
در عصر کنونی بیوتکنولوژی و پزشکی، تحلیل دادههای ژنومی به عنوان قطبنمایی است که محققان را در میان کد ژنتیکی ما هدایت میکند. این راهنمای جامع به هدف توضیح تحلیل دادههای ژنومی همراه با کدنویسی پایتون و R ارائه شده و هر مرحله را به قسمتهای سادهتری تقسیم میکند تا درک آن آسانتر باشد.
پیش از ورود به جزئیات تحلیل دادههای ژنومی، بیایید مفهوم دادههای ژنومی، فرمتهای آن و اهمیت تحلیل دادههای ژنومی را درک کنیم.
دادههای ژنومی چیست؟
دادههای ژنومی کدی است که در توالیهای DNA موجودات زنده جاسازی شده و به عنوان طرح اولیه حیات عمل میکند. این دادهها شامل مجموعه کاملی از دستورالعملهای ژنتیکی است که رشد، عملکرد و ویژگیهای یک ارگانیسم را هدایت میکند. این داده شامل ترتیب بازهای نوکلئوتیدی – آدنین (A)، تیمین (T)، سیتوزین (C) و گوانین (G) – است که به صورت خاصی مرتب شده و ژنهایی را شکل میدهند که به عنوان بلوکهای سازنده حیات بیولوژیکی ما عمل میکنند.
دادههای ژنومی زبان مولکولی است که دانشمندان برای درک ویژگیهای وراثتی، منشاء بیماریها و مسیرهای تکاملی گونههای مختلف آن را رمزگشایی میکنند.
فرمتهای رایج دادههای ژنومی چیست؟
فرمتهای رایج دادههای ژنومی شامل FASTQ است که دادههای خام توالی را نگه میدارد، BAM که نسخه باینری فرمت Sequence Alignment/Map (SAM) است و برای ذخیرهسازی توالیهای همتراز شده استفاده میشود و Variant Call Format (VCF) که به طور خاص برای نمایش تغییرات ژنتیکی تشخیص داده شده طی تحلیل دادههای ژنومی طراحی شده است.

تحلیل دادههای ژنومی چیست و چرا مهم است؟
تحلیل دادههای ژنومی، بررسی سیستماتیک حجم زیادی از اطلاعات ژنتیکی موجود در DNA یک ارگانیسم است. این فرآیند شامل استفاده از تکنیکهای محاسباتی و ابزارهای تخصصی برای بررسی کد ژنومی است.
هدف اصلی تحلیل دادههای ژنومی استخراج بینشهای معنادار از دادههای ژنتیکی، درک عملکرد ژنها، شناسایی تغییرات و بررسی روابط بین عناصر مختلف درون ژنوم است. این فرآیند به عنوان پل ارتباطی بین اطلاعات خام ژنتیکی و دانش کاربردی عمل میکند و به دانشمندان، محققان و متخصصان حوزه سلامت کمک میکند تا پایه ژنتیکی پدیدههای مختلف، مانند ویژگیهای وراثتی، بیماریها و الگوهای تکاملی را درک کنند.
به طور کلی، تحلیل دادههای ژنومی درکی عمیقتر از پیچیدگیهای مولکولی زندگی ارائه داده و راه را برای پیشرفتها در پزشکی، زیستشناسی و ژنتیک هموار میکند.
مراحل تحلیل دادههای ژنومی چیست؟
تحلیل دادههای ژنومی شامل چندین مرحله است که در اینجا با جزئیات و مثالهای کدنویسی با پایتون و R توضیح داده شده است.
مرحله ۱: جمعآوری دادههای ژنومی
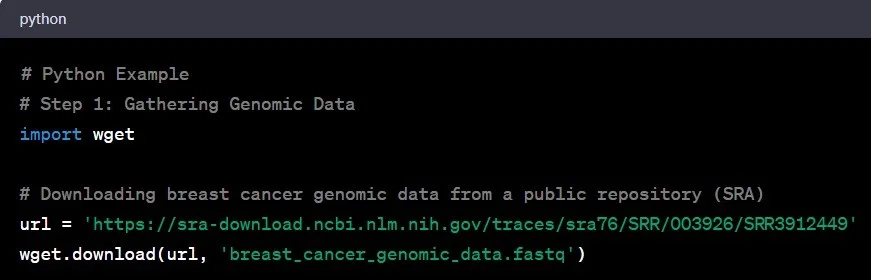
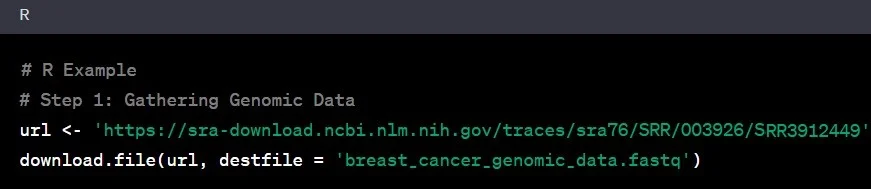
به دادههای ژنومی به عنوان ماده اولیه برای کار تحقیقاتی ژنتیکی خود نگاه کنید. این دادهها در فرمتهای مختلف مانند FASTQ، BAM یا VCF موجود هستند. تصور کنید به کتابخانهای بزرگ از اطلاعات ژنتیکی وارد شدهاید که مانند آرشیو NCBI Sequence Read Archive (SRA) است، جایی که دانشمندان از سراسر جهان یافتههای ژنومی خود را در آنجا قرار میدهند. فرض کنید شما به بررسی تغییرات ژنتیکی در سرطان سینه علاقهمند هستید؛ در این صورت، دادههای ژنومی مرتبط با این موضوع را از SRA دانلود میکنید یا با یک موسسه تحقیقاتی معتبر در زمینه ژنومیک سرطان همکاری میکنید.
مثال: شما به پایگاه داده SRA دسترسی پیدا کرده و دادههای ژنومی مربوط به مطالعهای بر روی بیماران مبتلا به سرطان سینه را دانلود میکنید.
مرحله ۲: پیشپردازش دادهها
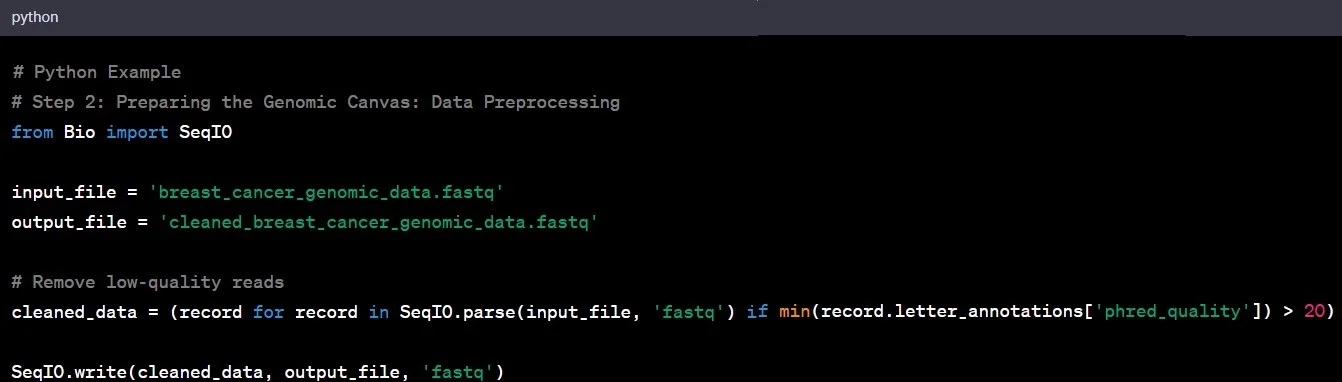
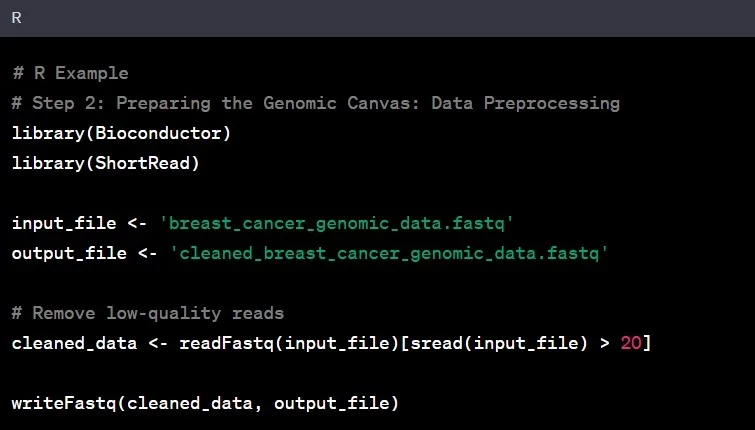
حالا که دادههای خام را داریم، زمان پاکسازی آن است؛ مانند آمادهسازی یک بوم نقاشی قبل از شروع نقاشی. این مرحله که به آن پیشپردازش داده میگویند، شامل حذف نویز، تصحیح خطاها و اطمینان از کیفیت کلی داده است.
مثال: در مطالعه سرطان سینه، شما میتوانید خوانشهای با کیفیت پایین را حذف کرده و اطمینان حاصل کنید که دادههای باقیمانده برای تحلیل بعدی قابل اعتماد هستند.
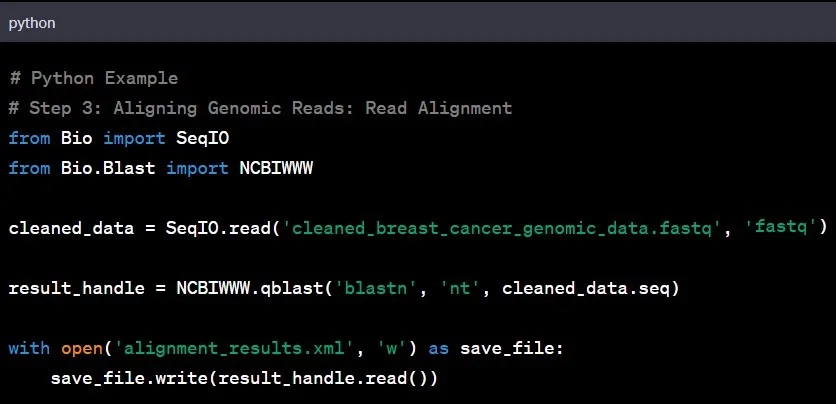
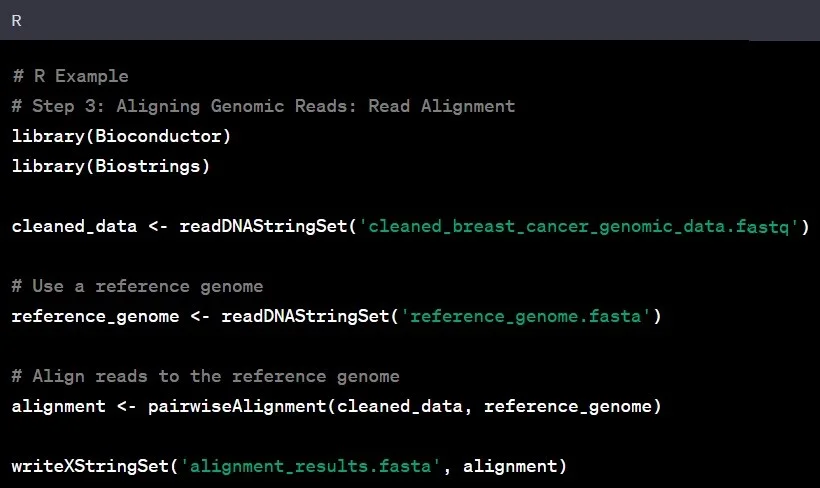
مرحله ۳: تراز کردن خوانشها
خواندن توالی ژنومی مرحله بعدی در تحلیل دادههای ژنومی است. تراز کردن دادههای تمیز شده با یک ژنوم مرجع به شناسایی تغییرات و درک چشمانداز کلی ژنوم کمک میکند. این کار مانند کنار هم قرار دادن قطعات یک پازل برای ایجاد تصویر بزرگتر است.
مثال: تراز کردن دادههای ژنومی یک فرد با تبار آسیایی با ژنوم مرجع بر اساس افراد تبار اروپایی ممکن است تغییرات ژنتیکی منحصربهفرد خاص جمعیت آسیایی را آشکار کند.
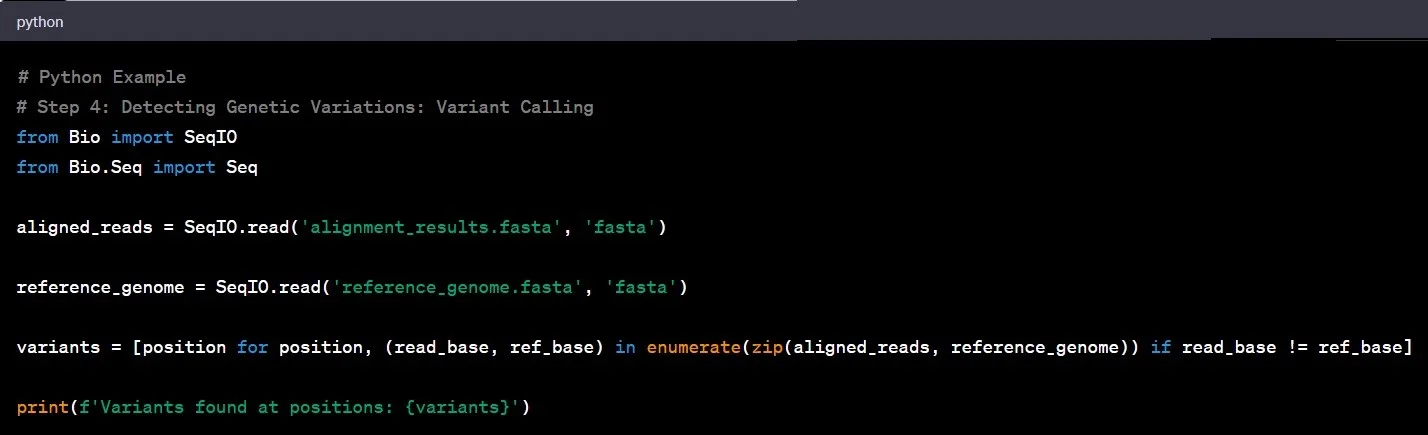
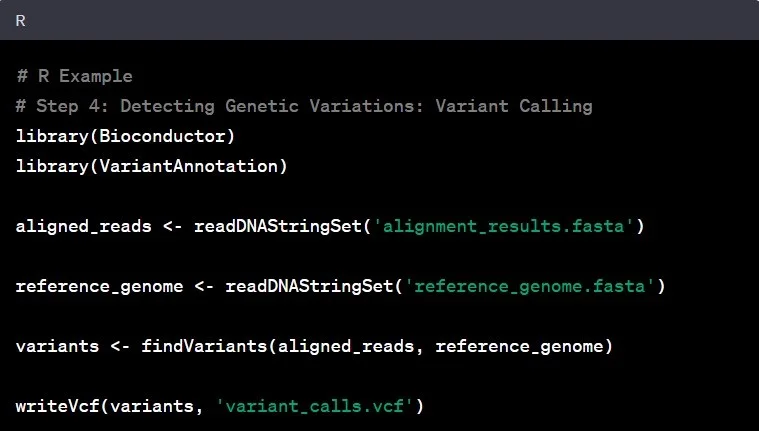
مرحله ۴: تشخیص واریانت
تشخیص واریانت شامل شناسایی تغییرات ژنتیکی، تفاوتهای بین خوانشهای تراز شده و ژنوم مرجع است. نمونههای رایج در تحلیل دادههای ژنومی شامل شناسایی پلیمورفیسمهای تکنوکلئوتیدی (SNP) و درجها/حذفها (indel) از طریق مقایسه خوانشهای تراز شده با ژنوم مرجع است.
مثال: شناسایی یک پلیمورفیسم تکنوکلئوتیدی (SNP) در ژن BRCA1 میتواند اطلاعات حیاتی در مورد حساسیت به سرطان سینه فراهم کند.
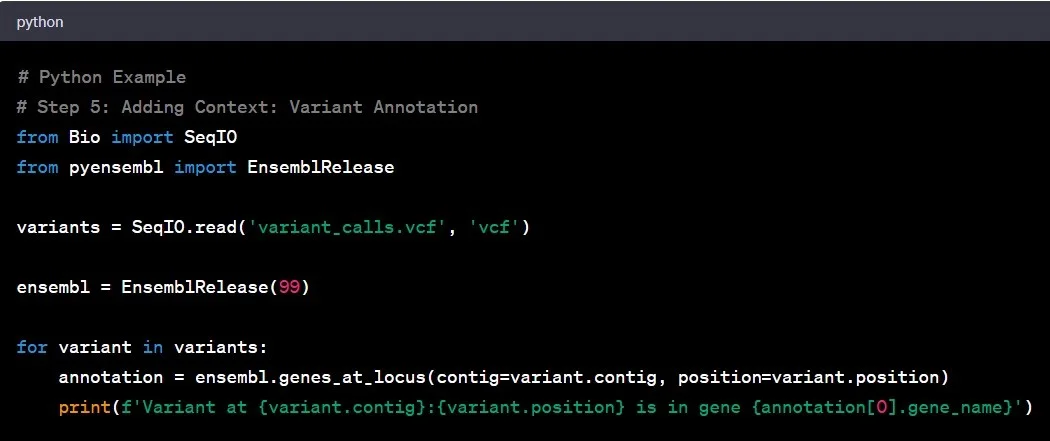
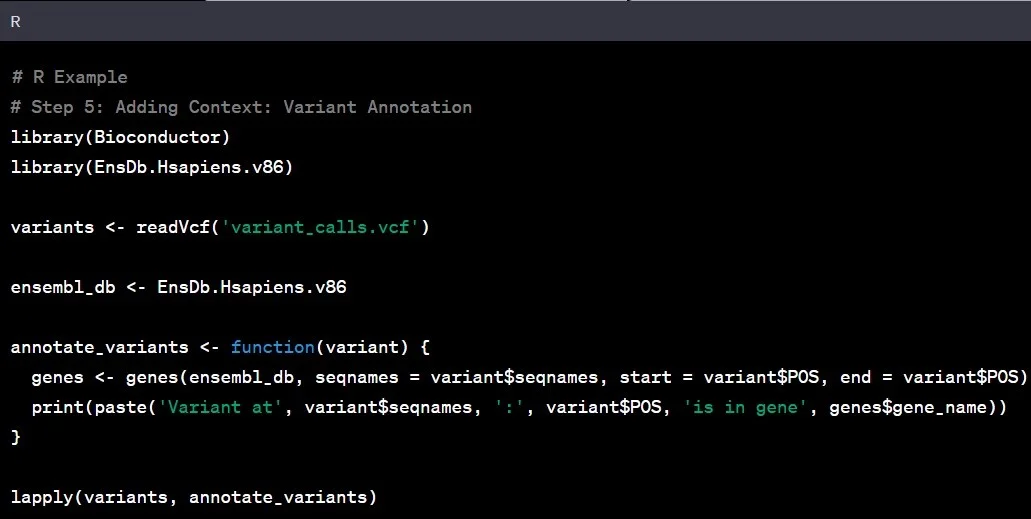
مرحله ۵: توضیحات واریانت
توضیحات واریانت را میتوان به عنوان افزودن زیرنویس به متن ژنومی در نظر گرفت. این مرحله شامل درک اهمیت عملکردی واریانتهای شناسایی شده و تاثیر احتمالی آنها بر ژنها است. این کار مانند رمزگشایی از معنی پشت کلمات در یک کتاب است.
مثال: شناسایی یک واریانت در ژن سرکوبکننده تومور ممکن است نشاندهنده خطر بیشتر ابتلا به سرطان باشد و بینشهای ارزشمندی برای استراتژیهای درمانی بالقوه ارائه دهد.
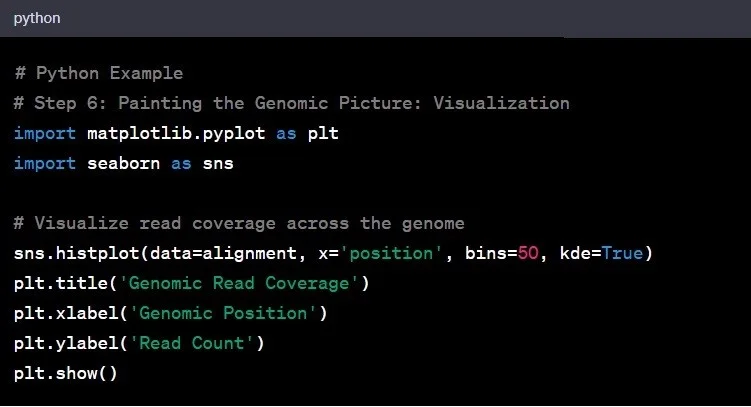
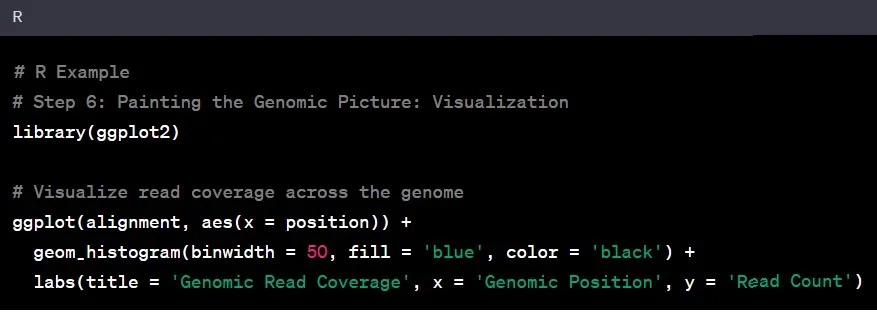
مرحله ۶: بصریسازی دادهها
حالا که دادههای ژنومی و بینشهای خود را داریم، زمان بصریسازی یافتههاست. بصریسازی، هنر تبدیل دادههای خام به داستانهای معنادار است. این مرحله ضروری است تا تحلیل دادههای ژنومی به بینشهای عمیقتری منجر شود و امکان انتقال مؤثر یافتهها فراهم شود.
مثال: نمودار کردن پوشش ژنومی میتواند نواحی با عمق توالیسازی بیشتر یا کمتر را آشکار کند و به این ترتیب مسیرهای بیشتری برای مطالعه در آینده فراهم کند.
نتیجهگیری:
تحلیل دادههای ژنومی فرآیندی چندوجهی است که شامل مراحل کسب، پیشپردازش، تراز کردن، تشخیص واریانت، توضیحات واریانت و بصریسازی دادهها است. ادغام یکپارچه پایتون و R در این راهنما، جعبهابزار متنوعی را برای محققان و دانشمندان داده در این حوزه فراهم میکند. مسلط شدن بر این مراحل و تکنیکها نه تنها به درک ژنوم کمک میکند، بلکه به پیشرفتها در حوزه در حال تکامل علوم دادههای زیستی و تحقیقات ژنومی کمک میکند.
منبع: datascienceforbio.com