
همزمان با پیشرفت علم و تکنولوژی، دانشمندان به طور عمیقتری در علم ژنتیک کاوش میکنند. تجزیه و تحلیل و تفسیر این داده های ژنومیِ جمع آوری شده به درک بهتر سلامت و بیماری انسان کمک میکند.
برآوردها پیشبینی میکنند که تحقیقات ژنومیک در دهه آینده بین ۲ تا ۴۰ اگزابایت داده تولید خواهد کرد. توانایی ما برای تعیین توالی DNA و تولید داده، بسیار بیشتر از توانایی ما در رمزگشایی اطلاعات موجود در آن است، بنابراین Genomic Data Science برای سال های آینده یک زمینه تحقیقاتی ارزشمند خواهد بود.

Genomic Data Science چیست؟
Genomic Data Science زمینهای از مطالعات علمی است که محققان را قادر میسازد تا از روشهای محاسباتی و آماریِ قدرتمند برای رمزگشایی اطلاعاتِ عملکردی که در توالیهای DNA مخفی شدهاند، استفاده کنند. این ابزارهای علم داده که در زمینه پزشکی ژنومی به کار می روند، به محققان و پزشکان کمک می کنند تا میزان تفاوت در DNA و چگونگی تاثیر این تفاوتها بر سلامت و بیماری انسان را کشف کنند.
Genomic Data Science به عنوان یک زمینه علمی جدید در دهه 1990 ظهور کرد تا دو فعالیت آزمایشگاهی را به هم مرتبط سازد:
- آزمایش: تولید اطلاعات ژنتیکی از مطالعه ژنوم موجودات زنده.
- تجزیه و تحلیل داده ها: استفاده از ابزارهای آماری و محاسباتی برای تجزیه و تحلیل و تجسم داده های ژنومی. این تجزیه و تحلیلها شامل پردازش و ذخیره داده ها و همچنین استفاده از الگوریتم ها و نرم افزارها برای پیش بینی بر اساس داده های ژنومی موجود است.
هر دو فعالیت به محققان کمک میکنند تا از حجم زیادی از طلاعات را از دادههای ژنومی به دست آورند.
چرا ژنومیک شامل داده های بسیار زیادی است؟
ژنومیک انسانی در اوایل دهه 2000 توجه جریان اصلی را به خود جلب کرد، زمانی که پروژه ژنوم انسانی با موفقیت اولین توالی از پایه های شیمیایی (A، C، G و T) را در ژنوم انسان ایجاد کرد. هر یک از تریلیون ها سلول در بدن انسان حاوی یک کپی کامل از ژنوم است، یعنی نقشه DNA ما. بیشتر سلول ها در واقع دو نسخه از ژنوم دارند که روی هم حدود 6 میلیارد حرف DNA را نشان میدهند.
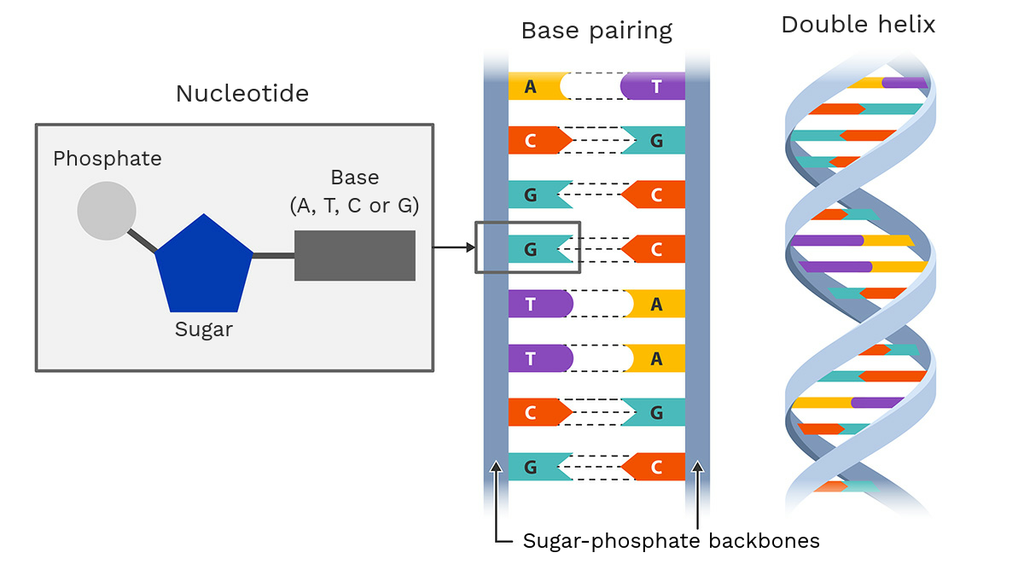
محققان در حال حاضر بیشتر از هر زمان دیگری داده های ژنومی تولید می کنند تا بفهمند ژنوم چگونه عمل می کند و بر سلامت و بیماری انسان تأثیر می گذارد؟
این داده ها از میلیون ها نفر در جمعیت های مختلف در سراسر جهان به دست می آید. اطلاعات مربوط به یک توالی ژنوم انسانی به تنهایی 200 گیگابایت را اشغال می کند. برای ذخیره داده های توالی ژنوم تولید شده در سراسر جهان تا سال 2025 به 40 اگزابایت نیاز داریم. برای مقایسه؛ تمام کلماتی را که انسانها تا کنون گفتهاند، برای ذخیره سازی فضایی حدود 5 اگزابایت احتیاج دارد.
از آنجایی که داده های پیچیده مرتبط با ژنوم انسان بسیار زیاد است و حجم عظیمی از دیتا را داریم، ژنتیک اکنون به عنوان یک زمینه “بیگ دیتا” در نظر گرفته می شود.

مطالعه و استفاده از داده های ژنومی
محققان برای یافتن و تفسیر اطلاعات بیولوژیکی پنهان در DNA هر فرد و همچنین مدیریت حجم زیادی از داده های تولید شده در پروژه های تحقیقاتی ژنومیک، به ابزارهای محاسباتی و تحلیلی خاصی نیاز دارند.
محققان از ابزارهای نرم افزاری به نام aligners برای تعیین محل قرارگیری تک تک توالی DNA در هر قسمت از یک توالی ژنوم مرجع استفاده می کنند.
در مرحله بعد، “افراد مختلفی” مکان هایی را شناسایی می کنند که یک توالی ژنوم انسانیِ مورد نظر با سایر توالی های ژنوم انسانی متفاوت است. این تفاوتهای ژنومی ممکن است در اندازههای مختلفی باشند. این تفاوت ممکن است به کوچکی یک حرف DNA (به نام چندشکلی تک نوکلئوتیدی)، حروف طولانی (به نام انواع ساختاری) مانند کم یا زیاد شدن، یا ناهنجاری های کروموزومی بسیار بزرگتر باشد. این تفاوتهای ژنومی ممکن است هیچ خطری برای سلامتی نداشته باشند، یا میتوانند مستقیماً باعث اختلالات نادر ارثی، سرطان یا سایر بیماریهای شایعتر شوند.

مدیریت و ذخیرهسازی حجم بالای داده های ژنومی
متخصصان در هر دو فناوری رایانه و ژنومیک، داده های ژنومی را با استفاده از سیستم ها و نرم افزارهای مختلف رایانه ای مدیریت و ذخیره می کنند. مراکز تحلیل و هماهنگی داده ها به طور فزاینده ای بخشی از شبکه های تحقیقاتی هستند و این خدمات را ارائه می دهند.
تولید دادههای ژنومی نیازمند حمایت مالی قابل توجهی از سوی مؤسسههایی مانند مؤسسه ملی تحقیقات ژنوم انسانی (NHGRI) است که هر سال بیش از ۱۲۵ میلیون دلار برای حمایت از تلاشهای مختلف علم دادههای ژنومی ارائه میکند.
منابع داده های تولید شده اغلب در دسترس جامعه علمی گسترده تر قرار می گیرند تا تجزیه و تحلیل بیشتر داده ها را تسهیل کنند. آنها انواع مختلفی از اطلاعات را در مورد ژنوم انسان سازماندهی کرده و ارائه می دهند، مانند مکان ژن ها و انواع مختلف آنها در DNA.

بسیاری از پلتفرمهای ابری خصوصی و تجاری با همکاری نهادهای دولتی و عمومی، مانند مؤسسه ملی بهداشت (NIH) از طریق ابتکار STRIDES کار میکنند. این طرحها زیرساختهای ذخیرهسازی و محاسباتی را برای میزبانی دادههای ژنومی و ایجاد حفاظتهای امنیتی و حریم خصوصی لازم برای دادههای ژنومی فراهم میکنند. این مباحث امنیتی و حریم خصوصی برای ژنوم انسان به طور ویژهتری انجام میشود.
برخی از پیامدهای اخلاقی، قانونی و اجتماعی به اشتراک گذاری داده های ژنومی
انجام تحقیقات ژنومیک مجموعه ای از مسئولیت های اخلاقی را به همراه دارد، زیرا اطلاعات مربوط به توالی ژنوم یک فرد با مسائل پیچیده مربوط به حریم خصوصی و هویت مرتبط است.
رضایت آگاهانه: محققان معمولاً از افرادی که ژنوم آنها توالی یابی شده است، رضایت می خواهند. اما محققان باید اطلاعات روشنی در مورد نحوه استفاده و به اشتراک گذاری داده های توالی ژنوم در فرآیند کسب چنین رضایت آگاهانه ارائه دهند.
حریم خصوصی: ابزارهای محاسباتی قدرتمند میتوانند دادههای توالی ژنومهای شناساییشده را بگیرند و تحت شرایط خاص، آنها را به فردی که DNA او توالییابی شده است، متصل کنند. بازرسان می توانند از چنین ابزارهایی برای اهداف مفیدی مانند شناسایی مجرمانی که DNA را در صحنه جرم به جا گذاشته اند، استفاده کنند. اما مزایای اجتماعی باید بر خطرات احتمالی استفاده از دادههای ژنومی به این روش بیشتر باشد.

هوش مصنوعی (AI): ابزارهای هوش مصنوعی به طور فزاینده ای به محققان کمک می کنند تا مقادیر زیادی از داده های توالی ژنوم را پردازش کنند تا الگوهای پنهان در DNA را جستجو کنند. با این حال، از آنجایی که الگوریتمهای هوش مصنوعی اغلب فاقد شفافیت هستند، زمانی که چنین الگوریتمهایی روی دادههای DNA اعمال میشوند، سوگیریها میتوانند شناسایی نشده باشند.
این حوزه از علم دادههای ژنومی به تحقیقات اخلاقی گسترده نیاز دارد تا تفاوتهای منحصربهفرد بین روشهای فعلی در علم دادههای ژنومی (که برای تفسیر نتایج به هوش انسانی متکی است) و روشهای جدیدتر هوش مصنوعی را بررسی کند. در حالی که روشهای هوش مصنوعی مزایای امیدوارکننده زیادی را ارائه میدهند، آنها همچنین به روشهای کاملاً متفاوتی نسبت به انسانها نتیجهگیری میکنند و از این رو باید تحت نظارت دقیق اخلاقی قرار گیرند.

با تمام این ملاحظات، دانشمندان داده و محققان ژنومیک باید در مورد پیامدهای مطالعات خود آموزش ببینند و از نزدیک با محققان اخلاق همکاری کنند.
اشتراک گذاری داده های ژنوم انسان
انتظار می رود که محققان داده های ژنومی انسان را بر اساس رضایت شرکت کنندگان در تحقیق به اشتراک بگذارند. دادههای ژنومی معمولاً از طریق منابع داده با جامعه علمی به اشتراک گذاشته میشوند که میتوان به سه روش به آنها دسترسی داشت:
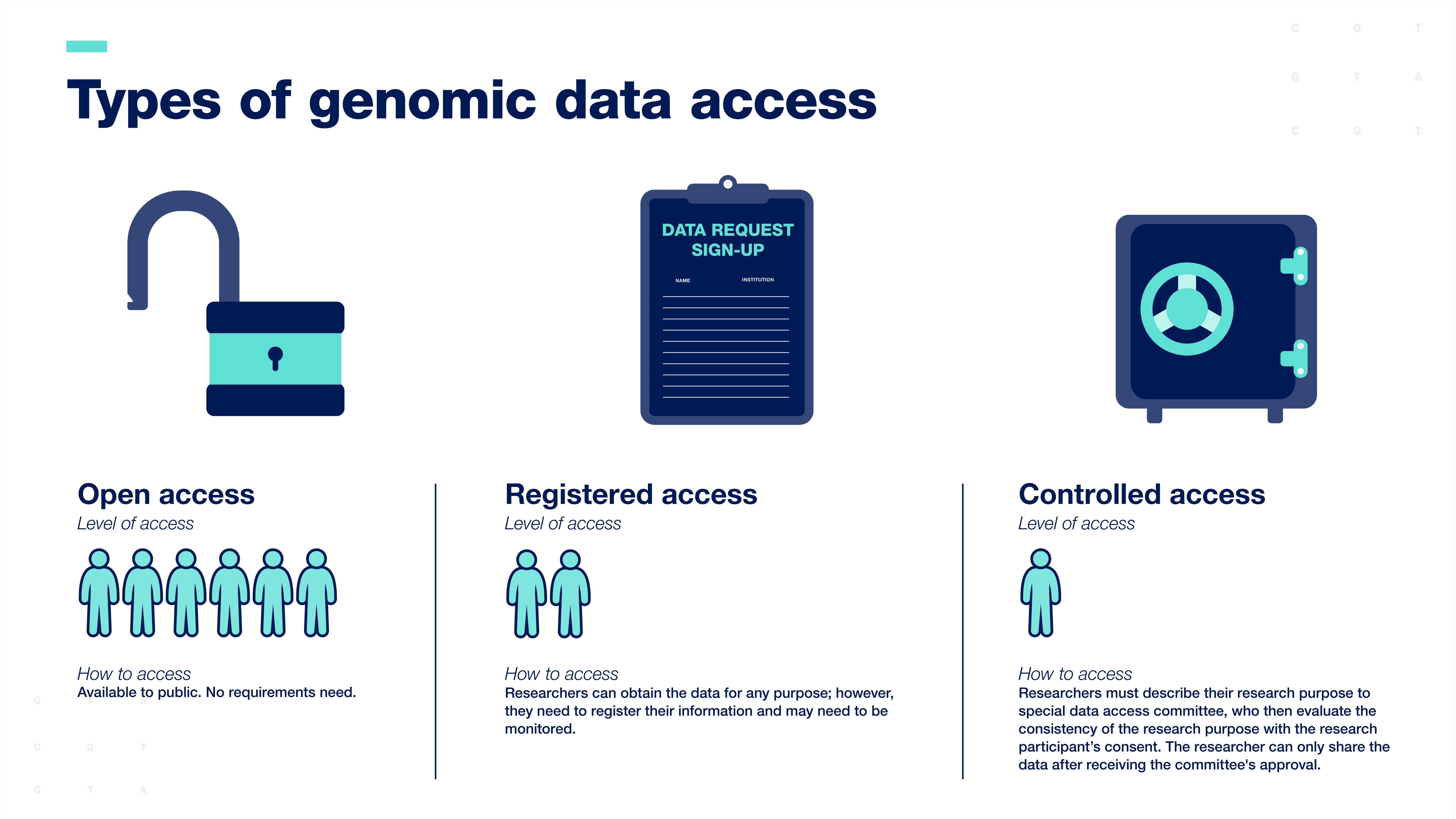
دسترسی آزاد یا دسترسی نامحدود گسترده ترین شکل اشتراک داده است. داده ها برای هر هدف پژوهشی در دسترس عموم است.
دسترسی ثبت شده بین دسترسی باز و دسترسی کنترل شده قرار می گیرد. محققان می توانند داده ها را برای هر هدفی به دست آورند. با این حال، آنها باید اطلاعات خود را ثبت کنند و کار آنها با داده ها ممکن است نیاز به نظارت داشته باشد.
اشتراکگذاری دادهها با دسترسی کنترلشده، محققین را ملزم میکند که هدف تحقیق خود را توصیف کنند تا یک کمیته ویژه دسترسی به دادهها بتواند سازگاری هدف تحقیق را با رضایت شرکتکننده ارزیابی کند. محقق تنها پس از دریافت تایید کمیته می تواند به داده ها دسترسی داشته باشد.