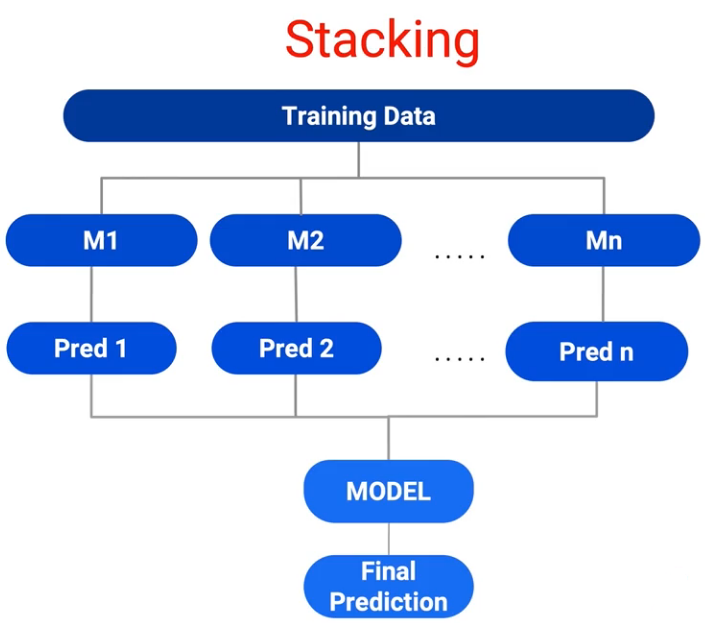
رویکرد Stacking در یادگیری گروهی بر اساس ترکیب مدل های پایه با الگوریتم های متفاوت انجام می شود. بنابراین در این رویکرد عمدتا از الگوریتم های با ساختارهای مختلف استفاده می شود و با ادغام نتایج آنها، پیش بینی نهایی حاصل می شود.
ایده اصلی در این رویکرد این است که ساختارهای متفاوت از الگوریتم های پایه توانایی تشخیص الگوهای متفاوتی در داده ها را دارند که ادغام آنها منجر به بهبود تصمیم گیری و پیش بینی می شوند.
در ادغام نتایج مدل های پایه در رویکرد Stacking، معمولا از یک مدل جدید با عنوان Metaclassifier استفاده می شود و پیش بینی مدل های پایه به عنوان ورودی مدل متا در نظر گرفته می شود.
رویکرد Stacking معمولا با هدف بهبود کارایی مدل و کاهش بایاس و واریانس مدل مورد استفاده قرار می گیرد؛ اما بطور ویژه اثر زیادی در کاهش واریانس و بیش برازشی دارد.
استفاده از مدل های پایه با ساختار های متفاوت و همچنین خروجی های متفاوت، به خصوص در مسائل رگرسیون (که تفاوت در پیش بینی مقادیر هدف توسط مدل های پایه زیاد است) از جمله مواردی هست که رویکرد Stacking با کاهش بایاس به ارتقای مدل کمک می کند.
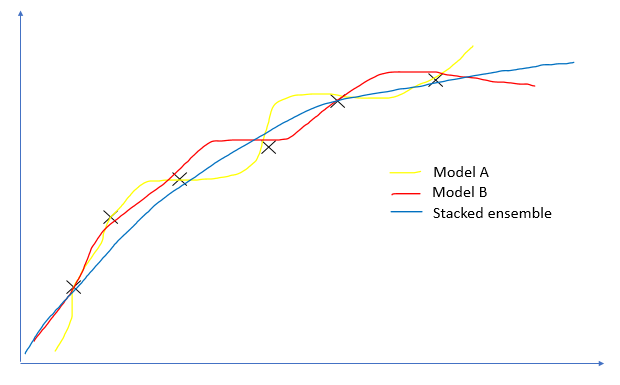
در مثال روبرو، مدل A و مدل B مدل های با مقدار بایاس کم و واریانس بالا هستند که با دقت بسیار زیاد بر روی داده های نمونه دچار بیش برازش شده اند. رویکرد Stacking توانایی کاهش واریانس مدل را فراهم می سازد تا مدل مقاوم تر و پایدارتری یا ایجاد نماید.
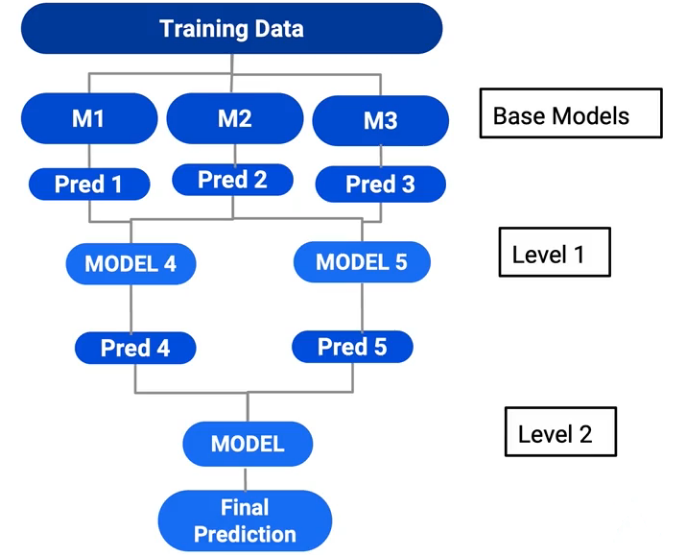
ادغام پیش بینی مدل های پایه، می تواند در چندین لایه یا سطح انجام پذیرد. در این حالت در لایه اول ادغام، به جای استفاده از یک مدل متا، می توان از چندین مدل استفاده نمود و سپس پیش بینی های حاصل از هر مدل متای لایه اول را، در لایه دوم وارد مدل متای نهایی نمود.
نکته دیگری که در رویکرد Stacking وجود دارد، استقلال بین آموزش مدل های مختلف می باشد، به این معنی که هر یک از مدل ها دارای فرضیات مربوط به خود هستند. به همین دلیل این رویکرد در چارچوب یادگیری گروهی مستقل قرار می گیرد.