
برای اینکه یک دانشمند داده باشید، لازم است مهارتهای مختلفی را فرابگیرید. ما در این مقاله (کلیک کنید) این مهارتها را به تفصیل معرفی کردیم و شما میتوانید از راههای مختلفی این مهارتها را کسب کنید. تیم دایکه یک مسیر برای یادگیری دانشمند داده طراحی کرده است که تمامی این مهارتها را نیز در بر میگیرد.
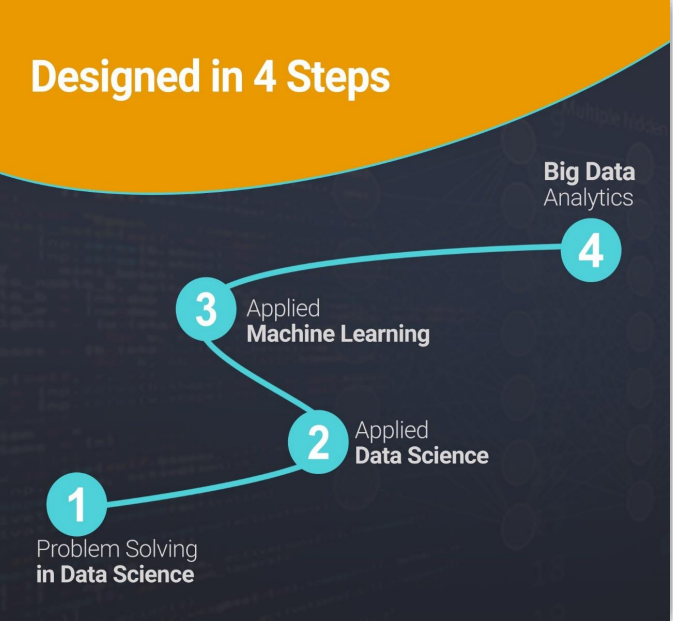
این مسیر در 4 گام اصلی طراحی شده:
- حل مسئله در علم داده
- علم داده کاربردی
- یادگیری ماشین کاربردی
- تحلیل کلان داده ها
اهداف گام اول:
در این گام ابتدا به ادبیات یکسانی در علم داده میرسیم و مفاهیم را یاد می گیریم. متدولوژی حل مسئله را می آموزیم تا زمانی که با یک مسئله واقعی مواجه شدیم بدانیم که چطور با آن برخورد کنیم و چه مسیر و نقشه ای را لازم است طی کنیم تا به جواب برسیم.
آمار و احتمال را به اندازه ای که یک دیتاسینتیست نیاز دارد یعنی در حد خوبی یاد می گیریم؛ ابتدا مفاهیم آمار و سپس به طور عملی در دادهها از آن استفاده میکنیم. با الگوریتم های ماشین لرنینگ و همچنین فرآیند آماده سازی داده ها آشنایی پیدا می کنیم. در این مرحله هدف ما تخصص در ریاضیات این مباحث نیست بلکه قصد داریم دید شهودی مناسبی پیدا کنیم و بدانیم که از این مباحث چگونه و به چه طریقی در کجا استفاده کنیم و با چالش ها و راهکارها در دنیای واقعی آشنا شویم.
علاوه بر این مفاهیم، در این گام با ابزارهایی به اسم IBM SPSS Statistics و IBM SPSS Modeler آشنا می شویم و با آنها کار کنیم. تمام مباحثی که در این گام پوشش داده می شود مباحث پایه ای و کلیدی حل مسئله در دیتا ساینس است و ابزار ممکن است در آینده عوض بشود و مثلا با پایتون کار کرد. اینجا تمرکز اصلی نه روی ابزار، بلکه روی روش حل مسئله است. این گام حدود 2 الی 2ماه و نیم طول می کشد.

اهداف گام دوم:
در این گام از مسیر، یکسری مهارت ها اضافه میشوند؛ کار با پایگاه داده ها از جمله SQL و No-SQLها را یاد می گیریم. با APIها آشنا می شویم و می آموزیم که چگونه از دیتا سورسها اطلاعات مورد نیاز را واکشی کنیم. یاد میگیریم که روش های حل مسئله ای که آموختیم را به زبان پایتون دربیاوریم و از آنها استفاده کنیم. افرادی که تا انتهای این مسیر به درستی با برنامه پیش بروند، انتظار میرود که بتوانند به عنوان یک فرد جونیور وارد تیم های حل مسئله و تیم های دیتاساینتیستی بشود و پروه حل کند زیرا با ابزارهای اصلی آشنایی کافی پیدا کرده است.

اهداف گام سوم:
در این گام مباحثی که آموخته ایم عمیق تر میشوند، تاکید بر این است که دانش تخصصی تری نسبت به الگوریتم ها پیدا کنیم به همین دلیل شروع این گام با یادگیری مباحث ریاضیاتی، جبر خطی و بهینه سازی است. الگوریتم ها را به صورت ریاضیاتیتر می آموزیم تا بتوانیم الگوریتم ها را خودمان بنویسیم و یا الگوریتم های موجود را با توجه به نیاز خودمان بتوانیم تغییر بدهیم، پرفورمنس الگوریتم ها را تغییر دهیم یا با الگوریتم های نوینی که در حوزه یادگیری عمیق توسعه داده شده است کار کنیم.
لازم است بتوانیم از الگوریتم ها روی داده های غیرساختیافته استفاده کنیم یا روی تصاویر و متن ها استفاده کنیم. همانطور که از اسم Data Science مشخص است ما نمی توانیم بخش Science را حذف کنیم و فقط روی پکیج های آماده کار کنیم و خودمان را به آنها محدود کنیم. ما زمانی یک Data Scientist خوب هستیم که دانش پشت الگوریتم ها را بدانیم و در صورت نیاز چیدمان پشت صحنه آنها را انجام دهیم تا پرفورمنس لازم را به دست آوریم.

اهداف گام چهارم:
در این گام با مفاهیم لازم و کاربردی در پروژه های بزرگ آشنایی پیدا می کنیم. با اکوسیستم Big Data آشنایی پیدا می کنیم، اینکه چه زمانی و چرا وارد این اکوسیستم میشویم و مجبور میشویم روی زیرساخت های بیگ دیتا تحلیل داده را انجام بدهیم؟ چگونه مدل ها و الگوریتم هایی را که قبلا در یک سیستم اجرا میکردیم حالا به صورت توزیع شده در بستر بیگ دیتا ببریم؟ چه ابزارهایی برای این کار به ما کمک می کنند؟
وقتی حجم دیتاها زیاد میشود یا جریان دیتایی داریم که سرعت زیادی دارد، اصطلاحا یک استریم داریم، چگونه آنها را مدیریت و مدلسازی کنیم؟ هرچند که این کار اصلی مهندس داده است اما ما به عنوان دیتاساینتیست باید با این فرایند آشنا باشیم.
برای مشارکت در پروژه های بزرگ نیاز داریم که حتما کار با لینوکس را بلد باشیم زیرا بسیاری از ابزارهایی که در اکوسیستم بیگ دیتا است در بستر لینوکس قرار دارد و ما مجبوریم که با آن کار کنیم. همچنین با داکر باید آشنایی داشته باشیم و ندانستن هرکدام از این ها به موقعیت های شغلی احتمالی ما ضربه میزند.

مدرس: محمد روزبه (مدیرعامل گروه دایکه)
مستندساز: ساره واحدی
برگرفته از محتوای آموزشی پانزدهمین دوره علم داده دایکه