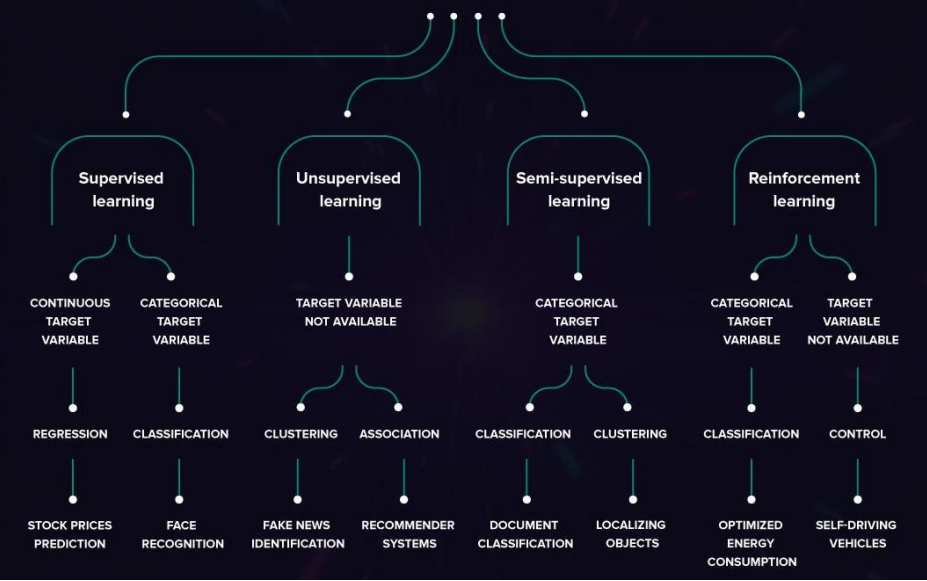
زمانی که ما در علم داده با دیتاها کار میکنیم، در واقع با انواع متفاوتی از یادگیری مواجه هستیم:
- یادگیری با نظارت (Supervised Learning)
- یادگیری بدون نظارت (UnSupervised Learning)
- یادگیری نیمه نظارتی (Semi-Supervised Learning)
- یادگیری تقویتی (Reinforcement learning)
در اینجا قصد داریم برای هر یک از این روشها توضیح مختصری بیان کنیم.
یادگیری با نظارت
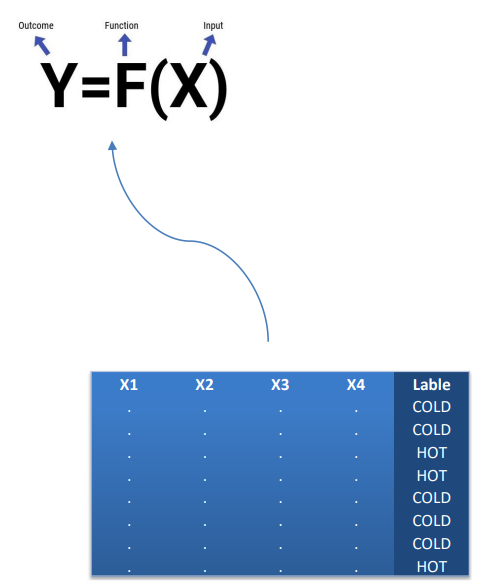
هرجا که مجموعه ای از داده ها را به صورت ویژگی هایی به عنوان یک مدل داشته باشیم و بر مبنای آنها بخواهیم به یک تارگت مشخص برسیم، در واقع با یادگیری با نظارت سر و کار داریم. مانند مثال دوم که قبلاً برای خوش حساب یا بد حساب بودن مشتریان یک بانک گفته شد.
تمام الگوریتم های که بتوانند این نوع الگو را شناسایی کنند، روش یادگیری آنها روش یادگیری با نظارت است. ما یک سری روش های یادگیری داریم که یادگیری با نظارت (با راهنما) یا بدون نظارت (بدون راهنما) هستند و هر کدام از آنها یک سری مسئله ها دارند.
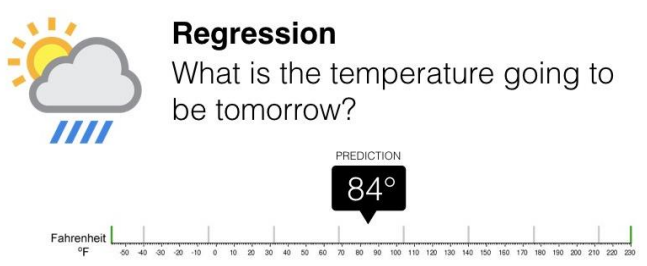
مسئله رگرسیون(Regression): پیش بینی مقدار هدف با توزیع آماری پیوسته.
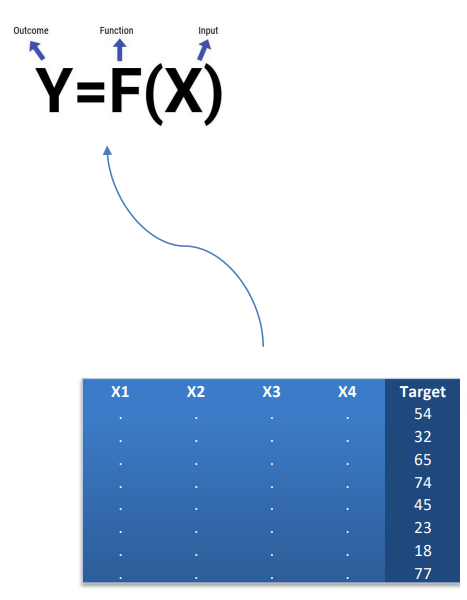
در اینجا ما به دنبال این هستیم که (x)f را تخمین بزنیم که تابعی از ورودی های ما یعنی xها است و در نهایت بتواند ستون y یا همان تارگت ما را پیش بینی کند. تلاش میکنیم که این کار با کمترین خطا و بیشترین دقت انجام شود. به عنوان مثال دمای هوای فردا را پیش بینی کنیم و به صورت عددی بیان کنید این در واقع یک مسئله رگرسیون است.
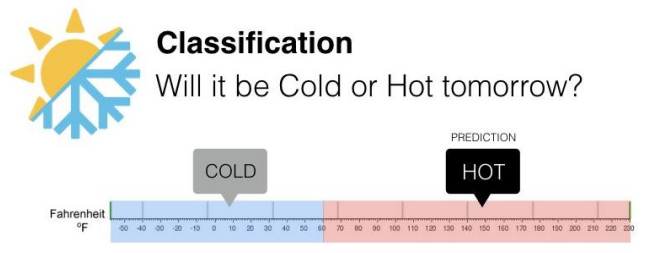
مسئله طبقه بندی (Classification): پیش بینی برچسب به هدف با توزیع آماری گسسته.
در مثال قبل اگر به جای یک عدد به عنوان دما بخواهیم سطح دما را پیش بینی کنیم و آن را به عنوان گرم یا سرد بیان کنیم جوری که به عنوان مثال دماهای زیر ۶۰ درجه به عنوان سرد و دماهای بالای ۶۰ درجه به عنوان گرم باشند و صرفاً میخواهیم پیش بینی کنیم که آیا فردا هوا گرم است یا هوا سرد است؟ آنگاه نوع مسئله از نوع طبقه بندی است چون اینجا ستون تارگت یک توزیع آماری گسسته است.
روش یادگیری بدون نظارت
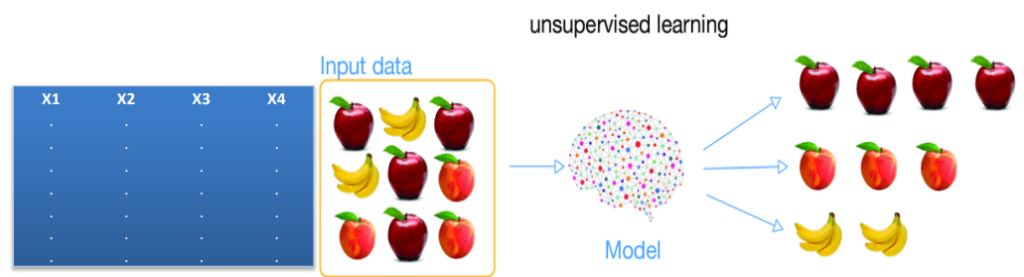
یکی از اصلیترین تسکهای آن تسک خوشهبندی (Clustering) است: دسته بندی اتوماتیک مشاهدات بر مبنای معیار شباهت. مانند مثال اولی که قبلاً ذکر شد و خریداران یک فروشگاه را طبقه بندی کردیم. آن جا هیچ برچسبی برای تقسیم بندی خریداران نداشتیم و آن ها تقسیم بندی نشده بودند و ستون تارگت را نداشتیم. صرفا اطلاعات ورودی داشتیم و هیچ ذهنیتی از خروجی و هدف نداشتیم. یعنی الگوهای ما اینجا هیچ هدف مشخصی ندارند که بتوانند به دنبال آن بگردند. نوع مسئله کاملاً عوض شده است.
معیار شناسایی و تفکیک الگوها در این نوع داده ها و این نوع مسائل بر مبنای شباهت است به عنوان مثال داده های ما تعدادی میوه هستند الگوریتم بر مبنای شباهت آنها مدلی را استخراج می کند که بتواند بگوید این سیبها شبیه همدیگر هستند. این هلوها یک مجموعه را شکل می دهد چون شبیه همدیگر هستند و موزها نیز همینطور. بنابراین ۳ مجموعه ایجاد شد با اینکه از قبل هیچ ذهنیتی از تعداد مجموعه ها و تعداد اعضای آن ها نداشتیم مانند همان مثال اول که قبلا توضیح دادیم.
بنابراین کار خوشه بندی درواقع دسته بندی کردن داده هاست. اما در طبقه بندی، دسته ها و طبقه ها از قبل مشخص شده بودند و بر مبنای داده های هیستوریکال برچسب خورده بودند و می دانیم که به دنبال چه نوع داده هایی باشیم، اما برای خوشه بندی نمی دانیم. الگوریتم باید به ما پیشنهاد بدهد که در ساختار داده ها چند الگوی متمایز می توانیم از یکدیگر شناسایی کنیم.
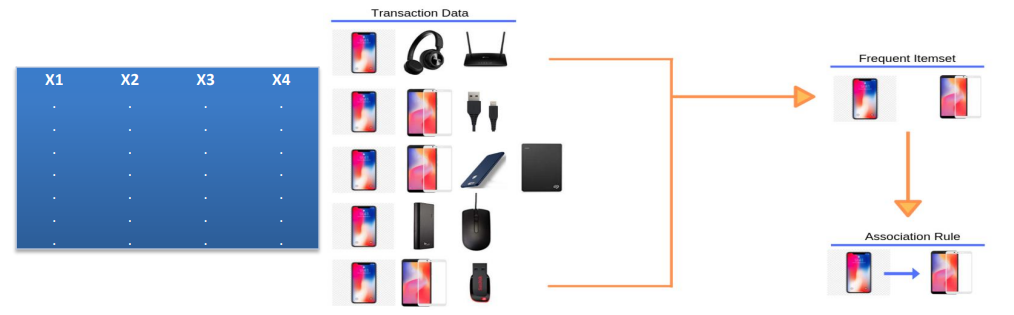
قوانین انجمنی (Association Rules): تحلیل وابستگی بین وقوع رخدادها از نظر باهمآیی و تقدم-تاخر
این تسک با ۳ تسک قبلی که معرفی شدند یک تفاوت مهم دارد اینکه مبنای این روش نه آمار است و نه یادگیری ماشین. بلکه روشهای قوانین انجمنی در حوزه دیتابیس و پایگاه داده توسعه پیدا کرده اند و افرادی که آنجا الگوریتم می نوشتند الگوریتمی را توسعه دادند که بتواند تشخیص دهد که چه اقلامی به صورت پر تکرار با هم استفاده شدهاند یا خریداری شده اند.
به عنوان مثال در یک فروشگاهی که ابزار و اقلام مربوط به گوشی موبایل و کامپیوتر را به فروش می رساند بررسی میکند که چه اقلامی به صورت پرتکرار با هم به فروش رسیده اند. به طور مثال به این نتیجه میرسد که گوشی موبایل و کاور به صورت پر تکرار با هم به فروش رسیدند. آنگاه لازم است بررسی کند که خرید گوشی موبایل به خرید کاور انجامیده و باعث خرید کاور شده است و یا خرید کاور باعث خرید گوشی موبایل شده است.
اینجا جهت بین کاور و گوشی بسیار مهم است که به درستی تشخیص داده شود تا در خرید های بعدی به خریداران به طور مناسب نمایش داده شود تا شانس پذیرش آن از طرف خریدار بالا باشد و منجر به خرید شود و فروش محصولات افزایش یابد. گاهی ممکن است که این رابطه صرفاً یک طرفه باشد و گاهی ممکن است که دو طرفه باشد و خرید هر کدام از این اقلام منجر به خرید دیگری نیز بشود.
روش یادگیری نیمه نظارتی
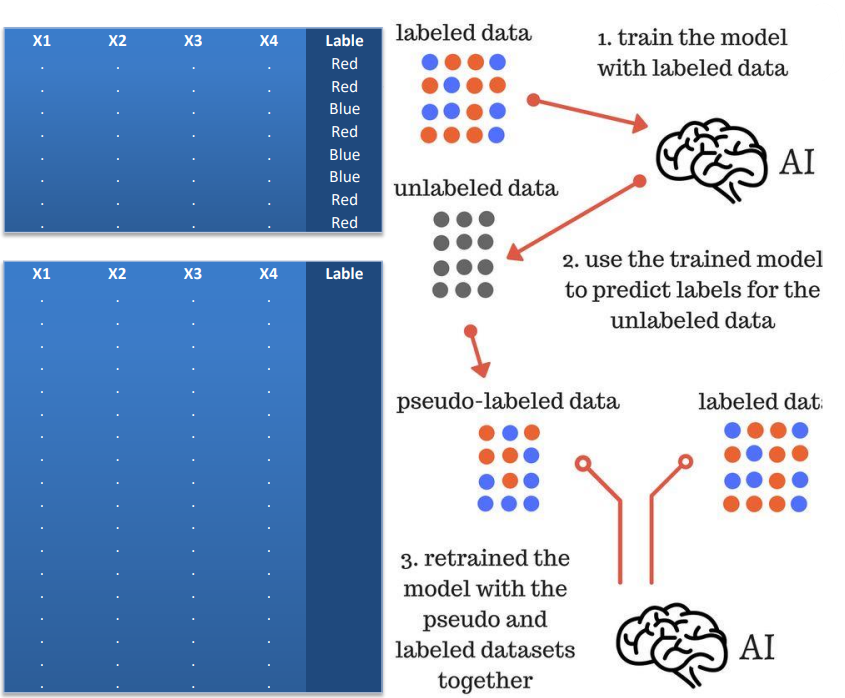
در برخی از مسائلی که در دنیای واقعی با آنها سر و کار داریم الزاما بدون برچسب نیستیم و یک سری برچسب ها را داریم اما الزاما همه داده های ما برچسب ندارند. به عنوان مثال در یک شرکت بیمه تعداد زیادی پرونده موجود است است به مرور زمان برای برخی از از پرونده ها برچسب خورده است که این حادثه و این پرونده بیمه واقعی است و خسارتی وارد شده است.
اما برای برخی برچسب خورده است که این حادثه تخلف بوده و واقعی نبوده است. آن شرکت بیمه برای تمامی صددرصد پرونده های خود این برچسب را نزده است و برای درصد کمی از پروندهها این برچسب موجود است. یعنی به عنوان مثال زمانی که جدول آنها را ترسیم می کنیم برخی از داده ها برچسب دارند و برخی ندارند بنابراین باید ترکیبی از روش های یادگیری نظارتی و یادگیری بدون نظارت را اعمال کند. یعنی در بخشی از دیتا ها که برچسب داریم مانند روش های یادگیری نظارتی مسئله را حل می کند و تابع به دست آمده را روی بقیه داده ها که برچسب ندارند اجرا می کند و برای آنها برچسب هایی را که نامشخص است تبدیل به برچسب های پیشبینی شده می کند.
اکنون ما یک سری دیتا را با برچسب های پیش بینی شده داریم. حالا یک مجموعه دیتای کامل داریم که همه آنها برچسب دارند؛ برخی از آنها برچسب واقعی و برخی از آنها برچسب پیش بینی شده توسط مدل را دارند. حالا مدل را برای تمامی داده ها اجرا می کنیم که به مدل نهایی برسیم.
روش یادگیری تقویتی
در این نوع یادگیری زوج ورودی-خروجی وجود ندارد و سیستم بر اساس هر اکشن انجام شده از محیط پاداش می گیرد. بنابراین در نهایت سیستم تلاش می کند مجموع پاداش خود را بیشینه کند. این فرایند باید در محیط های داینامیک و پویا انجام شود جایی که سیستم از نظر نرم افزاری توانایی و قابلیت اکشن و پاسخ سریع از محیط را داشته باشد بنابراین رباتیک یکی از حوزه های بسیار مهم در یادگیری تقویتی است. الگوریتم های مسیریابی می تواند یکی از جاهای بسیار پر کاربرد این نوع یادگیری باشد.
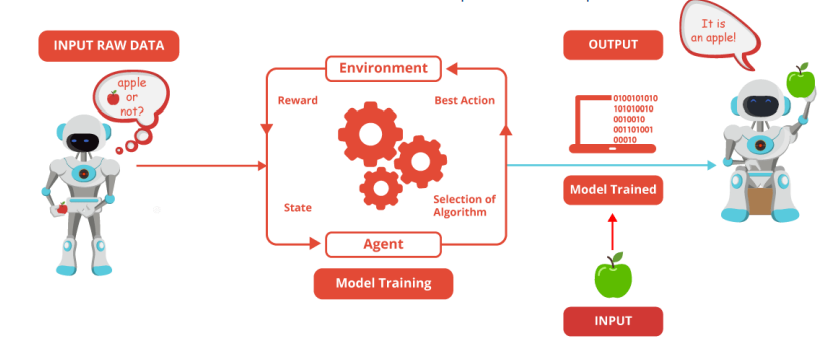
با توجه به توضیحات داده شده بسیار مهم است که ما تشخیص دهیم در این مسئله یادگیری با نظارت است یا بدون نظارت؟ و زمانی که مثلاً تشخیص دادیم یادگیری با نظارت است بدانیم که از رگرسیون استفاده کنیم یا از طبقه بندی؟ در هر کدام از آنها نیز الگوریتم های مختلفی وجود دارد. و انتخاب الگوریتم مناسب بسیار مهم است. لازم است که قدم های مناسبی را برای انتخاب الگوریتم برداریم:
قدم اول:
آیا در مسئله مورد نظر به دنبال پیشبینی یک هدف هستیم؟ (یادگیری با نظارت) یا به دنبال شناسایی ساختار درونی داده میگردیم؟ (یادگیری بدون نظارت)
قدم دوم:
در صورت داشتن هدف آیا توزیع احتمالی آن پیوسته هست (رگرسیون) یا گسسته؟ (طبقه بندی)
قدم سوم:
آیا نوع الگویی که برای حل مسئله نیاز داریم محدودیت خاصی دارد: مانند استخراج قوانین، مدل تابعی، مدل جعبه سیاه و…؟