
شرلوک هولمز و تصویرسازی دادهها
 وقتی بچه بودم، یکی از دوستانم کیت اسباببازی شرلوک هولمز – منبع انگیزش حسادت سایر دوستان – داشت. این کیت حاوی کلاه شرلوک هولمز، پیپ، ساعت و ذرهبین بود. ذرهبین خواستنیترین شیئ داخل کیت بود. لذت فوکوسکردن ذرهبین روی شیئ و دیدن جزئیات آن بهمنظور استخراج معانی اولین درسم در تحقیقات جنایی – چیزی که هنوز هم بهعنوان تحلیلگر از آن خوشم میآید – بود. این هستهی تصویر سازی دادهها هم بود. بعدها، با خواندن کتابهای سِر آرتور کانن دویل[1]، چیزهای بیشتری راجع به آقای هولمز یاد گرفتم.
وقتی بچه بودم، یکی از دوستانم کیت اسباببازی شرلوک هولمز – منبع انگیزش حسادت سایر دوستان – داشت. این کیت حاوی کلاه شرلوک هولمز، پیپ، ساعت و ذرهبین بود. ذرهبین خواستنیترین شیئ داخل کیت بود. لذت فوکوسکردن ذرهبین روی شیئ و دیدن جزئیات آن بهمنظور استخراج معانی اولین درسم در تحقیقات جنایی – چیزی که هنوز هم بهعنوان تحلیلگر از آن خوشم میآید – بود. این هستهی تصویر سازی دادهها هم بود. بعدها، با خواندن کتابهای سِر آرتور کانن دویل[1]، چیزهای بیشتری راجع به آقای هولمز یاد گرفتم.
کتاب اول، پروندهی اسکارلت[2]، علاقهی آقای هولمز به دانش علمی و علم تحلیل استنتاجی را توصیف میکرد. من فهمیدم که کاراگاهبودن با دانشمند تجربی یا تحلیلگربودن خیلی فرق ندارد. شما کارتان را با جمعآوری مجموعهای از مشاهدات شروع میکنید و براساس این مشاهدات و ازطریق منطق و استنتاج پرونده تشکیل میدهید. این نقلقول آقای هولمز «زمانیکه ناممکن را حذف میکنید، چیزی که باقی میماند، هرچقدر هم غیرمحتمل، باید حقیقت باشد»، فرایند تحقیقات را بهطور کامل شرح میدهد.
تصویرسازی دادهها – مثال مطالعهی موردی
 در مقالهی قبلی از سری مقالات دایکه، بحث را با مثال مطالعهی موردیای راجع به بانک سیندیکت شروع کردیم که ۶۰۸۱۶ وام خودرو در سهماهی بین آوریل-ژوئن ۲۰۱۲ اعطا کرده بود. شما نقش مدیر ارشد ریسک (CRO) را برای این بانک ایفا میکردید. بهعلاوه، متوجه شدید که از بین ۶۰۸۱۶ وام اعطاشده، ۲.۵ درصد نرخ بد یا ۱۵۲۴ وام بد وجود داشت. کارتان را با گمانهزنیهایی راجع به رابطهی بین سن وامگیرندگان و نرخهای بد شروع کردید. پس از انجام تحلیل، رابطهی جمعیتی کامل معکوسی بین این دو مشاهده کردید. سن وامگیرندگان قطعاً حریف قدری برای مدل ریسک اعتبارتان بود. حس خوبی پیدا میکنید و قصد دارید متغیرهای بیشتری برای مدل چندمتغیرهتان پیدا کنید (مقالهی قبلی را مطالعه کنید).
در مقالهی قبلی از سری مقالات دایکه، بحث را با مثال مطالعهی موردیای راجع به بانک سیندیکت شروع کردیم که ۶۰۸۱۶ وام خودرو در سهماهی بین آوریل-ژوئن ۲۰۱۲ اعطا کرده بود. شما نقش مدیر ارشد ریسک (CRO) را برای این بانک ایفا میکردید. بهعلاوه، متوجه شدید که از بین ۶۰۸۱۶ وام اعطاشده، ۲.۵ درصد نرخ بد یا ۱۵۲۴ وام بد وجود داشت. کارتان را با گمانهزنیهایی راجع به رابطهی بین سن وامگیرندگان و نرخهای بد شروع کردید. پس از انجام تحلیل، رابطهی جمعیتی کامل معکوسی بین این دو مشاهده کردید. سن وامگیرندگان قطعاً حریف قدری برای مدل ریسک اعتبارتان بود. حس خوبی پیدا میکنید و قصد دارید متغیرهای بیشتری برای مدل چندمتغیرهتان پیدا کنید (مقالهی قبلی را مطالعه کنید).
ادامهی مثال مطالعهی موردی
همچنین معتقدید که درآمد متقاضیان باید به نوعی با نرخهای بد رابطه داشته باشد. راجع به درکتان از ابزارهایی که آخرین بار بهکار بردید، یعنی هیستوگرام و هیستوگرام نرمال (همپوشیشده با وامگیرندگان خوب/ بد) مطمئن بودید. کار را بلافاصله با رسم هیستوگرام بازهی یکسان شروع میکنید و به نتیجهی زیر میرسید: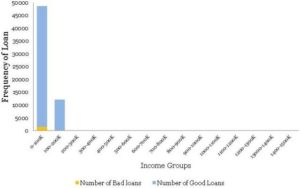
آخ آخ! این اصلاً شبیه هیستوگرام منحنی زنگولهای ملایمی که برای گروههای سنی مشاهده کردید نیست. حتی هیستوگرام نرمال زیر هم کاملاً ناکارامد است.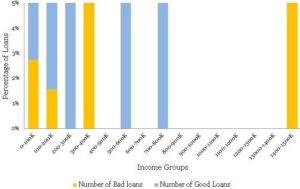
پس، اینجا چه خبر است؟ درآمد، برخلاف سن، دارای تعداد محدودی نقاط بسیار پرت می باشد که تقریباً در هیستوگرام دیده نمیشوند. فردی با شاخص ([3]HNI) معادل ۱.۴۷ میلیون حقوق سالانه و موارد پرت دیگری در وسط رؤیت میشوند. برحسب اتفاق، اعطای این وام به متقاضی بالاترین HNI بد پیش رفته است – و این به ضرر بانک است. به جدول توزیع زیر نگاهی بیندازید؛ تقریباً ۹۹.۸ درصد از جمعیت در دو باکت اول درآمد جای میگیرند.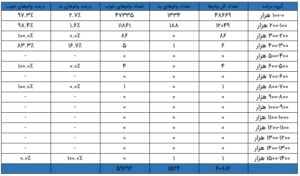
اینجا، بهعنوان تحلیلگر، باید تصمیم بگیرید که آیا میخواهید این موارد کرانی، با دادههای ناچیز را در مدلتان جای دهید یا مرز درآمدی بسازید که بهواسطهی آن، مدل برای اکثریت متقاضیان مناسب است یا نه. بهنظر من، گزینهی دوم انتخاب معقولانهای است. با ادامهی تحلیل کاوشگرانه و تصویر سازی دادهها تصمیم گرفتیم روی نواحی دارای تعداد نقاط دادهای فراوانتر، یعنی دو باکت اول تمرکز و هیستوگرام را از نو رسم کنید. هیستوگرام زیر همان چیزیست که مشاهده کردید: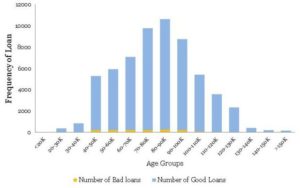
* تصحیح: محور x را بهعنوان گروههای درآمد (نه گروههای سنی) درنظر بگیرید.
اینبار، هیستوگرام نسبتاً ملایم است و از اینرو، مستلزم تبدیل نیست. شکل زیر، هیستوگرام نرمال هسیتوگرام فوق است:
نتایج زیر را میتوان از هیستوگرام بالا استخراج کرد:
- روند قطعیای در رابطه با نرخهای بد و گروههای درآمد وجود دارد. هرچه میزان کسب درآمد وامگیرندگان بالاتر باشد، احتمال نکول وامشان کمتر میشود. این بینش خوبی بهنظر میرسد.
- برای باکت آخر، یعنی ۱۵۰ هزار<، خطر افزایش مییابد؛ یعنی در روند وقفه ایجاد میشود. این مسئله به دادههای ناچیز در این باکت مرتبط است؛ این دادهها نه فقط با توجه به شمارش دادهها، بلکه در بازههای خیلی بزرگ ۱۵۰ تا ۱۵۰۰ هزار نیز پراکنده میشوند.
حالا دو متغیر – سن و درآمد – دارید که نرخهای بد حاکم احتمالی برای وامگیرندگان هستند. هرچند، تحلیل بیشتر راجع به درآمد با سن نشان میدهد که همبستگی بالایی – دقیقاً ۰.۷۶ – بین دو متغیر وجود دارد. نمیتوانید از هر دو متغیر در مدل استفاده کنید، چون بهدلیل همخطی چندگانه، مسئلهساز میشود. همبستگی بین سن و درآمد منطقی است. از آنجاییکه درآمد تابعی از سالهای تجربه برای فردی حرفهای است، پس بیشتر به سن این فرد بستگی دارد. بنابراین، تصمیم میگیرید درآمد را از مدل حذف کنید. این امر به مطرحشدن این پرسش منجر میشود: راهی برای بازگرداندن درآمد به مدل چندمتغیرهمان وجود دارد؟
نسبتهای مالی
زمانیکه تحلیلگران شرکت میکوشند امور مالی شرکتی را تحلیل کنند، اغلب با چندین نسبت مالی کار میکنند. کارکردن با نسبتها مزیت محرزی در مقایسه با کارکردن با متغیرهای ساده دارد. متغیرهای ترکیبی اغلب اطلاعات بیشتری ارائه میدهند. تحلیلگران بیتجربه این موضوع را کاملاً میفهمند. بهعلاوه، خلق متغیر تمرین خلاقانهای است که مستلزم دانشی مستدل است. برای تحلیل اعتباری، نسبت مجموع [تعهد] بدهیها به درآمد خیلی آموزنده است، چرا که این امر بینشی راجع به درصد درآمد قابلعرضه برای وامگیرندگان مهیا میکند.
بیایید سعی کنیم این موضوع را با مثال بفهمیم. درآمد سالانهی سوزان ۱۰۰ هزار دلار است. او وام مسکنی با بدهی سالانهی (EMI) ۴۰ هزار دلار و وام خودرویی با بدهی سالانهی ۱۰ هزار دلار دارد. بنابراین، سوزان ۴۰ + ۱۰ هزار دلار از ۱۰۰ هزار دلار درآمدش را روی پرداخت EMIها خرج میکند. نسبت بدهی ثابت به درآمد ([4]FOIR) سوزان در این مورد، ۵۰ درصد = ۱۰۰/۵۰ است. پس فقط ۵۰ درصد از درآمد سوزان برای تأمین سایر مخارجش باقی میماند.
شکل زیر، نمودار هسیتوگرام نرمال FOIR است:

بدیهیست که رابطهی متناسب مستقیمی بین FOIR و نرخ بد وجود دارد. بهعلاوه، FOIR همبستگی ناچیزی – فقط ۰.۱۸ – با سن دارد. حالا، علاوه بر سن متغیر دیگری بهنام FOIR برای مدل چندمتغیرهتان دارید. تبریک! شما هم مثل شرلوک هولمز دارید پروندهتان را با بررسی مدرک به مدرک – فرایندی در علم – میسازید.
مخلص کلام
امیدوارم پس از مطالعهی این بخش ترغیب شوید ذرهبین را بردارید و میراث شرلوک هولمز کبیر را پی بگیرید – اینبار اسرار در دادهها نهفتهاند!
[1] Sir Arthur Conon Doyle
[2] A Study in Scarlet
[3] High-Net worth-Individual
[4] Fixed Obligation to Income Ratio