داده های واقعی عموما دارای انواع مشکلات کیفی هستند که نیاز به پاکسازی را ضروری می نماید. استفاده از داده های خام و دارای مشکلات کیفی، منجر به کاهش عملکرد الگوریتم ها، اختلال در شناسایی الگوها و نتایج گمراه کننده می شود.
یکی از چالشهای مهم و جدی عدم وجود دادههای صحیح است. بهعنوان مثال پروفایلی که از مشتری وجود دارد، ممکن است ناقص و نادرست باشد یا باتوجه به گذشت زمان منسوخ شده باشد؛ نمونه آن در کسبوکار بانک این است که ۲۰ سال قبل که حساب افتتاح شده، مشتری دانشجو، بیکار و مستاجر بوده درحالیکه در حال حاضر اوضاع کامل متفاوت شده است. یا تغییراتی در دادهها در یک سیستم و سرویس انجام میشود که به دلیل عدم وجود پایگاه یکپارچه و افزونگی، دادهها با هم مغایر خواهند بود.
بنابراین ورودی زباله، خروجی زباله را در پی خواهد داشت. این اصل که به GIGO مشهور است، قانون اصلی محاسبات به شمار می رود و می گوید اگر داده های نامعتبر به سیستم وارد شود، خروجی به دست آمده نیز نامعتبر خواهد بود. اگرچه مفهوم GIGO از سال های حدود 1860 مطرح بوده است مفهوم دقیق آن توسط یک برنامه نویس IBM منتشر شده است.
برای درک بیشتر می توانیم داده های ثبت شده از خیرین یک موسسه خیره مطابق تصویر زیر مثال بزنیم:
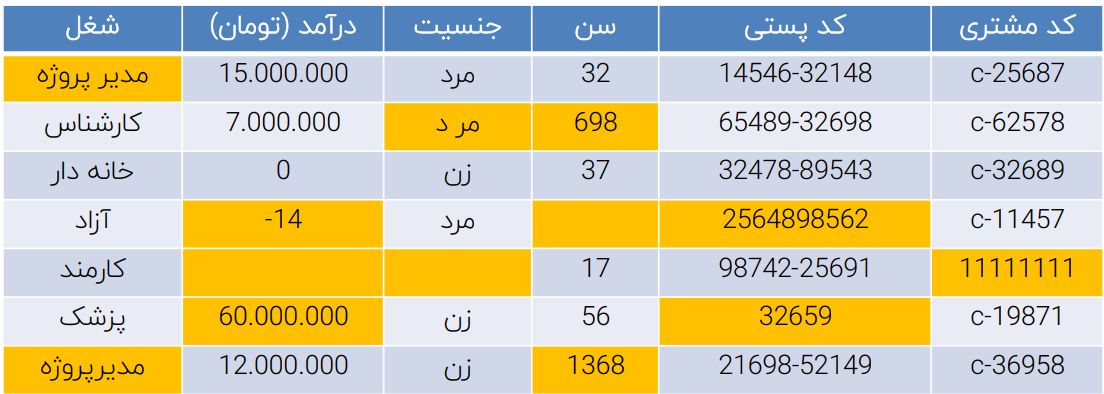
مطابق تصویر فوق فیلد هایی که به رنگ نارنجی در آمده اند دارای مشکلاتی نظیر ثبت دیتاهای اشتباه، با فرمت ناهمسان با فیلدهای مشابه، داده های غلط، داده های پرت و… مواجه هستیم. در صورتیکه پاکسازی داده ها انجام نشود و با داده های در دست وارد مرحله مدل سازی و بهره برداری از آن بشویم مطمئناً نتایج نامعتبری را بدست خواهیم آورد.
اگر بخواهیم مشکلات داده ها را به صورت طبقه بندی شده تقسیم نماییم می توانیم به 4 شاخص کیفیت داده ها اشاره کنیم:
خارج از بازه منطقی (Out of logical range) – در مثال فوق مثل درآمد 14-
ناسازگار (Inconsistent) – در مثال فوق مثل دو املای متفاوت عبارت “مدیر پروژه”
داده های پرت (Outliers) – در مثال فوق مثل سن 1368
داده های گمشده (Missing Data) – در مثال فوق مثل فیلد های تکمیل نشده در درآمد، جنسیت و…