نرمال سازی داده ها که عموماً بر روی متغیر های کمی انجام می شود با دو هدف انجام می شود:
1-هم مقیاس کردن داده های کمی
2- تغییر در توزیع آماری و کاهش چولگی
نرمال سازی داده ها (Normalization) – هم مقیاس سازی
نرمال سازی یکی از تکنیک های مقیاس بندی ( Scaling )، نگاشت ( mapping ) در فرآیند داده کاوی است. در این روش میتوانیم داده ها را از بازه فعلی آن به یک بازه دیگر نگاشت کنیم. این رویکرد میتواند کمک زیادی در اهداف پیش بینی و تجزیه و تحلیل های ما داشته باشد، بنابراین با توجه به تنوع مدل های پیش بینی در داده کاوی و به منظور حفظ این تنوع، تکنیک های نرمال سازی به ما کمک میکند تا این پیش بینی ها را به یکدیگر نزدیک کنیم.
فرض کنیم که یک دیتاست حاوی دو فیلد میزان درآمد و سن را در اختیار داریم، سن دامنه 20 تا 65 سال را دارد و دامنه درآمد از 2.5 تا 25 میلیون تومان است. در صورتیکه بخواهیم داده ها را خوشه بندی کنیم می تواند منجر به کاهش اثر ویژگی سن ( بطور کاذب) در مدل شود.
روش های نرمال سازی عمدتا دامنه داده های خام را به دامنه کنترل شده ای مانند [0,1] یا [1,1-] انتقال می دهند تا اثر واحد اندازه گیری را خنثی کنند.

روش های نرمالسازی جهت هم مقیاس سازی به معنای نرمال کردن توزیع آماری نیست
روش Min-Max
با تبدیل خطی بر روی داده ها، دامنه آنها را به بازه 0 تا 1 نگاشت می دهد.

سوال: با تغییر در رابطه فوق دامنه تبدیل Min
–Max را به بازه a تا b نگاشت دهید.

برای مثال فرض کنید دادههای سن برای افراد مختلف مانند شکل زیر است و ما میخواهیم سنِ این افراد را در یک بازهی ۰ تا ۱ قرار دهیم. با توجه به فرمول بالا نتیجه به این صورت است:

همانطور که میبینید هر کدام از نمونهها با توجه به مقادیرِ کمینه (
min) و
بیشینه (
max) به بازهی ۰ تا ۱ تبدیل شدهاند. همین کار را میتوان برای ستونهای دیگر مانند حقوق انجام داد. شکل اولِ این درس را ببینید. با نرمالسازیِ دادهها در بازهی ۰ تا ۱، نمودار در ۲ بُعدی چیزی شبیه به شکل زیر میشود:

یعنی مقیاسِ هر دو ویژگی در بازهی ۰ تا ۱ قرار گرفته و حالا میتوان الگوریتمهای مختلف خوشهبندی و یا طبقهبندی را بر روی آنها به صورت منصفانه اجرا کرد.
روش Z-Score
مقدار Z-score از طریق رابطه زیر محاسبه میشود که در آن، x̅ مقدار میانگین جمعیت آماری و s انحراف معیار جمعیت میباشد. مقدار قدر مطلق (absolute value) محاسبه شده برای z، فاصله آن ردیف از داده ها را از میانگین کل جمعیت بر حسب انحراف معیار نشان میدهد. هنگامی که این مقدار مثبت باشد، یعنی Z-score بالاتر از میانگین و اگر منفی باشد، نشان دهنده کمتر بود آن مقدار خاص، از میانگین کل داده ها میباشد.
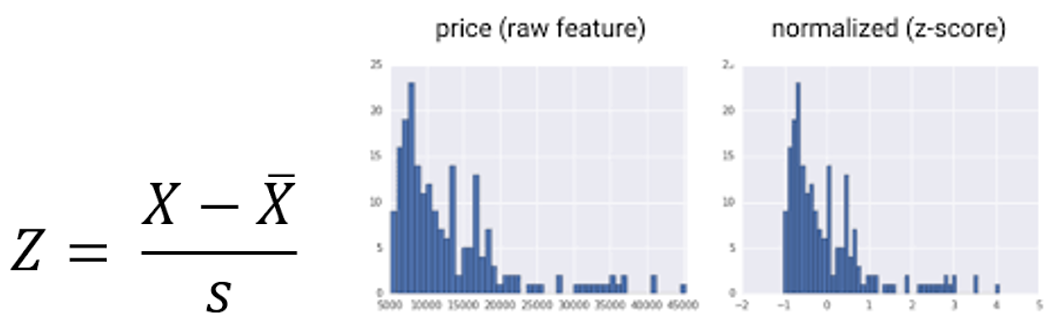 نکته: تبدیل Z-Score توزیع داده ها را نرمال نمی کند و منجر به کاهش چولگی نمی شود.
نکته: تبدیل Z-Score توزیع داده ها را نرمال نمی کند و منجر به کاهش چولگی نمی شود.
روش Robust Scaling
در روش مقیاس بندی ویژگی منسجم یا همان Robust Scaling از چارکهای اول، دوم و سوم دادهها استفاده میشود. این روش از تغییر مقیاس یا همان مقیاس بندی ویژگی در شرایطی که دادههای پرت (Outlier) وجود داشته باشد، بسیار کارآمد خواهد بود. رابطه ریاضی موجود برای این تبدیل به صورت زیر است:
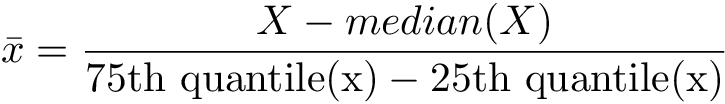
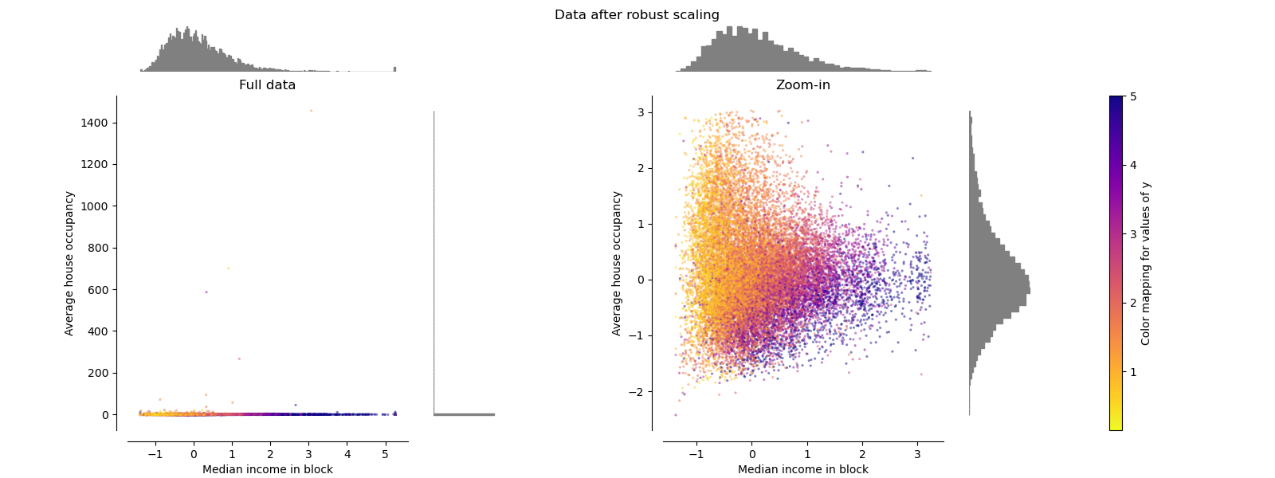
● در این روش، میانه روی صفر تنظیم میشود و فاصله بین چارک اول تا چارک سوم معادل یک واحد خواهد بود.
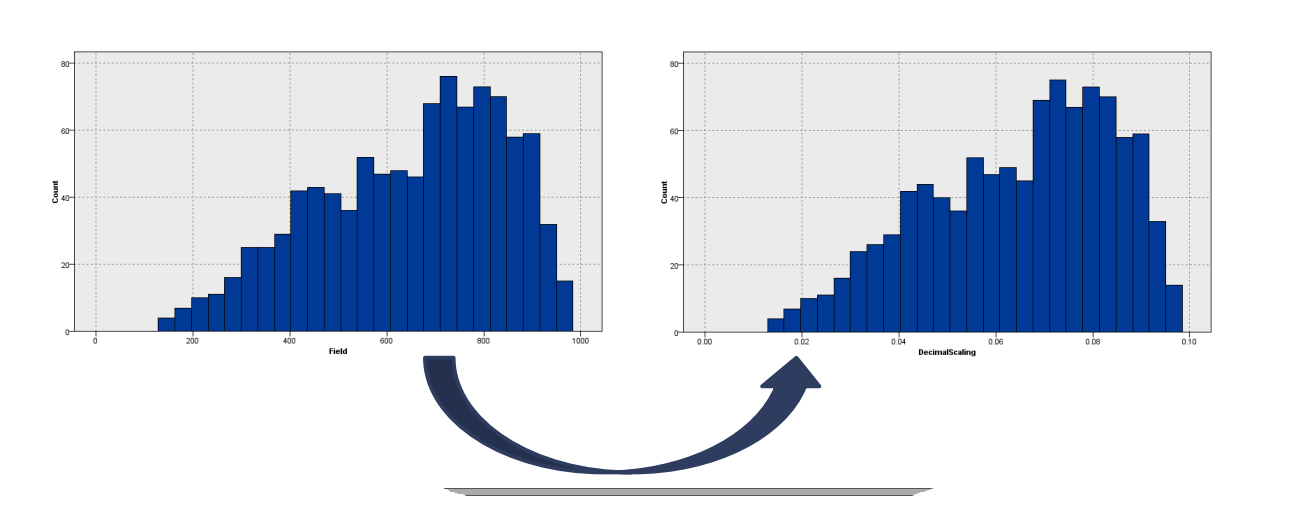
روش Decimal Scaling
مقیاس گذاری اعشاری نوع دیگری از روشهای نرمالسازی است که در واقع منطق آن تغییر نقطه اعشار مقادیر موجود در مجموعه داده است. در این روش، نرمالسازی با استفاده از رابطه زیر انجام میشود:

با تبدیل خطی، با تغییر مکان اعشار به تعداد ارقام مقدار حداکثر مطلق انجام می شود. در رابطه زیر مقدار j کوچکترین عدد صحیحی است که مقدار قدر مطلق دادهای نگاشت داده شده را کوچکتر از مقدار 1 باشد.
روش های نرمال سازی با هدف تغییر توزیع آماری:
در برخی از مدل ها به خصوص مدل های آماری، نیاز به وجود فرض نرمال بودن توزیع آماری یکی از فرضیات مدل سازی است. برخی تبدیل های رایج همچون تبدیل لگاریتمی، نمایی، توانی و … با کاهش چولگی توزیع داده ها می تواند به این هدف کمک کند.

تبدیل Box-Cox
در آمار، تبدیل توانی (Power Transformation)، به خانوادهای از توابع گفته میشود که برای ایجاد یکنواختی روی دادهها با استفاده از توابع توانی (Power Functions) به کار میروند. این روشهای تبدیل در تحلیلهایی که احتیاج به تثبیت واریانس دارند یا ایجاد دادهها با توزیع نرمال هدف است و همچنین بهبود سنجش ارتباط بین متغیرها بخصوص توسط ضریب همبستگی پیرسون و … مورد استفاده هستند.
در صورتی که ویژگی y دارای مقادیر کوچکتر از صفر باشد:

در صورتی که کلیه مقادیر ویژگی y بزرگتر از صفر باشد:
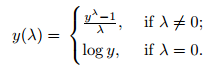
برای تعیین مقدار مناسب λدر تبدیل باکس کاکس، معمولا روشهای تبدیل را با پارامترهای مختلف λروی دادهها به کار برده و با استفاده مقدار حداکثر تابع درستنمایی، بهترین مقدار پارامتر λ را انتخاب میکنند. البته این امر را با تکنیکهای سنجش نرمال بودن دادهها نظیر Q-Q plot و یا آزمونهای نرمال بودن نیز میتوان مشخص کرد که کدام مقدار λ بهترین تبدیل برای ایجاد دادههای نرمال برای نمونه اصلی است
برای تعیین بهترین مقدار پارامتر 𝜆 معمولا در دامنه 5- تا 5 الگوریتم باکس کاکس اجرا می شود تا بهترین مقدار برای نرمال سازی بر اساس آزمون آماری نیکویی برازش بدست آید.