مدل های پیشبینانه ابزاری برای پیش بینی نتایج آینده با استفاده از مدل سازی داده ها هستند. این یکی از راههایی است که یک کسبوکار میتواند مسیر خود را به جلو ببیند و بر اساس آن برنامهریزی کند. اگرچه این روش بیخطا نیست، اما نرخ دقت بالایی دارد، به همین دلیل است که بسیار مورد استفاده قرار میگیرد.
به طور خلاصه، مدل سازی پیش بینی یک تکنیک آماری با استفاده از یادگیری ماشین و داده کاوی برای پیش بینی و حدس نتایج احتمالی آینده با کمک داده های تاریخی و موجود است. مدلسازی پیشبینیکننده را میتوان برای پیشبینی تقریباً هر چیزی، از رتبهبندی تلویزیون و خرید بعدی مشتری گرفته تا ریسکهای اعتباری و درآمدهای شرکتی، مورد استفاده قرار داد.
مدل پیشگو یک مدل ثابت نیست و به طور منظم تغییر می کند و یا تجدید نظر می شود تا تغییرات در داده های اساسی را در بر گیرد. به عبارت دیگر، این کار یک پیشبینی یکباره نیست. مدل های پیش بینی بر اساس آنچه در گذشته اتفاق افتاده و آنچه اکنون در حال وقوع است، مفروضاتی را ایجاد می کنند و اگر دادههای جدید، تغییراتی را در آنچه اکنون اتفاق میافتد نشان دهد، تأثیر آن بر نتیجه احتمالی آینده نیز باید دوباره محاسبه شود.
برای مثال، یک شرکت نرمافزاری میتواند دادههای فروش تاریخی را در برابر هزینههای بازاریابی در چندین منطقه مدلسازی کند تا بر اساس تأثیر مخارج بازاریابی، مدلی برای درآمدهای آینده ایجاد کند.
اکثر مدل های پیش بینی کننده سریع کار می کنند و اغلب محاسبات خود را به صورت real time کامل می کنند.
به همین دلیل است که بانکها و خردهفروشان میتوانند، برای مثال، ریسک یک درخواست آنلاین وام مسکن با کارت اعتباری را محاسبه کنند و بر اساس آن پیشبینی تقریباً فوراً درخواست را بپذیرند یا رد کنند.
برخی از مدلهای پیشبینی پیچیدهتر هستند، مانند مدلهایی که در زیستشناسی محاسباتی و محاسبات کوانتومی استفاده میشوند. محاسبه خروجیهای حاصل از برنامههای کارت اعتباری بیشتر طول میکشد، اما به لطف پیشرفت در قابلیتهای تکنولوژیکی، از جمله قدرت محاسباتی، بسیار سریعتر از آنچه در گذشته امکانپذیر بود، انجام میشوند.
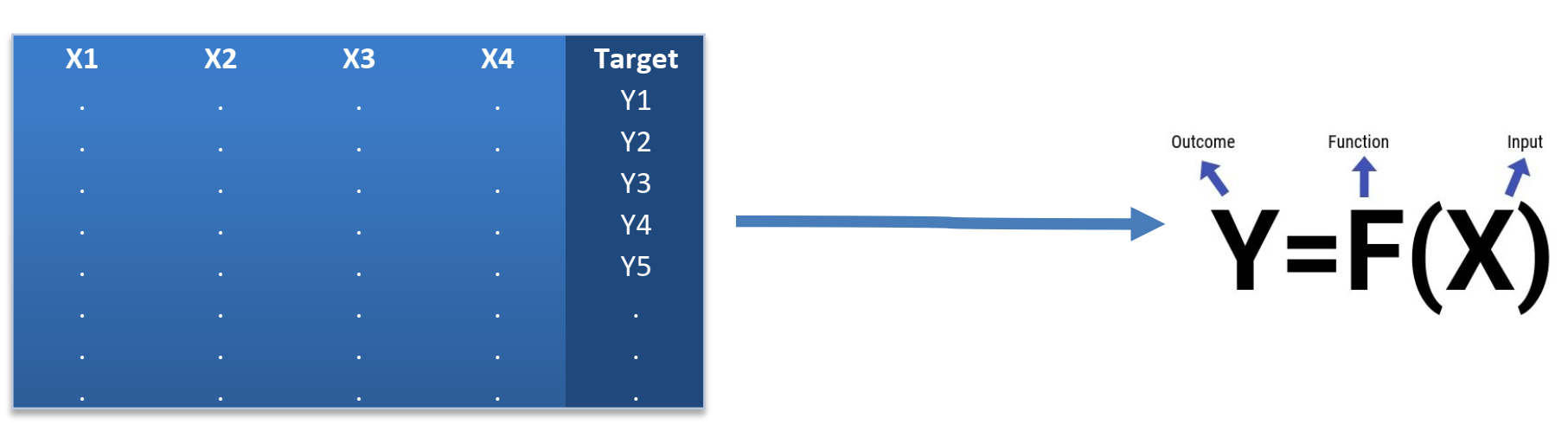
مدل های پیش بینانه با رویکرد یادگیری با نظارت به دنبال یافتن تابعی از ویژگی های ورودی هستند تا مقدار فیلد هدف را با کمترین میزان خطا برآورد نمایند.
هر یک از الگوریتم های مورد استفاده با استفاده از روش های خاص خود برای یافتن پاسخ به این هدف، نقاط قوت و ضعف خود را دارند.
انواع الگوریتم های پیش بینانه بر اساس توزیع آماری فیلد هدف

انواع الگوریتم های پیش بینانه بر اساس نوع رابطه بین ویژگی ها و فیلد هدف

بر اساس تفسیرپذیری الگوها

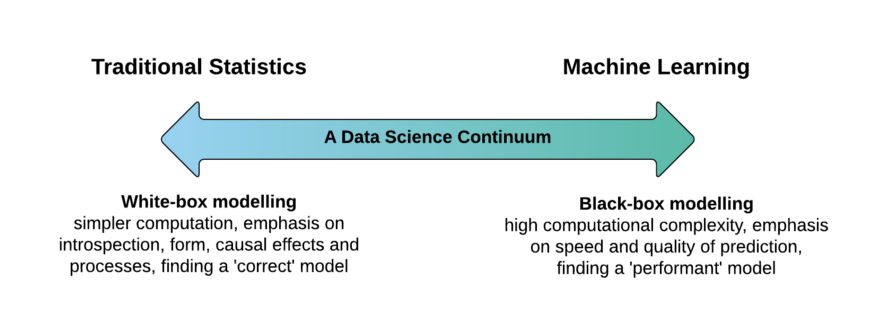
White-Box
مدلی است که منطق درونی، مراحل کار و درک آن شفاف است و بنابراین فرآیند تصمیم گیری آن قابل تفسیر است. درختهای تصمیم ساده رایجترین نمونه مدلهای جعبه سفید هستند در حالی که نمونههای دیگر مدلهای رگرسیون خطی، شبکههای بیزی و نقشههای شناختی فازی (Fuzzy Cognitive Maps) هستند. به طور کلی، مدل های خطی و یکنواخت ساده ترین مدل ها برای توضیح هستند. مدلهای White-Box برای کاربردهایی که نیاز به شفافیت در پیشبینیهایشان مانند پزشکی و مالی دارند، مناسبتر هستند .
Black-Box
برخلاف White-Box، Black-Box اغلب یک مدل ML دقیق تر است که عملکرد داخلی آن مشخص نیست و تفسیر آن دشوار است، به این معنی که برای مثال، یک تستر نرم افزار فقط می تواند ورودی های مورد انتظار و خروجی های مربوطه را بداند. مدل شبکههای عصبی عمیق یا کم عمق رایجترین نمونههای مدلهای جعبه سیاه ML هستند.
نمونههای دیگر ماشینهای بردار پشتیبان و همچنین روشهای مجموعهای مانند تقویت و جنگلهای تصادفی هستند. به طور کلی، مدل های غیر خطی و غیر یکنواخت سخت ترین توابع برای توضیح هستند. بنابراین، بدون درک کامل عملکرد درونی آنها، تحلیل و تفسیر پیشبینیهای آنها تقریباً غیرممکن است.
Gray-Box
جعبه خاکستری ترکیبی از مدل های جعبه سیاه و جعبه سفید است. هدف اصلی یک مدل جعبه خاکستری، توسعه مجموعه ای از مدل های جعبه سیاه و سفید است، به منظور ترکیب و به دست آوردن مزایای هر دو، ساخت یک مدل ترکیبی کارآمدتر.
به طور کلی، هر مجموعه ای از الگوریتم های یادگیری ML که شامل هر دو مدل جعبه سیاه و سفید باشد، مانند شبکه های عصبی و رگرسیون خطی، می تواند به عنوان یک جعبه خاکستری در نظر گرفته شود.
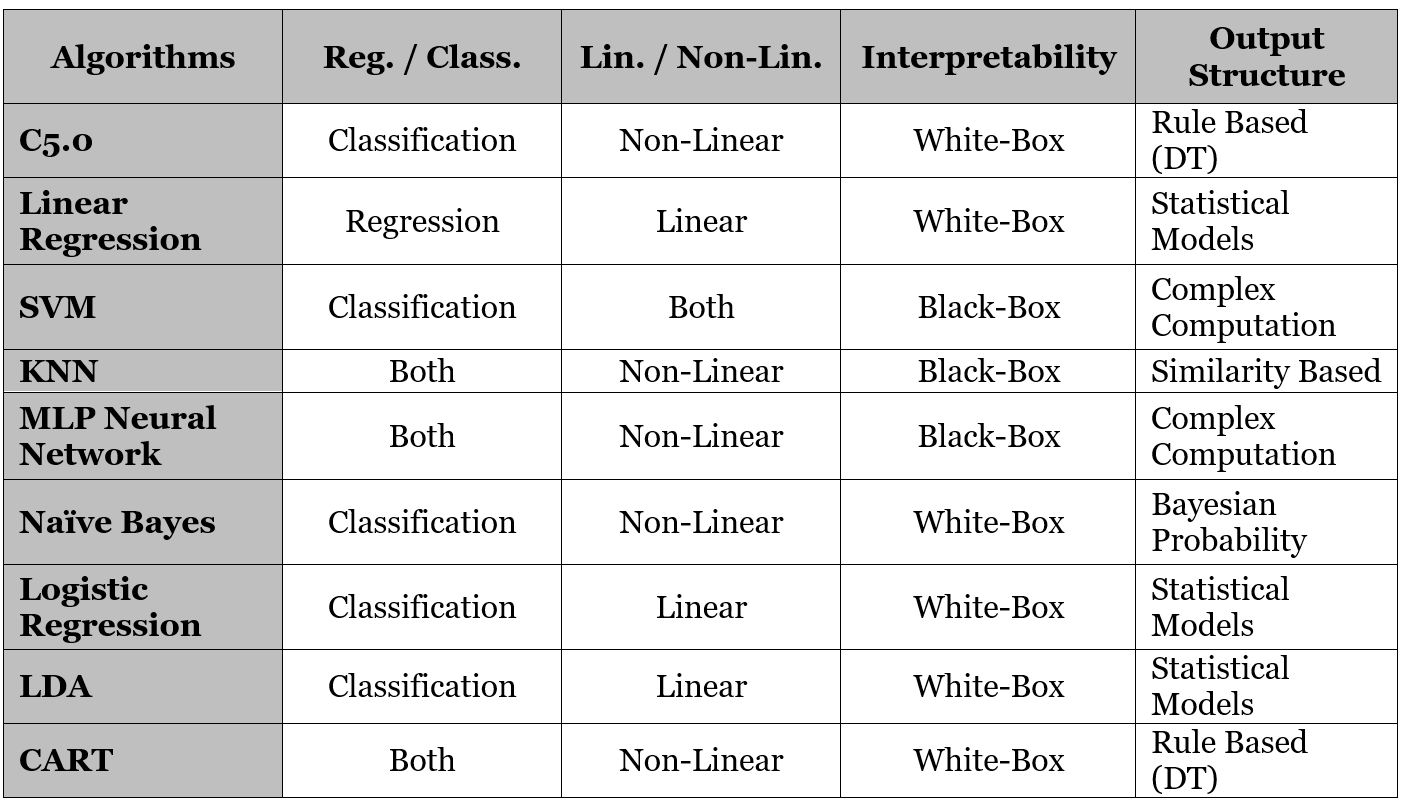
بر اساس ساختار و فرمت خروجی

انواع الگوریتم های پیش بینانه
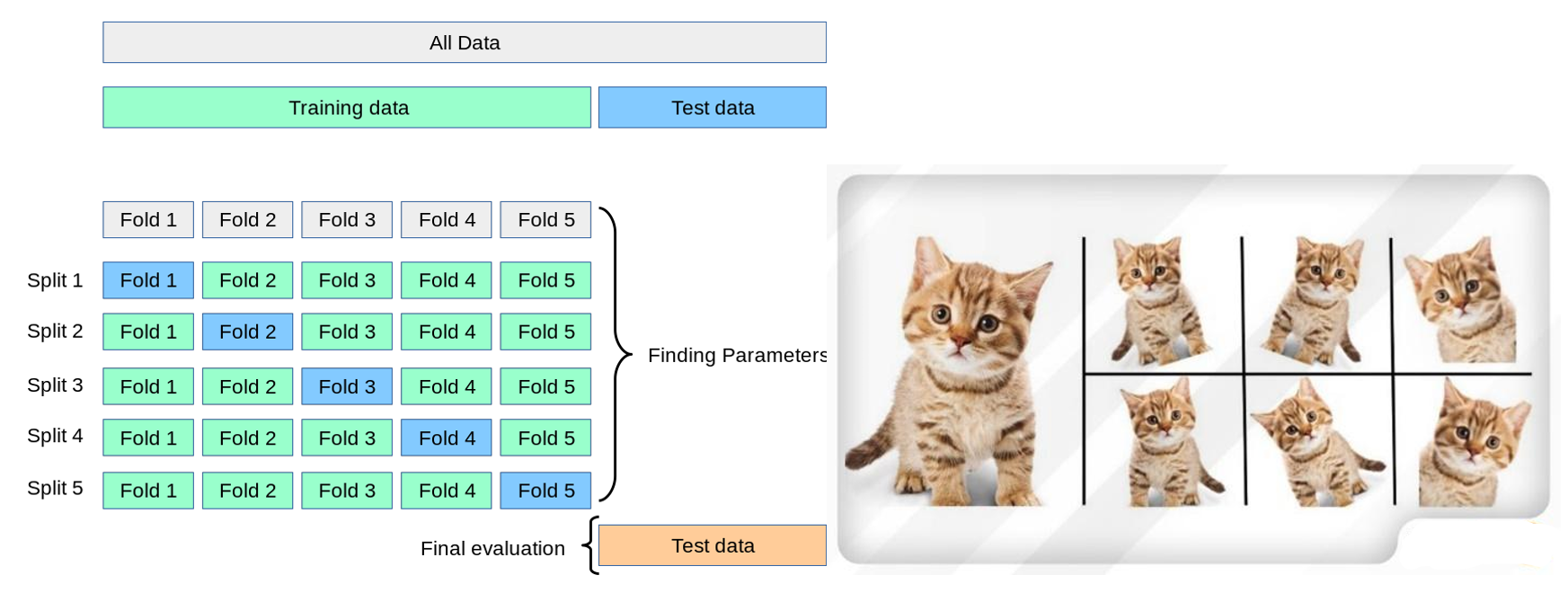
طرح آزمون برای مدلسازی
رایج ترین طرح آزمون، افراز کاملا تصادفی مجموعه داده ها به دو بخش داده های آموزشی و داده های آزمایشی می باشد.
روش Holdout
در این روش به طور تصادفی، دادهها به دو بخش آموزشی و اعتبارسنجی تقسیم میشود. پارامترهای مدل توسط دادههای آموزشی برآورد شده و برآورد خطای مدل نیز براساس دادههای اعتبارسنجی محاسبه میشود.
اگر دادههای مربوط به بخش آموزش و اعتبارسنجی همگن باشند، این روش مناسب به نظر میرسد. ولی از آنجایی که محاسبات خطای مدل براساس فقط یک مجموعه داده، بدست آمده ممکن است برآورد مناسبی برای خطای مدل ارائه نشود.
در این روش، دادهها به دو دسته train و test تقسیم میشوند. این تقسیم میتواند به صورت 40/60 ، 30/70 یا 20/80 باشد. بنابراین مدل مورد نظر روی دادههای train آموزش دیده و روی دادههای test مورد ارزیابی قرار میگیرد. به این روش، اعتبارسنجی Holdout گفته میشود.
در روش Holdout، اگر کلاسهای مختلف در هر گروه test یا train توزیع یکسانی نداشته باشند، مدل، درست آموزش نخواهد دید. از این جهت کلاسها باید توزیع یکسانی در هر دو گروه train و test داشته باشند. به این پروسه،stratification گفته میشود.
دو ایراد مهم به طرح Holdout وارد است:
- امکان ناپایداری نتایج ارزیابی و وابستگی مدل به انتخاب داده های آموزشی و آزمایشی
راهکار: تکرار روش Holdout و استفاده از برآیند آنها/استفاده از روش اعتبارسنجی متقابل - عدم قابلیت تنظیم پارامتر مستقل از داده های آزمایشی
راهکار: استفاده از تقسیم بندی سه تایی داده ها(آموزش، اعتبارسنجی و آزمایش)
Random Sub-sampling
در این تکنیک تعدادی از دادهها به صورت تصادفی انتخاب شده و دادههای تست را تشکیل میدهند. باقیمانده دادهها نیز برای آموزش مورد استفاده قرار میگیرند. نرخ خطای مدل در این روش نیز برابر با میانگین نرخ خطا در هر تکرار است. شکل زیر تکنیک Random Subsampling را نشان میدهد.
در این روش به تعداد K بار، روش Holdout تکرار می شود و سپس میزان دقت مدل از میانگین دقت K مدل بدست آمده محاسبه می شود.
روش اعتبارسنجی متقابل Cross Validation (K-Fold Cross-Validation)
به علت انتخاب تصادفی داده های آموزشی و آزمایشی در روش، Random Subsampling از ظرفیت کامل داده ها در آموزش، ساخت و ارزیابی مدل ها استفاده نمی شود.
در این روش با تقسیم مجموعه داده ها به K قسمت برابر، در هر مرتبه یکی از آنها به عنوان داده آزمایشی و مابقی به عنوان داده های آموزشی برای ساخت مدل استفاده می شوند؛ ارزیابی مدل با این روش از تمامی داده های در دسترس جهت ساخت مدل و ارزیابی استفاده می کند؛ ولی در داده های زیاد نیاز به زمان و محاسبات بیشتری خواهد داشت.
روش اعتبارسنجی متقابل (LOO) Leave One Out
نوع خاصی از روش اعتبارسنجی متقابل می باشد که در آن تعداد K برابر با تعداد نمونه ها می باشد. در این حالت به تعداد نمونه های در مجموعه داده ها بایستی مدل ساخته شود و هر بار با n-1 رکورد مدل آموزش داده شده و با یک رکورد تست می شود.
این رویکرد در مواردی که تعداد رکوردها کم باشد، گزینه خوبی برای ارزیابی مدل هست تا علاوه بر اینکه همه داده ها در ارزیابی مدل مشارکت داشته باشند، بلکه آموزش و ساخت مدل نیز از حداکثر داده های موجود استفاده کند.
در این تکنیک، از تمامی دادهها به جز یک داده برای آموزش و از داده باقی مانده برای تست مدل استفاده میشود. این فرآیند N بار تکرار میشود که N تعداد دادهها را نشان میدهد. مزیت این روش این است که از تمامی دادهها برای آموزش و تست مدل استفاده خواهد شد. نرخ خطای مدل در این روش برابر با میانگین نرخ خطا در هر تکرار است. شکل زیر تکنیک LOOCV را نشان میدهد.
ایراد دوم به طرح آزمون Holdout تنظیم پارامترهای مدل بر اساس نتایج ارزیابی روی داده های آزمایشی می باشد. میزان پیچیدگی یک مدل با کنترل و تنظیم پارامترهای آن، بر اساس مقایسه میزان خطای مدل در مجموعه داده های آموزشی و آزمایشی تعیین می گردد.
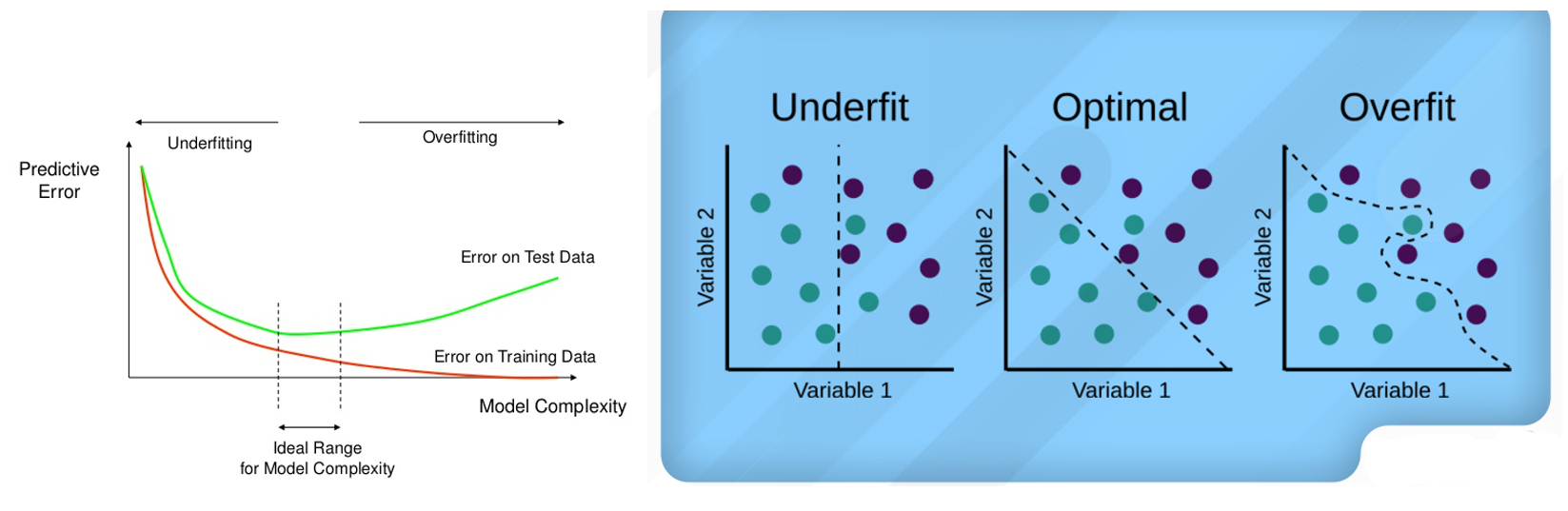
بیش برازش (Overfitting)
پیچیدگی زیاد مدل، منجر به حفظ کردن داده های آموزشی و عدم شناسایی الگوهای تعمیم پذیر می گردد.
کم برازشی (Underfitting)
سادگی بیش از حد مدل، منجر به کاهش صحت نتایج شده و ارزش مدلسازی را کم میکند.
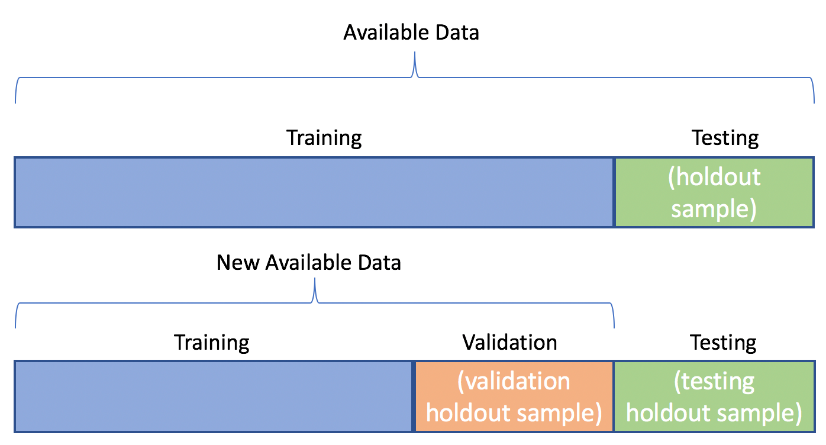
افراز مجموعه داده ها به سه بخش داده های آموزشی، داده ها اعتبارسنجی و داده های آزمایشی
● داده های آموزشی
برای آموزش و ساخت مدل بکار می رود.
● داده های اعتبارسنجی
برای تنظیم پارامترهای مدل بکار می رود.
● داده های آزمایشی
برای ارزیابی کیفیت مدل ساخته شده بکار می رود
روش اعتبارسنجی متقابل Cross Validation
کارکرد دیگر این روش در تنظیم پارامترهای مدل می باشد. با این هدف، به جای انتخاب مجموعه داده اعتبارسنجی بصورت Holdout می توان با روش اعتبارسنجی متقابل داده های آموزشی، تنظیمات پارامترهای مدل را انجام داد. ارزیابی مدل با این روش از تمامی داده های در دسترس جهت ساخت مدل و ارزیابی استفاده می کند؛ ولی در داده های زیاد نیاز به زمان و محاسبات بیشتری خواهد داشت.
ارزیابی مدل با این روش از تمامی داده های در دسترس جهت ساخت مدل و ارزیابی استفاده می کند؛ ولی در داده های زیاد نیاز به زمان و محاسبات بیشتر خواهد داشت.