مثال شماره 1
فرض کنید داده های خرید مشتریان شرکت x را داریم و به دنبال الگوهای خرید آنها هستیم. فرض کنید که تمام نقاط خاکستری رنگ موجود در تصویر زیر مشتریان این شرکت هستند که در نگاه اول هیچ تمایزی بین آنها وجود ندارد.

همچنین ما یک جدول داریم که برای هر مشتری یک کد دارد و تاریخ خرید، نوع محصول و قیمت محصولات خریداری شده در آن جدول نوشته شده است.
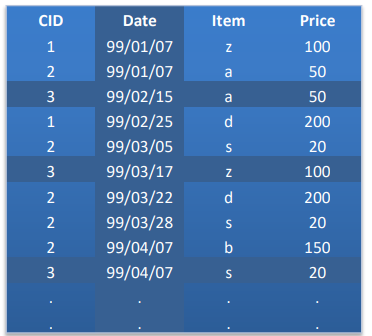
می خواهیم ببینیم که با این میزان حداقلی از داده ها چطور می توان یک مسئله را حل کرد که به عنوان تحلیل الگوهای رفتاری مشتریان شناخته می شود. در قدم اول آن جدول را مرتب کنیم و برای هر مشتری فقط یک سطر اختصاص می دهیم که در همان یک سطر مجموعه خرید ها و تاریخ آخرین خرید باشد.
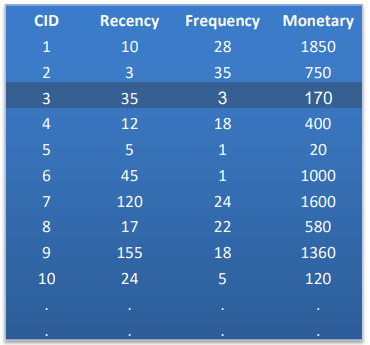
حالا با استفاده از این جدولی که برای هر مشتری ۳ نوع داده را به ما نشان می دهد، می توانیم یک نمودار سه بعدی ترسیم کنیم و می بینیم که مشتریان ما در ۳ گروه تقسیم بندی می شوند.
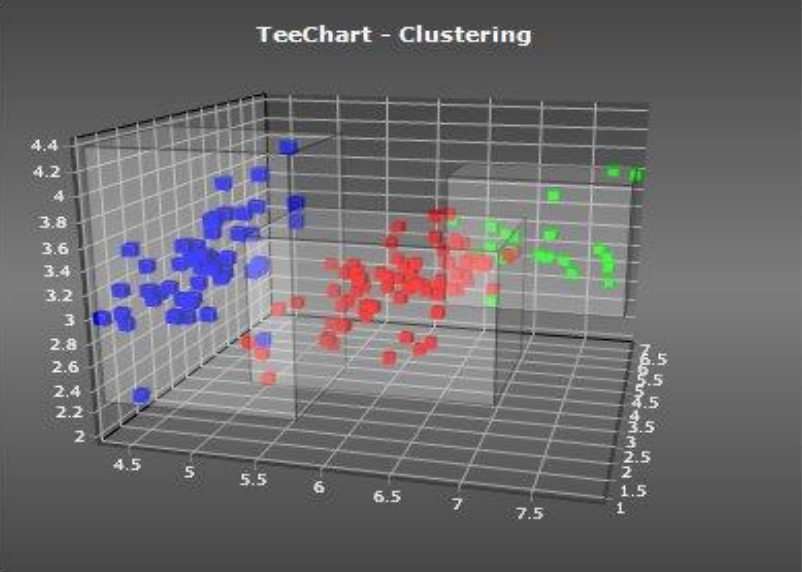
در دیدگاه اول و قبل از مرتب کردن داده های جدول ما نمیتوانستیم چنین دسته بندی از مشتری ها را داشته باشیم اما با یک شاخه سازی درست و بصری کردن آن توانستیم سه الگو را شناسایی کنیم. از قبل ما نمی دانستیم که سه گروه وجود دارد، شاید ۵ یا ۷ یا کمتر یا بیشتر تعداد گروه ها وجود داشت. یعنی ما با بصری سازی و الگو سازی و مرتب سازی داده ها توانستیم به یک الگوی منظم برسیم که می توانیم از آن استفاده کنیم.
البته همیشه با بصری سازی نمی توانیم مشکل را حل کنیم اگر که تعداد ابعاد آن بیشتر از سه بعد شود نمی توانیم به درستی آن را ترسیم کنیم. در این مواقع الگوریتم های آمار و یادگیری ماشین به کمک ما می آیند و مرزبندی بین داده ها را مشخص می کند که در حالت عادی ما قادر به تشخیص آنها نیستیم.
حالا دیگر آن نقاط خاکستری صرفاً یک سری نقطه خاکستری نامفهوم نیستند بلکه ما برای هر کدام از مشتری ها یک الگو داریم و الگویی از رفتار مشتریان داریم که می توانیم بدانیم مشتریانی که در الگوی عددی ۳ هستند با مشتریانی که در الگوی عددی ۲ هستند رفتارهای متفاوتی دارند و الگوهای رفتاری آنها برای ما ما قابل درک است.

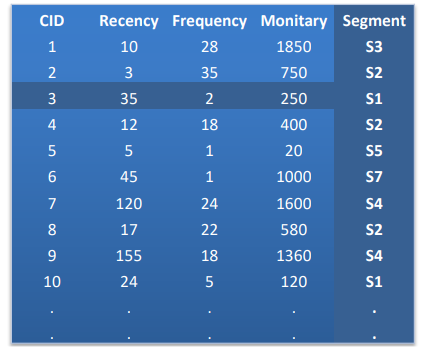
حالا با استفاده از خروجی که به دست آمده به عنوان مثال یک سوال این است که مشتریانی که مثلا الگوی عددی ۹ را دارند در کجا ساکن هستند؟ در چه منطقه جغرافیایی قرار دارند؟ در چه بازه های زمانی میزان خرید بیشتری دارند؟ یا خرید کمتری دارند؟
برای تفکیک و جداسازی مشتریان الگوی عددی نهم، اگر به صورت دستی اتفاق بیفتد بسیار زمان بر و البته با دقت بسیار پایین انجام می شود اما اگر از ابزارهای مناسب آن استفاده کنیم و به عنوان مثال رنگ الگوی عددی ۹ را رنگ متفاوتی مانند قرمز انتخاب کنیم، تمامی الگوهای عددی ۹ در تصویر به ما نمایش داده می شوند و واضح و قابل تفکیک خواهند بود.

این کار توسط یکسری ابزارهای تخصصی مانند داشبوردها و گزارش های مدیریتی انجام میشود و بخشی از پروژه های دیتا ساینسی در نهایت توسط دیتا آنالیزیست ها در این لایه طراحی می شوند و برای جمع آوری و پاسخگویی به سوالاتی که کسب و کار نیاز دارد که به آن پاسخ داده شود، طراحی می شوند و با یک قصه گویی مناسب بیان میشوند تا ارزش افزوده لازم را ایجاد کند.
اگر پروژه ای در این مرحله ضعیف عمل کند ممکن است تمامی دستاوردهایی که تا این مرحله به دست آورده است، عملا هیچ دستاوردی برای سازمان نداشته باشد! در واقع رسیدن به یک الگو انتهای کار نیست بلکه گروه های دیگر در یک تیم دیتا ساینتیست نیاز است تا بتوان آن چرخه را بهخوبی تکمیل کنند و به نتیجه مورد نظر برسند.

مثال شماره ۲
چگونه می توان الگوی اعتباری مشتریان را شناسایی کرد؟
در جدول زیر فرض کنیم که این داده ها مربوط به مشتریان یک بانک است که تسهیلاتی را دریافت کردند. ستون اول از سمت چپ کد مربوط به هر مشتری است. برای هر مشتری در هنگام اعطای تسهیلات اطلاعاتی از آن مشتری ثبت شده است: میزان درآمد، نوع ماشین و جنسیت. در آخر خوش حساب یا بد حساب بودن مشتری برای بازگرداندن آن تسهیلات نیز قید شده است.
حالا میخواهیم ببینیم که آیا میتوان بر مبنای اطلاعات هیستوریکالی که از آن مشتریان داریم و خوش حساب یابد حساب بودن مشتریان، ارتباط و الگویی را بین آنها شناسایی کرد؟ یعنی بتوانیم برای مشتریان جدید این بانک حدس بزنیم که آن مشتری خوش حساب خواهد بود یا بد حساب؟ و سپس بر مبنای آن حدس بتوانم مدیریت ریسک داشته باشم و تصمیم بگیرم که آیا آن مشتری تسهیلات بدهم یا ندهم؟ اگر تسهیلات میدهیم ضمانت های سختگیرانه تری داشته باشد یا نداشته باشم؟
از آنجایی که دیتا های موجود در این جدول حجم کمی دارند می توان آنها را به صورت چشمی بررسی کرد و به این نتایج اولیه رسید.
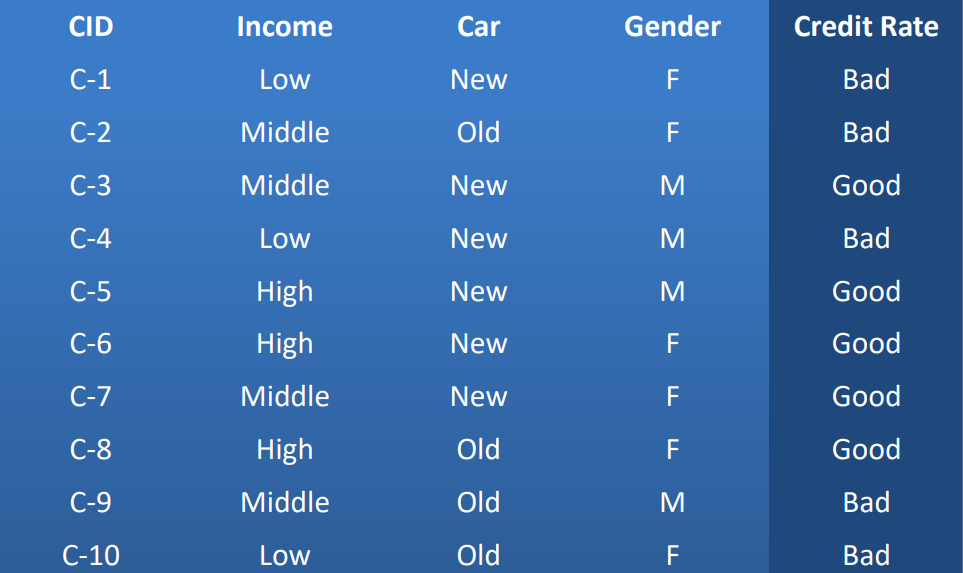
به عنوان مثال مشتری ۵و ۶ و ۸ مشتریانی هستند که درآمد بالایی دارند و خوش حساب بودند بنابراین من به یک الگو میرسم که اگر مشتری درآمد بالایی داشته باشد فارغ از نوع خودرو که قدیم یا جدید باشد و فارغ از جنسیت مشتری خوش حسابی است. و میتوان با خیال راحت به این افراد تسهیلات را ارائه کرد.

If Income=Hight Then Credit Rate=Good
اما مشتریان شماره ۱ و۴ و ۱۰ این مشتریان فارغ از قدیم یا جدید بودن خودرو و فارغ از جنسیت مشتریان بد حسابی هستند بنابراین قانون دوم نوشته میشود: اگر یک مشتری درآمد سطح پایین داشت بنابراین یک مشتری بد حساب است و سیاستهای سختگیرانه تری برای ارائه تسهیلات به این افراد در نظر گرفته خواهد شد.

If Income=Low Then Credit Rate=Bad
چهار مشتری باقی مانده یعنی مشتریان شماره ۲ و ۳ و ۷ و ۹ افرادی هستند که سطح درآمدی متوسطی دارند که ۵۰ درصد آنها خوش حساب و ۵۰ درصد مابقی بدحساب هستند بنابراین نیازمند اطلاعات اضافه تری هستم تا بتوانم الگوی دقیق تر را تشخیص دهم.
با کمی دقت می بینیم که مشتریان با درآمد متوسط که خودروهای مدل جدید دارند مشتریان خوش حساب هستند و برعکس. بنابراین قانون شماره ۳ نوشته میشود: مشتریانی که درآمد متوسط و خودروی مدل جدید داشته باشند مشتریان خوش حسابی هستند یعنی دو فاکتور در کنار هم لازم است که در نظر گرفته شود.

If Income=Middle & Car=New Then Credit Rate=Good
مشتریان شماره ۲ و ۹ سطح درآمدی متوسطی داشتند و خودروهای مدل قدیمی داشتند مشتریان بدحسابی بودند بنابراین قانون شماره ۴ به این گونه نوشته می شود: اگر سطح درآمدی متوسط و نوع خودرو قدیمی باشد آنگاه مشتری بد حساب خواهد بود یعنی اینجا هم دو فاکتور در کنار هم لازم است که در نظر گرفته شوند.

If Income = Middle & Car = Old Then Credit Rate = Bad
یعنی حاصل این جدول و این داده ها در ۴ قانون اگر-آنگاه خلاصه میشود. بنابراین مشتریان جدیدی که وارد می شوند اطلاعات آنها را دریافت می کنم و با توجه به این چهار قانون می توانم پیشبینی کنم که آن مشتری خوش حساب است یا بد حساب و ارائه تسهیلات به آن مشتری جدید چگونه باشد و ریسک ارائه تسهیلات را به حداقل برسانم.

در این مثال به دلیل اینکه تعداد دیتاها کم بود ما توانستیم آنها را به صورت چشمی بررسی کنیم در صورتی که تعداد داده ها بسیار زیاد باشد به الگوهای بسیار پیچیده تری لازم داریم و یا به جای 3 خصوصیت لازم باشد که تعداد خصوصیت های بسیار بیشتری را مورد بررسی قرار دهیم.
تفاوت این الگو با الگویی مثل قبل این است که در مثال قبل مشتریان دسته بندی نشده بودند و همه طبقه بندی ها و دسته بندی ها توسط الگوریتم ها انجام شده بود اما اینجا ما یکسری طبقه بندی های از پیش تعیین شده داریم. و مشخص کردیم که ما به دنبال الگوهای خوش حسابی و بدحسابی هستیم و الگوریتم باید به گونه ای نوشته شود که نتیجه آن خوش حسابی یا بد حسابی مشتریان باشد و نوع الگوریتم ها به صورت هدفمند از پیش تعیین شده است.
چالش های شناسایی الگوها
- انتخاب داده های مناسب
- ساخت شاخص های مناسب
- انجام تبدیلات مناسب
- انتخاب الگوریتم مناسب
- انتخاب طرح ارزیابی مناسب
- انتخاب الگوی مناسب و…
مجموعه پاسخ به این سوالات تحت عنوان داده کاوی (Data Mining) شناخته می شود. بنابراین دادهکاوی صرفاً ویترین مدل یا ویترین الگوریتم نیست. شبکه عصبی یا درخت تصمیم داده کاوی محسوب نمی شوند بلکه تمام این فرایند حل مسئله در مجموع به عنوان بندی داده کاوی شناخته می شود که بخشی از آن الگوریتم ها و اجرا و ارزیابی آنها است.
تعریف داده کاوی (از دید اسامه فیاض- ۱۹۹۶)
فرایند کشف دانش از پایگاههای داده به منظور شناسایی الگوهای موجود در دادههای که شرایط زیر را داشته باشند:
- معتبر باشند
- کارا و قابل استفاده باشند
- بدیع باشند
- توجیه پذیر باشند
راجع به این تعریف توضیح بیشتری می دهیم:
وقتی می گوییم که از پایگاه های داده استفاده می کنیم یعنی اینکه دیتا های ما به صورت هیستوریکال هستند. به طور کلی در فرایند داده کاوی و دیتاساینس ما عمدتا با دیتاهای هیستوریکال کار میکنیم یعنی روی رویدادهای گذشته کار می کنیم، مربوط به زمان حال حاضر نیست و با این فرض کار را پیش می بریم که الگوهایی در گذشته وجود دارند که تکرار پذیر هستند و ما آن الگوها را شناسایی کردیم و در آینده برای پیش بینی و کنترل تغییرات از آنها استفاده میکنیم.
اگر در جایی به هر دلیلی ارتباط بین داده ها و الگوهای گذشته با تکنولوژی امروزه کاملاً قطع شود و این فرض نقض شود، آنگاه عملاً این راهکار نمی تواند مفید باشد و ما نمی توانیم از داده های گذشته برای پیش بینی آینده استفاده کنیم که هیچ راه ارتباطی با یکدیگر ندارند.
پایگاه های داده معمولاً حجم بسیار زیادی از دیتاها را دارند زیرا از گذشته تاکنون حجم بسیار زیادی دیتاها روی همدیگر انباشته می شود. در ۲ مثال قبل دیدیم که در داده های با حجم کم ما به سادگی می توانیم الگوها را شناسایی کنیم. اما زمانی که حجم داده ها بسیار زیاد شود تشخیص و شناسایی الگو ها به صورت چشمی و دستی امکان پذیر نیست و نیاز به ابزارهای پیشرفته تر و الگوریتم ها داریم.
در این تعریف آمده است که دیتاها باید معتبر باشند؛ یعنی اینکه اعتبارسنجی شده باشند. بنابراین ما به عنوان یک دیتا ساینتیست قبل از ساخت مدل ها باید به اعتبار سنجی فکر کنیم و بدانیم که از چه طرحی می خواهیم برای اعتبار سنجی دیتاها استفاده کنیم که مناسب آنها باشد. یکی از طرح های رایج نسبت ۷۰ به ۳۰ است یعنی ۷۰ درصد داده های هیستوریکال را برای ساخت مدل استفاده می کنیم و ۳۰ درصد داده های گذشته کار را برای تست و ارزیابی مدل ها استفاده می کنیم.
کارا و قابل استفاده باشد؛ یعنی مدل ما باید در نهایت برای آن مسئله ای که تعریف شده قابل استفاده باشد و کارکرد داشته باشد.
بدیع باشند؛ طبیعتاً زمانی که ما توسط الگوریتم ها و ماشین، الگو ها را شناسایی می کنیم بسیار محتمل است که الگوها بدیهی باشند که نیاز به این همه محاسبات، الگوریتم ها و کامپیوتر را نداشتند و خود افراد هم می توانستند بدانند که چنین اتفاقی خواهد افتاد. بنابراین این ها ارزش ارائه ندارند.
اما از طرفی این ها می توانند ارزشمند باشند و یک نوع ارزیابی کیفی است زیرا زمانی که الگوریتم توانسته است به صورت خودکار این بخش از الگوها را شناسایی کند بنابراین آن بخش از الگوها را که بدیهی نیستند را هم احتمالاً می تواند شناسایی کند و این نکته مهمی است. البته که بدیهی بودن به این معنا نیست که دنبال چیزهای عجیب و غریب باشیم تاکنون کسی آنها را نشنیده و ندیده بلکه گاهی می تواند به این معنا باشد که مرزهای یکسری الگوها را دقیق کنیم.
توجیه پذیر باشد؛ به این معنا که نتایج و الگوهایی که به دست می آید نباید با آن تجربیات کلی و دانش کلی که از قبل داریم تفاوت خیلی آشکار داشته باشد و یا آنها را نقض کند و با آن دانش ضمنی خود بتوانیم آنها را توجیه کنیم. البته در مواردی که همه گزینه های دیگر لحاظ شده باشد و الگوهای بسیار منظم تکرار شونده را شناسایی کنیم اما توجیه پذیر نباشند از آن الگو استفاده می کنیم و امیدوار هستیم که در آینده بتوانیم توجیه پذیر بودن آن را ثابت کنیم و یا توجیه آن را پیدا کنیم.

تعریف دادهکاوی
داده کاوی یک محصول نیست. داده کاوی یک نرم افزار نیست. داده کاوی یک الگوریتم نیست. داده کاوی فرایند حل مسئله است.
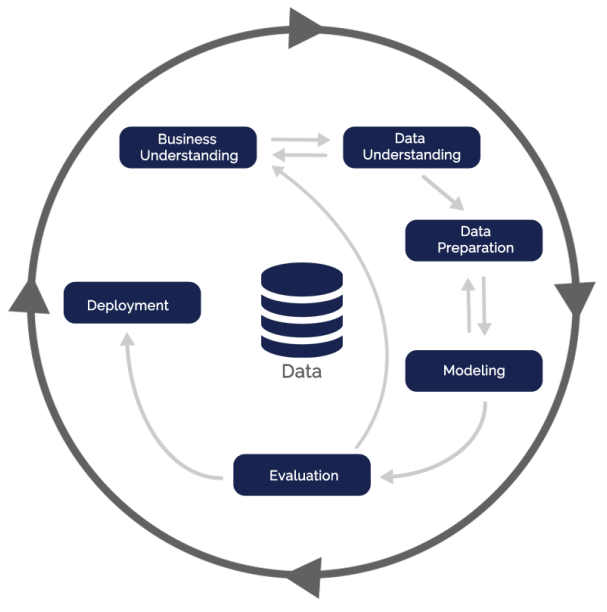
فازهای فرایند داده کاوی:
- شناسایی و درک مسئله
- شناسایی و درک داده ها
- آماده سازی داده ها
- مدل سازی
- ارزیابی
- گسترش و توسعه