- وجود رابطه خطی بین ویژگی های ورودی و فیلد هدف
- توزیع نرمال خطاهای مدل رگرسیونی با میانگین صفر و واریانس ثابت
- عدم همبستگی بین خطاهای مدل رگرسیونی
- عدم هم خطی بین ویژگی های ورودی به مدل

وجود رابطه خطی بین ویژگی های ورودی و فیلد هدف
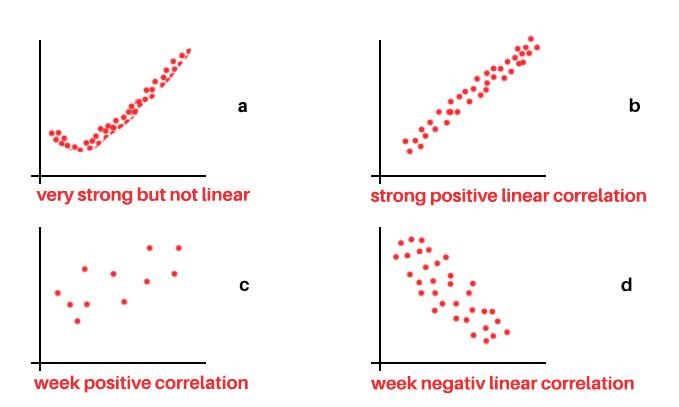
یکی از فرضیات اساسی مدل رگرسیون خطی، وجود ارتباط خطی بین ویژگی های ورودی با فیلد هدف می باشد.
بررسی این موضوع عمدتا از طریق رسم نمودار پراکنش بین ویژگی های ورودی و فیلد هدف و همچنین محاسبه شاخص هایی مانند آماره همبستگی پیرسن، اسپیرمن و … انجام می شود.
در صورتی که رابطه خطی بین ویژگی و فیلد هدف مشاهده نشد، می توان با استفاده از توابع تبدیل لگاریتمی و … روی ویژگی های ورودی، فرض رابطه خطی برای مدل رگرسیون را ایجاد نمود.
توزیع نرمال خطاهای مدل رگرسیونی با میانگین صفر و واریانس ثابت
فرض دیگری که بعد از ساخت مدل رگرسیونی و محاسبه خطاهای مدل مورد بررسی قرار می گیرد، بررسی نرمال بودن توزیع آماری خطاهای مدل می باشد.
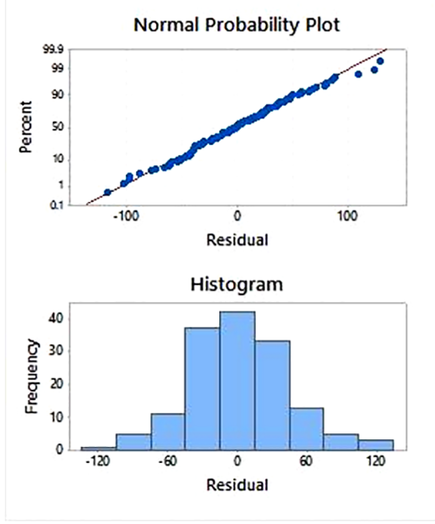
بررسی نرمال بودن توزیع از طریق رسم نمودار هیستوگرام یا نمودار چندک – چندک خطاهای مدل یا آزمون نیکویی برازش توزیع نرمال انجام می شود. همچنین می توان بررسی های فوق را روی داده های فیلد هدف نیز انجام داد، زیر دارای ارتباط خطی با خطاها می باشد.
در صورت عدم فرض نرمال بودن، با انجام برخی تبدیل ها از جمله تبدیل باکس – کاکس و … روی فیلد هدف، می توان شرایط مناسب برای ساخت مدل رگرسیونی را ایجاد نمود.
میانگین توزیع خطاهای مدل بایستی مقدار صفر باشد. در صورتی که مقدار میانگین خطاها بیشتر یا کمتر از صفر باشد، به این معنی می باشد که پیش بینی مدل ها دارای بیش/کم برآوردی (Over/Under Estimate) می باشد.
جهت بررسی میانگین خطا های مدل، کافیست نمودار پراکنش مقادیر خطا (باقیمانده ها) را در مقابل مقادیر پیش بینی شده مدل رسم کنیم. انتظار می رود داده ها در اطراف خط میانگین صفر پراکنده شده باشند.
در صورتی که مقادیر به سمت بالا یا پایین خط میانگین صفر، اریبی داشته باشد، می تواند به معنی کم/زیاد برآورد شدن مقدار عرض از مبدا مدل بوده و با اضافه کردن میزان اریبی به مدل، دقت پیش بینی را اصلاح نمود.
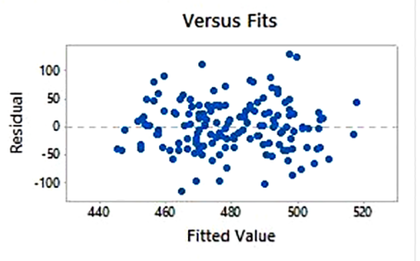
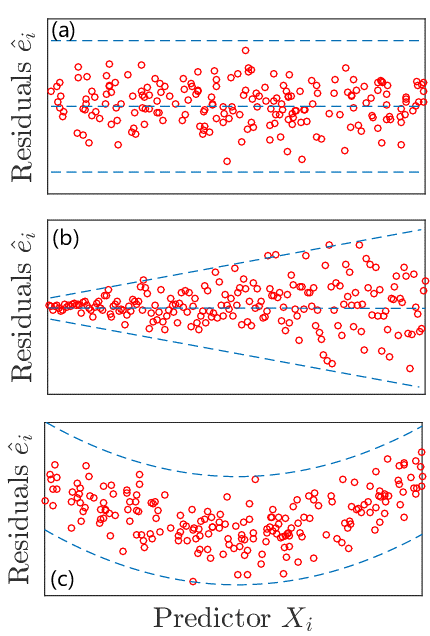
نکته بسیار مهم دیگر در بررسی توزیع آماری خطاهای مدل، وجود فرض ثابت بودن واریانس خطاها می باشد.
جهت بررسی واریانس خطا های مدل، کافیست نمودار پراکنش مقادیر خطا (باقیمانده ها) را در مقابل مقادیر پیش بینی شده مدل و همچنین ویژگی های ورودی رسم کنیم. انتظار می رود داده ها در اطراف خط میانگین صفر به صورت کاملا تصادفی و بدون هیچ الگویی پراکنده شده باشند.
در صورتی که با افزایش مقادیر پیش بینی، میزان خطای مدل روند کاهشی، افزایشی یا خطی داشته باشد، به معنی عدم ثبات واریانس بوده و نیاز به تبدیل های لگاریتمی، چند جمله ای و … روی مقادیر فیلد هدف یا ویژگی های ورودی خواهیم داشت.
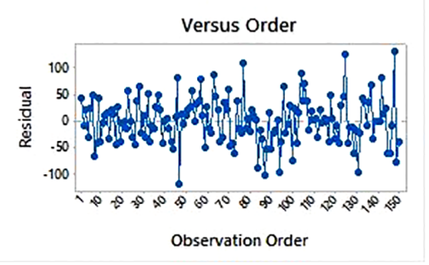
ناهمبستگی بین خطاهای مدل رگرسیونی
فرض دیگری که بایستی مورد توجه قرار گیرد، عدم همبستگی بین مقادیر متوالی (خودهمبستگی) و الگوهای معنادار در میزان خطای مدل است، زیرا برآورد واریانس و انحراف معیار ضرایب مدل به درستی انجام نمی شود.
جهت بررسی خودهمبستگی و روند در خطاهای پیش بینی، کافیست مقادیر خطاها را در مقابل ترتیب رکوردها رسم کنیم و با اتصال نقاط به بررسی آن بپردازیم.
یکی از آماره های پرکاربرد در بررسی خودهمبستگی، آماره دوربین – واتسون می باشد. در صورتی که توزیع خطاها (باقیمانده ها) نرمال باشد، می توان از این آماره استفاده کرد. مقدار این آماره در بازه 0 تا 4 می باشد و مقدار 2 به معنی عدم وجود خودهمبستگی است. معمولا قرارگیری این آماره در بازه 1.5 تا 2.5 قابل قبول می باشد.
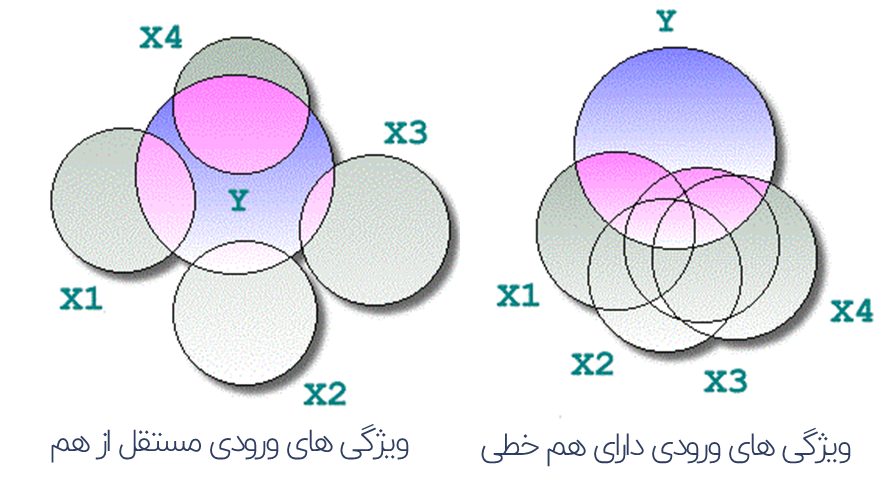
عدم هم خطی/ هم خطی چندگانه بین ویژگی های ورودی به مدل (Collinearity/Multicollinearity)
یکی از مفروضات مهم در برآورد حداقل مربعات (OLS) فرض مستقل بودن ورودی های مدل می باشد. نقض این فرض منجر به اریبی در برآورد ضرایب مدل می گردد.
جهت بررسی این فرض، استفاده از نمودار پراکنش و ماتریس واریانس-کوواریانس بین ویژگی های ورودی کمک کننده می باشد. همچنین پس از ایجاد مدل رگرسیونی شاخص فاکتور تورم واریانس (Variance Inflation Factor – VIF) برای هر ویژگی محاسبه شده و مقادیر بیشتر از 10 نشان از مشکل هم خطی آن ویژگی با سایر ویژگی ها می باشد.
روش برخورد مناسب، حذف ویژگی، استفاده از روش PCA و یا روش تنظیم سازی (Regularization) در برآورد ضرایب مدل رگرسیونی می باشد.