
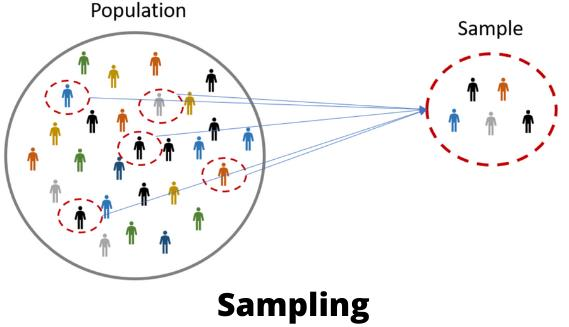
نمونه گیری یک روش آماری کم هزینه برای کاهش داده هاست تا بر اساس انتخاب زیرمجموعه ای از رکوردهای داده، نماینده مناسبی از داده ها را در حجم کمتر ایجاد نماید.
اهمیت نمونهگیری را میتوان صرفهجویی در زمان برای تهیه مشاهدات از جامعه آماری به منظور انجام تحقیق علمی دانست. معمولا نمونهگیری در مقابل سرشماری قرار دارد. سرشماری به منظور بررسی همه اعضای جامعه آماری به کار میرود ولی گاهی دسترسی به تمام اعضای این جامعه میسر نیست یا تعداد اعضای آن نامتناهی است.
مزایای استفاده از نمونه گیری:
- سرعت بیشتر اجرای الگوریتم ها
- نیاز به منابع محاسباتی کمتر
- تمرکز بر الگوهای اصلی و معنادار
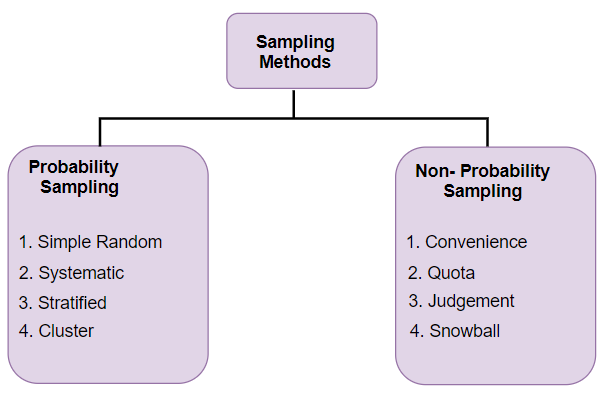
فرآیند انتخاب نمونه را می توان به دو دسته کلی تقسیم کرد:

روش های نمونه گیری
● نمونه گیری احتمالی
در این رویکرد نمونه های موجود در جامعه، دارای احتمال انتخاب برابر هستند.
به همین دلیل این رویکرد شانس خوبی برای انتخاب نمونه ای که به خوبی از جامعه نمایندگی کند را داراست.
● نمونه گیری غیراحتمالی
در این رویکرد نمونه های موجود در جامعه، دارای احتمال انتخاب نابرابر هستند، و این موضوع می تواند منجر به انتخاب نمونه ای شود که قابلیت تعمیم پذیری خوبی نداشته باشد.
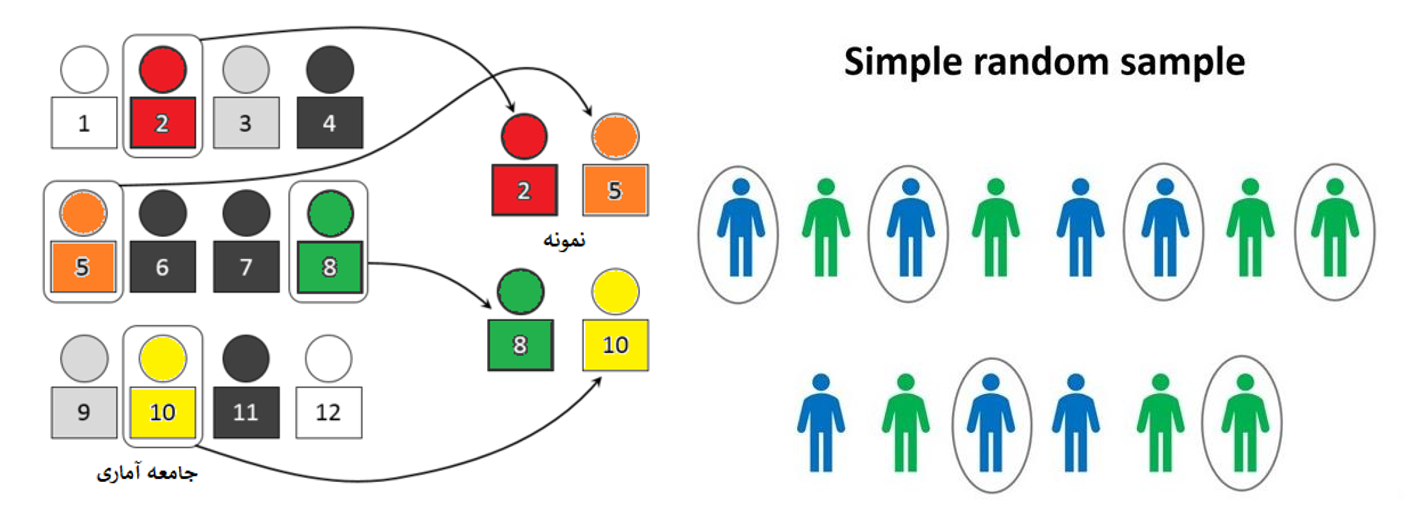
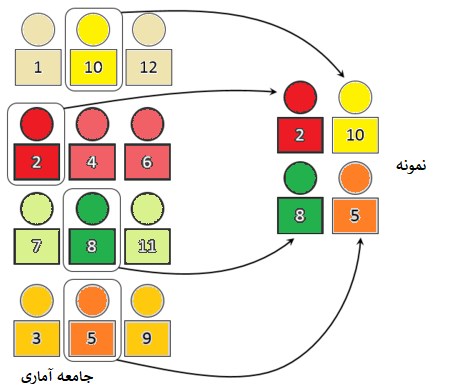
نمونه گیری تصادفی ساده
در نمونهگیری تصادفی ساده، همه اعضای جامعه آماری شانسی برابر برای انتخاب شدن در نمونه را دارند. در این حالت جامعه آماری یکپارچه است و قابل تفکیک به بخشهای مختلف نیست. این احتمال حتی برای هر زوج یا هر سهتایی و … نیز وجود دارد.
این گونه نمونهگیری باعث کاهش اریبی و سادگی در نتایج حاصله میشود. به این معنی که واریانس یا پراکندگی بین اعضای نمونه میتواند برآوردگر خوبی برای واریانس جامعه باشد. به این ترتیب خطای نتایج از تحلیل آماری قابل محاسبه است.
در این شیوه نمونهگیری برای مثال، انتخاب ۱۰ نفر از یک جامعه، باعث میشود که به طور متوسط به اطلاعات ۵ مرد و ۵ زن دسترسی داشته باشیم. ولی اگر توزیع جامعه آماری از لحاظ نسبت زن و مرد نیز در انتخاب نمونه تصادفی دخیل باشد، بهتر میتوان نمونه را انتخاب کرد و به نتایج حاصل از تحقیق اعتماد بیشتری داشت.
نمونهگیری تصادفی ساده، ممکن است هنگام جمعآوری اطلاعات از یک جمعیت هدف غیرمعمول بسیار ناقص عمل کند. در برخی موارد، محققان علاقهمند هستند که بررسی خاصی را روی زیر گروهی از جامعه آماری انجام دهند. برای مثال، محقق ممکن است بخواهد به بررسی عامل نژاد در توانایی عملکرد شغلی افراد مختلف بپردازد. استفاده از نمونهگیری تصادفی ساده در این حالت نمیتواند نیازهای محقق را برای تعیین نمونه مناسب برآورده کند.
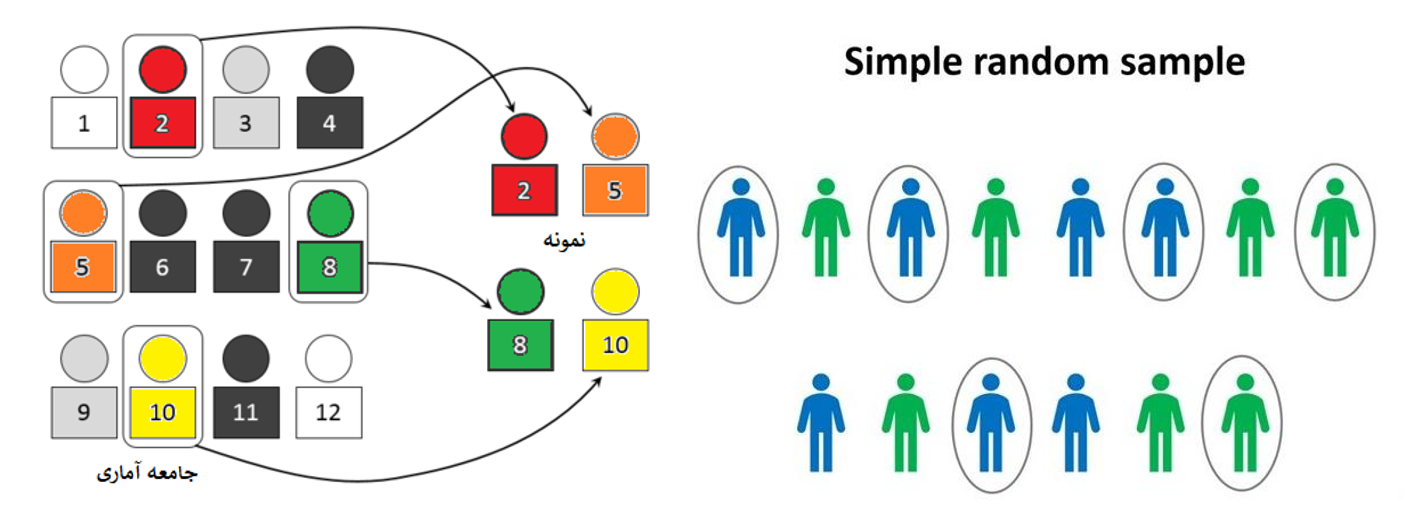
نمونه گیری سیستماتیک
برای انجام نمونهگیری سیستماتیک احتیاج به یک لیست مرتب شده از اعضای جامعه آماری داریم که دارای ستون ردیف است. ابتدا یک مقدار تصادفی کوچکتر از n انتخاب میشود. این مقدار نشان دهنده ردیفی است که اولین عضو نمونه در آن قرار دارد. سپس، شماره ردیف بعدی، توسط جمع شماره ردیف نمونه اول با مقدار فاصله محاسبه شده و عضو دوم نمونه بدست میآید. این کار تا رسیدن به تعداد نمونه مورد نظر ادامه پیدا میکند.
البته بعد از انتخاب عضوی از جامعه آماری در نمونه، شماره ردیف آن از لیست حذف شده و شماره ردیفها مجددا تولید میشوند. به همین علت اگر هنگام نمونهگیری به انتهای لیست برسیم، میتوان از ابتدای لیست دوباره کار نمونهگیری را ادامه داد. به این ترتیب این شیوه نمونهگیری میتواند بدون جایگذاری تلقی شود.
اگر تعداد کل نمونه های یک جامعه را 𝑁 در نظر بگیریم و بخواهیم به تعداد 𝑛 نمونه از آن انتخاب کنیم، در این طرح کافیست ابتدا شماره رکوردها را مرتب کنیم و در بازه شماره رکورد اول تا شماره رکورد 𝑘 – ام یک نمونه تصادفی انتخاب شود و سپس با گام های به فاصله 𝑘 تمامی رکوردهای دیگر نیز انتخاب گردند.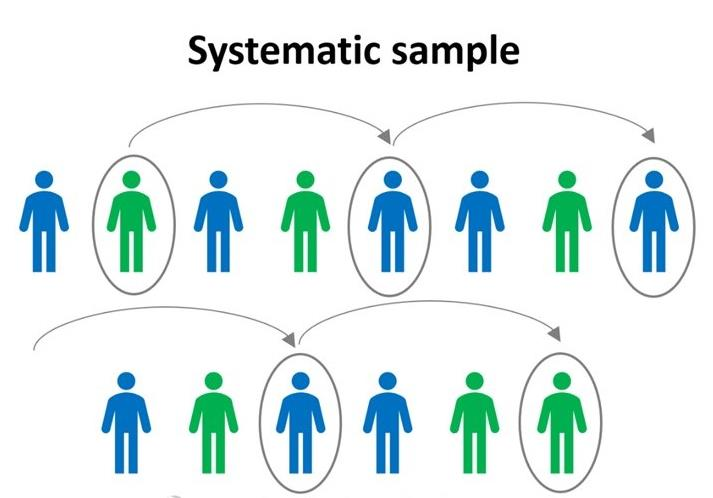
نمونه گیری طبقه ای
در حالتی که جامعه آماری دارای بخشهای مجزایی باشد، میتوان محدوده نمونهگیری را به بخشهای مختلف تقسیم کرد. در این حالت هر بخش از جامعه به عنوان یک زیرجامعه تلقی شده که نسبت به بقیه بخشها مستقل است. به این ترتیب با استفاده از نمونهگیری تصادفی از هر زیربخش به یک نمونه کامل خواهیم رسید. این روش را نمونهگیری طبقهای مینامند.
این شیوه نمونهگیری دارای مزایای زیادی است که به بعضی از آنها در زیر اشاره شده است:
- ایجاد بخشهای مجزا از جامعه آماری، امکان بررسی گروههایی از جامعه را به وجود میآورد که ممکن است در نمونهگیری تصادفی ساده در نظر گرفته نشوند.
- دقت محاسبات و برآوردهای حاصل از نمونه آماری را افزایش میدهد زیرا حجم نمونه از هر زیرگروه متناسب با حجم زیرجامعه مربوط به خودش است.
- استفاده از شیوه نمونهگیری طبقهای این امکان را میدهد که در هر زیربخش از جامعه آماری روش نمونهگیری خاصی به کار رود.بنابراین گاهی میتوان به جای استفاده از نمونهگیری تصادفی در زیربخشها از نمونهگیری خوشهای نیز استفاده کرد.
همچنین معیابی نیز برای این شیوه نمونهگیری میتوان برشمرد:
- انتخاب ویژگی که براساس آن بتوان جامعه آماری را گروهبندی کرد، کار مشکلی و حساسی است.
- برای جامعهای که به طور یکدست و همگن باشد، استفاده از چنین شیوهای ممکن است، نتایج حاصل از تحقیق و تحلیل آماری را به گمراهی بکشد.
- هزینه و زمان در اجرای نمونهگیری طبقهای نسبت به نمونهگیری تصادفی ساده نسبتا زیاد است.
البته تعیین بخشهای مجزا از جامعه آماری در نمونهگیری طبقهای، هزینه و زمان بیشتری نسبت به نمونهگیری تصادفی دارد. تعیین بخشهای جامعه آماری باید به شکلی باشد که شرطهای زیر برایش صدق کنند:
- پراکندگی در درون هر بخش کمینه باشد. به بیان دیگر حداکثر میزان شباهت را در هر بخش داشته باشیم.
- پراکندگی بین بخشها بیشینه باشد. به بیان دیگر میزان شباهت بین بخشهای جامعه آماری حداقل ممکن باشد.
- ویژگی که باعث ایجاد طبقات در جامعه آماری شده، بیشترین ارتباط یا وابستگی را با موضوع مورد تحقیق داشته باشد.
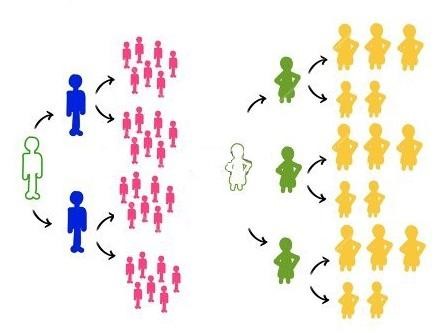
نمونه گیری خوشه ای
در نمونه گیری خوشه ای، مشابه قبل کل جامعه به چند گروه یا خوشه تقسیم می شود، با این تفاوت که می دانیم شاخص های مورد تحقیق در این گروه ها دارای توزیع مشابه می باشند. بنابراین در اجرای این طرح کافیست به صورت تصادفی چند خوشه انتخاب شده و نمونه های آن مورد تحلیل قرار گیرند.
به طور مثال برای بررسی میزان موفقیت دانش آموزان مدارس دولتی یک شهر، با انتخاب چند مدرسه، وضعیت تحصیلی دانش آموزان بررسی و تحلیل گردد.
گاهی برای نمونهگیری از جامعهای که اعضای آن در گروههایی مجزا قرار دارند، از روش نمونهگیری خوشهای استفاده میشود. این شیوه معمولا بر اساس بخشهای مجزایی که توسط نواحی جغرافیایی تعیین میشوند به کار میرود. برای مثال اگر میزان درآمد خانوار مورد بحث باشد، نمونهگیری میتواند به صورت انتخاب 1000 خانوار از شهرهای مختلف کشور صورت بگیرید. اگر از شیوه نمونهگیری تصادفی ساده استفاده کنیم باید از لیست خانوار که در مرکز آمار وجود دارد با استفاده از اعداد تصادفی یک نمونه به حجم ۱۰۰۰ انتخاب کنیم. این احتمال وجود دارد که بیشتر اعضای این نمونه به علت تراکم خانوار در استان تهران، محدود به این استان شوند و سهم استانهای دیگر در برآورد مجموع درآمد خانوار کاهش یابد.
در نتیجه بهتر است برای بالا بردن دقت برآورد از شیوه نمونهگیری خوشهای استفاده شود. برای چنین حالتی از بین استانهای کشور به طور تصادف ۱۰ استان انتخاب میشود، از بین هر استان نیز ۱۰ شهر به طور تصادفی انتخاب شده و از هر شهر نیز ۱۰ خانه باز هم به طور تصادفی انتخاب میشود. در نتیجه یک نمونه ۱۰۰۰ تایی از خانوارها داریم که میتوانیم پرسشنامه مربوط به درآمد را برایشان تکمیل کنیم.
این شیوه نمونهگیری در کسب اطلاعات کامل و با اهمیت از جامعه آماری با حفظ تغییر پذیری زیاد در اعضای نمونه کمک شایانی میکند. گاهی به نمونهگیری خوشهای، روش «نمونهگیری چند سطحی» (Multistage Sampling) نیز گفته میشود. گامهای این روش نمونهگیری به صورت زیر است:
- گام اول: تعیین خوشهها برای تهیه نمونهها
- گام دوم: انتخاب یک نمونه تصادفی از خوشههای مرحله اول
- گام سوم: انتخاب یک نمونه تصادفی از خوشههای مرحله دوم
- ….
- گام نهایی: انتخاب یک نمونه تصادفی از خوشههای مرحله قبلی
اگر در نمونهگیری خوشهای یا چند سطحی فقط گام یک و دو طی شود، روش نمونهگیری، «یک مرحلهای» (One Stage) است و با طی شدن گامهای ۱ تا ۳ به آن نمونهگیری دو مرحلهای (Two Stage) میگویند. در مثالی که در مورد نمونهگیری خوشهای درآمد خانوار گفته شد، روش نمونهگیری سه مرحلهای است.
روش نمونه گیری غیرتصادفی
در نمونهگیری تصادفی، یا نمونهگیری برمبنای احتمال، هر عضو از جامعه آماری احتمال دارد که در نمونه آماری قرار گیرد و مشخصا این احتمال مثبت است. در مقابل در روشهای نمونهگیری غیرتصادفی، این شرط وجود ندارد و ممکن است عضو یا اعضایی از جامعه آماری اصلا قابلیت قرارگیری در نمونه را نداشته باشند. شرط انتخاب اعضای نمونه آماری ممکن است براساس نظر شخصی یا قضاوت محقق صورت گیرد که در راستای هدف بررسی آماری است.
معمولا بررسیها و استنباطهایی که روی نمونه حاصل از روش نمونهگیری غیر تصادفی به دست آمده است، قابلیت انتقال به جامعه آماری را ندارد. به همین دلیل نتایجی که از طریق روش های نمونه گیری غیرتصادفی بدست میآید ممکن است با نتایج حاصل از نمونهگیری تصادفی متفاوت باشد.
بنابراین روش نمونهگیری غیرتصادفی در زمینههایی به کار گرفته میشود که محقق سعی در ایجاد یک نظریه برای بخشی از جامعه آماری دارد و فقط با تکرار عمل نمونهگیری غیرتصادفی میتوان به نظریهای برمبنای نتایج علمی حاصله دست یافت.
روش های نمونه گیری غیرتصادفی معمولا به منظور تایید تئوریهایی که از قبل وجود دارند بخصوص برای تحلیل دادههای کیفی به کار گرفته میشود تا محقق بتواند به توصیف یک پدیده در بخشی از جامعه آماری بپردازد. یکی از جنبههای موثر در به کارگیری روشهای نمونهگیری غیرتصادفی، هزینه کمتر و زمان کوتاهتر برای حصول به نمونه مورد نظر در مقابل با روشهای نمونهگیری تصادفی است.
در این میان میتوان به روشهای نمونهگیری غیرتصادفی مانند روش نمونهگیری گلوله برفی (Snowball Sampling)، نمونهگیری اتفاقی (Accidental Sampling)، نمونهگیری متوالی (Consecutive Sampling) و نمونهگیری قضاوتی (Judgmental Sampling) اشاره کرد.
نمونه گیری گلوله برفی
در این روش اولین عضو نمونه، به طریقی انتخاب میشود که بیشترین ارتباط را با موضوع مورد تحقیق دارد. از طریق ارتباط این عضو با اعضای دیگر جامعه آماری، امکان دسترسی به سایر نمونهها میسر میشود. به این ترتیب اعضای نمونه حاصل شده، مانند یک شبکه اجتماعی به یکدیگر پیوند داشته و میتوانند بیشترین اطلاعات را در مورد موضوع تحقیق و شناخت پدیده مورد نظر در اختیار محقق قرار دهند. در این حالت نمونه حاصل دارای اریبی خواهد بود و اعضایی از جامعه که در یک گروه خاص هستند شانس بیشتری برای عضویت در نمونه را دارند.
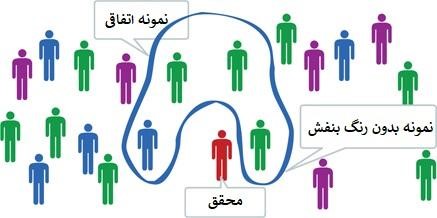
نمونه گیری اتفاقی
اعضای جامعه آماری با توجه به قابل دسترس بودن در نمونه جای میگیرند. برای مثال نمونه میتواند از دوستان، همکاران و یا فروشندگان یک مرکز خرید تشکیل شود. در این روش باز هم نمونه حاصل دارای اریبی است زیرا نتایج حاصل از تحقیق به گروه خاصی از جامعه آماری وابسته است .
نمونه گیری قضاوتی
در این روش، محقق براساس نظر و پیشینهای که در مورد اعضای جامعه آماری دارد، دست به نمونهگیری میزند. انتخاب یا عدم انتخاب عضوی از جامعه در نمونه بسته به نظر محقق و تجربیات او دارد. معمولا این روش در جوامع آماری محدود و با حجم کم به کار میرود زیرا محقق باید در مورد تک تک اعضا اطلاعات قبلی داشته باشد تا بتواند نمونه حاصل را بهتر انتخاب کند.
