
 این بخش ادامهی مثال مطالعهی موردی تحلیلهای بازاریابی است که در چند مقالهی قبلی مطرح کردیم. بخشهای قبلی سری مقالات تحلیل بازاریابیِ خردهفروشی دایکه (بخش ۱ ، بخش۲ و بخش۳) را میتوانید در لینکهای زیر بیابید. در بخش ۳، تحلیل کاوشگرانهی دادهها (EDA) را مطرح کردیم. در مقالهی حاضر، راجع به تحلیل وابستگی، که روش مفیدی برای استخراج الگوهای جالب در دادههای مبادلاتی مشتریان است صحبت خواهیم کرد.
این بخش ادامهی مثال مطالعهی موردی تحلیلهای بازاریابی است که در چند مقالهی قبلی مطرح کردیم. بخشهای قبلی سری مقالات تحلیل بازاریابیِ خردهفروشی دایکه (بخش ۱ ، بخش۲ و بخش۳) را میتوانید در لینکهای زیر بیابید. در بخش ۳، تحلیل کاوشگرانهی دادهها (EDA) را مطرح کردیم. در مقالهی حاضر، راجع به تحلیل وابستگی، که روش مفیدی برای استخراج الگوهای جالب در دادههای مبادلاتی مشتریان است صحبت خواهیم کرد.
از تحلیل وابستگی میتوان بهعنوان ابزار مفیدی برای تحلیل تعمیم یافتهی کاوشگرانهی دادهها استفاده کرد. ضمناً، تحلیل وابستگی، هستهی تحلیل سبد بازار[1] یا تحلیل دنبالهای[2] است. بعداً در همین مقاله، از تحلیل وابستگی در مثال مطالعهی موردیمان استفاده میکنیم تا کاتالوگهای پیشنهادی کارامدی برای کمپینها و همچنین طراحی فروشگاه آنلاین (وبسایت) طراحی کنیم.
دستقیچیها[3]
۹ یا ۱۰ سالم بود که اولین کلاس درس کاردستی در مدرسهمان برگزار شد. کلاسهای درسی کاردستی در هند SUPW نامیده میشوند که مخفف «کار اجتماعی مفید و ثمربخش[4]» است. در جلسهی اول کلاس، به هر دانشآموز یک برگهی رنگی A4 و یک جفت قیچی داده میشد. در جلسهی اول، کودکان پرشوروهیجانِ بیهدف دریافتند که قادرند برگه کاغذی را بهروشهای تقریباً نامحدودی ببُرند. این کار از لحاظ اجتماعی نه سودمند بود، نه ثمربخش و به تولید مقدار زیادی کاغذ باطله منجر شد. عبارت SUPW در این مورد، «مقداری کاغذ مفید هدررفته[5]» است. بعدها، بهواسطهی تلاشهای هدفمندتر دریافتیم که اگر از قیچی هوشمندانه استفاده شود، شکلهای جالب زیادی از یک برگه کاغذ درمیآید.
این دقیقاً همان تجربهای است که بسیاری از تحلیلگران هنگام مواجه با دادههای مبادلاتی مشتریان کسب میکنند. منبع غنیای از اطلاعات راجع به رفتار مشتری در این دادهها نهفته است، اما سردرآوردن از اینکه کار را از کجا شروع کنیم دشوار است. دادههای مبادلاتی را میتوان بهروشهای بیشماری، مثل خردکردن تکهای کاغذ توسط قیچی، خرد، تکهتکه و گروهبندی کرد. کلید هر دو مورد بالا مسیر درست است.
تصویر هالیوود از تحلیل دادهها
 اجازه دهید یک تصویر معمولی هالیوود از تحلیل دادهها را برایتان توصیف کنم؛ مردی در برابر صفحهی نمایش بزرگی ایستاده است و دادهها (دنبالهای از اعداد) در کل صفحه شناورند. این مرد الگوهایی موجود در دادههای شناور را شناسایی میکند. این تصویری پرقدرت، اما کاملاً غیرواقعی است. روش خیرهشدن به دادهها و امید به یافتن الگوها بیشک فقط نویز تولید میکند و سیگنال ناچیزی بهدست ما میدهد. حتی کدشکنهای بزرگی مثل جان نَش[6] و اَلن تورینگ[7] هم اگر بکوشند با استفاده از روش هالیوود الگوهای موجود در دادهها را بیابند، شکست میخورند.
اجازه دهید یک تصویر معمولی هالیوود از تحلیل دادهها را برایتان توصیف کنم؛ مردی در برابر صفحهی نمایش بزرگی ایستاده است و دادهها (دنبالهای از اعداد) در کل صفحه شناورند. این مرد الگوهایی موجود در دادههای شناور را شناسایی میکند. این تصویری پرقدرت، اما کاملاً غیرواقعی است. روش خیرهشدن به دادهها و امید به یافتن الگوها بیشک فقط نویز تولید میکند و سیگنال ناچیزی بهدست ما میدهد. حتی کدشکنهای بزرگی مثل جان نَش[6] و اَلن تورینگ[7] هم اگر بکوشند با استفاده از روش هالیوود الگوهای موجود در دادهها را بیابند، شکست میخورند.
درواقع، منظورم این است که تحلیل دادهها، فعالیتی شدیداً برنامهریزیشده است. بهعنوان تحلیلگر، هیچگاه پیش از داشتن برنامهی مناسب و آمادهای از اقدامات (فرضیهها و غیره)، به دادهها دست نزنید. با این اوصاف، همیشه مواقعی هست که بهعنوان تحلیلگر مجبور خواهید شد برای یافتن الگوها، به قلمروهای ناشناختهای از دادهها وارد شوید. در چنین مواردی، توصیه میکنم به الگوریتمهای یادگیری ماشین متکی باشید یا الگوریتمهای تعدیلیافتهی خودتان را که مختص نیازهایتان هستند خلق کنید. به نظرم، ماشینها در انجام این کار خیلی بهتر از ما انسانها عمل میکنند. تحلیل وابستگی قدرتیافته توسط الگوریتم آپریوری[8] یکی از چندین روشها برای استخراج دادههای مبادلاتی است. اجازه دهید تحلیل وابستگی را در بخش بعدی بررسی کنیم.
تحلیل وابستگی
تحلیل وابستگی، همانطور که بهزودی کشف خواهید کرد، تحلیل فراوانی[9] مقدماتی اجراشده روی مجموعهدادهای بزرگ است. از آنجاییکه مجموعهدادههای بیشتر مسائل عَملی بزرگ هستند، پس برای اجرای تحلیل وابسنگی به الگوریتمهای هوشمندی مثل آپریوری نیاز دارید. اجازه دهید برای یادگیری تحلیل وابستگی، از مجموعه دادهی خیلی کوچکتری شروع کنیم. در جدول زیر، هر ردیف یا عدد مبادله معرف سبدهای بازار مشتریان است. در ستونهای بعدی کالاها، ۱ معرف «خرید کالا در آن مبادله» و ۰ معرف «عدم خرید» است.
|
مبادله # |
پیراهنها | شلوارها | کراواتها |
|
۰۰۱ |
۱ | ۱ |
۱ |
|
۰۰۲ |
۰ | ۱ |
۰ |
|
۰۰۳ |
۱ | ۰ |
۱ |
|
۰۰۴ |
۱ | ۰ |
۱ |
| ۰۰۵ | ۱ | ۱ |
۰ |
چندین متریک تحلیل وابستگی (یعنی پشتیبانی، اطمینان و ارتقاء) وجود دارد که در رمزگشایی اطلاعات نهفته در این نوع مجموعهداده بسیار مفیدند. بیایید این متریکها را بررسی کنیم و کاربرد آنها را بشناسیم. پشتیبانی برای خرید پیراهنها و کراواتها با هم در تحلیل وابستگی بهصورت زیر تعیین میشود:
برای دادههای ما، از کل ۵ مبادله، ۳ مبادله مربوط به پیراهنها و کراواتها است:
است: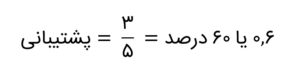
۶۰ درصد مقدار نسبتاً بالایی برای پشتیبانی است و بهندرت چنین مقادیر بالایی از پشتیبانی را در مثالهای شرایط واقعی رؤیت میکنید. برای مشکلات شرایط واقعی با چندین دسته کالا، پشتیبانی ۱ درصد یا گاهی حتی کمتر، بسته به ماهیت مشکلتان، نیز مفید خواهد بود. اطمینان وابستگی با استفاده از فرمول زیر محاسبه میشود:
در مجموعهدادهی ما، از ۴ مبادلهی پیراهنها، ۳ مبادله مربوط به پیراهنها و کراواتها است. محاسبهی اطمینان مجموعهدادهی ما بهصورت زیر است: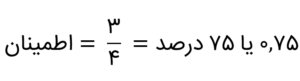
بار دیگر یادآوری میکنم که بهندرت چنین مقدار بالایی از اطمینان را برای بیشتر مشکلات واقعی خواهید یافت، مگر اینکه پیشنهادهای جذابی روی دو کالا داده شود. مقدار خوبی از اطمینان بهطور خاص به مشکل یافت می شود. سومین متریک مفید تحلیل وابستگی ارتقاء است که بهصورت زیر تعیین میشود:

اطمینان موردانتظار در فرمول بالا، موجودی کراواتها در مجموعهدادهی کل است؛ یعنی از ۵ خرید، ۴ مورد خرید کراوات است.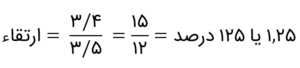
مقدار ۱۲۵ درصدی ارتقاء نشان میدهد زمانیکه مشتریان پیراهن میخرند، خرید کراوات بهبود مییابد. سؤالی که اینجا برایتان پیش میآید این است که اگر مشتری یک پیراهن بخرد، آیا احتمال خرید کراوات توسط این مشتری بالا میرود؛ یعنی مقدار ارتقاء بالاتر از ۱۰۰ درصد. بیایید از دانش تحلیل وابستگیمان در مثال مطالعهی موردیای که روی آن کار میکردیم استفاده کنیم.
مثال مطالعهی موردی خردهفروشی – تحلیل پیوستگی
شرکت درساسمارت، شرکتی که شما مدیر ارشد تحلیل و رئیس راهبرد کسبوکارش هستید، فروشگاه خردهفروشی آنلاین عرضهکنندهی پوشاک است. این شرکت کالاها، برندها و سبکهای مختلفی عرضه میکند. میدانید که تحلیل وابستگی زمانی بهترین کارکرد را دارد که روی گروههای مختلف مشتریان بهطور مجزا اجرا شود (راجع به گروهبندی مشتری[10] مطالعه کنید). هرچند، تصمیم گرفتهاید تحلیل وابستگی سریعی روی دادههای موجود در شرکتتان اجرا کنید.
 با دادههای مربوط به پیراهنهای رسمی و کراواتها که در مثال بالا بررسی کردیم، پشتیبانی ۰.۲ درصد، اطمینان ۱۲ درصد و ارتقاء ۵۰۹ درصد حاصل شد. این ارقام نشان میدهند که گرچه درصد رکوردهای پایینتری از مبادلات برای کراواتها و پیراهنها وجود دارد، اما بهمجرد اینکه مشتری پیراهنهای رسمی بخرد، احتمال خرید کراواتش تا پنج برابر افزایش مییابد.
با دادههای مربوط به پیراهنهای رسمی و کراواتها که در مثال بالا بررسی کردیم، پشتیبانی ۰.۲ درصد، اطمینان ۱۲ درصد و ارتقاء ۵۰۹ درصد حاصل شد. این ارقام نشان میدهند که گرچه درصد رکوردهای پایینتری از مبادلات برای کراواتها و پیراهنها وجود دارد، اما بهمجرد اینکه مشتری پیراهنهای رسمی بخرد، احتمال خرید کراواتش تا پنج برابر افزایش مییابد.
درساسمارت گزینهی بازگرداندن کالا را برای مشتریانش مهیا کرده است. کالاهای آسیبندیدهای که ظرف ۳۰ روز بازگردانده میشوند، هزینهی کاملشان به مشتری پس داده میشود. در ادامه، مشتریانی را بررسی کردید که علاوه بر پیراهن، کراوات هم میخرند و دریافتید که نرخهای بازگشت کالای کراوات برای آن مبادلات نیز ۳ برابر بیشتر از سایر نرخهای بازگشت است. این نشانگر آن است که مشتریان در انتخاب کراواتهای مناسب، هنگام سفارش آنلاین آنها بههمراه پیراهن مشکل دارند. نیازی به بهبودبخشیدن این فرایند روی وبسایت شرکت نیست. هدف کاهش نرخ بازگشت کالا، ضمن بهرهگیری کامل از فرصت مهیاشده برای فروش مکمل کراواتها با پیراهنها است.
چندین سرنخ خوب پیدا کردید تا بتوانید سودآوری شرکتتان را از طریق ابزارهای تحلیل کاوشگرانهی دادهها بهبود بخشید. حالا میخواهید اهداف اصلی را آماده و مطرح کنید (بخش ۲) تا سودآوری اقدامات کمپین را ارتقاء دهید. دفعهی بعد، مدلسازی جدی این کار را بهطور دقیق بررسی خواهید کرد.
و اما حرف آخر
امیدواریم هنگام کارکردن با دادههایتان، از ایفای نقش ادوارد دستقیچی لذت ببرید! بهزودی در بخش بعدی، مثال مطالعهی موردی از سری مقالات تحلیل بازاریابیِ خردهفروشی دایکه، جاییکه بیشتر راجع به الگوریتمهای درخت تصمیم کاوش میکنیم، شما را ملاقات خواهیم کرد!
[1] market basket analysis
[2] sequence analysis
[3] Scissorhands
[4] Socially Useful Productive Work
[5] Some Useful Paper Wasted
[6] John Nash
[7] Alan Turing
[8] Apriori algorithm
[9] frequency analysis