه (Root Node)
- گره تصمیم (Decision Node)
- گره پایانی – برگ (Terminal Node – Leaf)
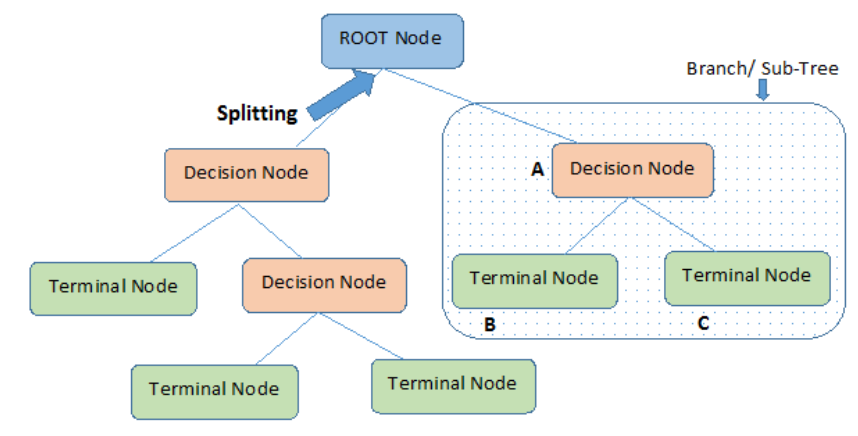
تمام داده ها در گره ریشه قرار دارند و هر رکورد بر اساس پاسخ به سوالات گره تصمیم به مسیر خود ادامه می دهد تا وارد گره پایانی شود. مسیر طی شده از ریشه تابرگ نشان دهنده یک الگو در قالب قانون اگر–آنگاه می باشد.
به هر قسمت از درخت اصطلاحا sub-Tree یا Branch می گوییم.
جهت توسعه درخت تصمیم باید به سوالات زیر پاسخ داد:
- کدام ویژگی برای انشعاب انتخاب شود؟
- حدود آستانه ای برای انشعاب هر ویژگی چه مقادیری باشد؟
- تعداد انشعاب ها تا کجا ادامه پیدا کند؟
هر الگوریتمی با پاسخ به سوالات بالا می تواند یک درخت تصمیم روی داده های مسئله، آموزش دهد. الگوهای بدست آمده در قالب قوانین درخت نمایش داده میشود. بطور مثال برای داده های قبلی در خصوص بررسی احتمال برگزار شدن بازی گلف داریم:
𝒊𝒇𝑜𝑢𝑡𝑙𝑜𝑜𝑘 = 𝑠𝑢𝑛𝑛𝑦&ℎ𝑢𝑚𝑖𝑑𝑖𝑡𝑦 ≤ 75 𝒕𝒉𝒆𝒏 𝑇𝑎𝑟𝑔𝑒𝑡 = 𝑌𝑒𝑠
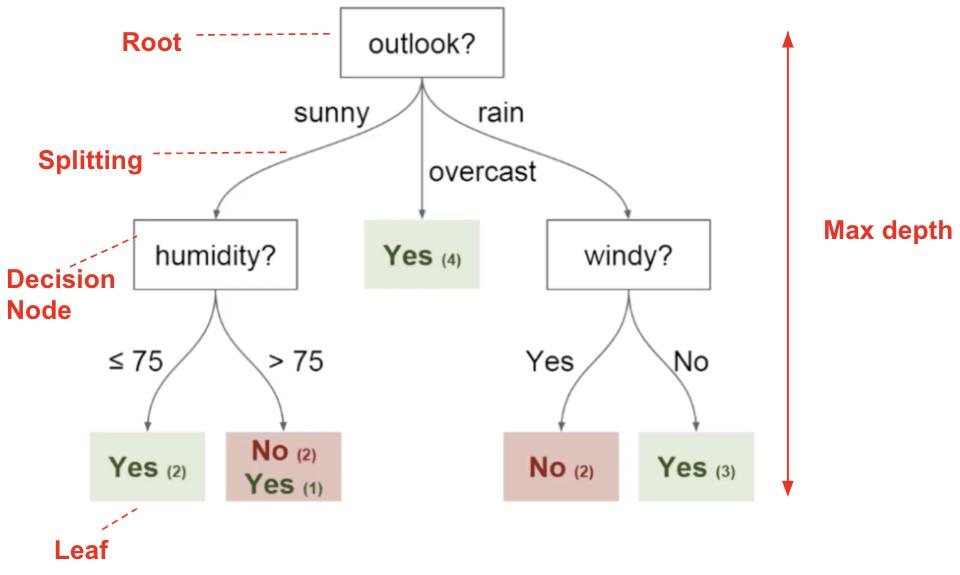
اصطلاح دیگری با عنوان عمق درخت داریم که یعنی درخت تا چند لایه رشد کرده. در این مثال می بینیم که تا 2 لایه رشد کرده است.
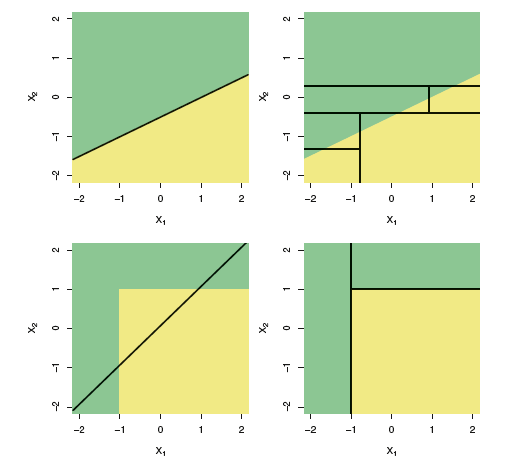
درخت تصمیم با افراز فضای داده ها به زیرفضاهای کوچکتر که در آنها میزان خلوص مقدار فیلد هدف حداکثر شود به شناسایی الگوها می پردازد. بنابراین درخت تصمیم می تواند به صورت یک مدل غیرخطی روابط پیچیده در داده ها را شناسایی کند.
مثال: فرض کنید در تصاویر روبرو نواحی زرد و سبز مربوط به دو کلاس متفاوت هستند که در دو تصویر بالا، تفکیک خطی نسبت به تفکیک غیرخطی درخت تصمیم عملکرد بهتری دارد ولی در تصاویر پایین تفکیک غیرخطی درخت تصمیم جداسازی بهتری را انجام داده است.
مزایا و نقاط قوت درخت تصمیم:
- ماهیت جعبه سفید بودن این روش و استخراج قوانین منجر به درک ساده و سریع از الگوهای به دست آمده میشود.
- نسبت به بسیاری از الگوریتم های دیگر نیاز به مراحل آماده سازی داده کمتری دارد. به طور مثال روش های نرمال سازی و یا تبدیل داده ای کیفی به عددی در توسعه درختهای تصمیم چندان مسئله ساز نیست.
- ماهیت انتخاب ویژگی به صورت درونی در ماهیت این الگوریتم وجود دارد و به همین دلیل نسبت به مشکلات کیفی مانند داده های نامرتبط و افزونگی داده ها مقاوم می باشد.
- ماهیت ناپارامتری این الگوریتم باعث می شود نیاز به فرضیات محدود کننده ای مانند برقراری فرض توزیع نرمال، استقلال ویژگی ها، تثبیت واریانس و … نداشته باشیم.
- به علت ساختار فلوچارتی، جهت مدلسازی رفتار یا تصمیمات انسانی گزینه مطلوبی میباشد و قابلیت استفاده از آزمون های آماری برای پایداری نتایج را دارد.
معایب و محدودیت های درخت تصمیم
- در مقابل تغییرات در داده های آموزشی الگوریتم مقاومی محسوب نمیشود و با تغییرات کم در داده های ورودی امکان تغییر در خروجی ها وجود دارد.
- به علت ماهیت جستجوی حریصانه (Greedy Search) در انشعاب های انجام شده، تضمینی برای بهینه بودن سراسری الگوها نیست.
- به طور کلی ایجاد سادگی و شفافیت بالا در این الگوریتم، منجر به کاهش صحت مدل (Accuracy) نسبت به برخی الگوریتم های دیگر می شود.