
همانطور که در ابتدای مباحث داده کاوی اشاره شده یکی از روش های شناخت و آماده سازی داده ها، کاهش ابعاد و انتخاب نمونه است. کاهش ابعاد تبدیلی است که در آن سعی می شود از تعداد متغیر ها کاسته شود. در این روش اقدام به حذف فیلد های نا مرتبطی که ارزش تحلیلی ندارند و یا فیلد هایی که موجب افزونگی داده می شوند، می نماییم.
اهداف کاهش ابعاد
کاهش حجم داده ها و در پی آن افزایش سرعت پردازی، افزایش دقت الگوریتم های مورد استفاده و جلوگیری از بیش برازش، کاهش ابعاد داده منجر به کاهش فیلد ها و ساده تر شدن نتایج برای درک و تفسیر می شوند.

انتخاب ویژگی (Feature Selection)
در این رویکرد، با انتخاب زیر مجموعه مناسبی از ویژگی های مرتبط و حذف مابقی ویژگی ها، کاهش داده صورت می گیرد. از آنجا که در این روش ماهیت ویژگی ها تغییر نمی کند، در اغلب مسائلی که نیاز به تفسیر نتایج وجود دارد این روش استفاده می شود.
برای انتخاب ویژگی نیاز به انجام سه گام داریم:
گام اول در انتخاب ویژگی بر اساس دانش زمینه ای و نظر افراد خبره، حذف داده ای نا مرتبط با مسئله هست.
گام دوم در انتخاب ویژگی بر اساس گزارش کیفی داده ها، بررسی و اقدام در شرایط زیر است:
- حذف ویژگی های دارای مقادیر گمشده بسیار زیاد (فیلد هایی که بیش از 50% missing value داشته باشند)
- حذف ویژگی های دارای واریانس بسیار کم
- حذف ویژگی های کیفی دارای کلاس های زیاد
گام سوم در انتخاب ویژگی بر اساس تحلیل همبستگی بین ویژگی ها، بررسی وجود همخطی (Collinearity) بین داده ها است تا نسبت به حذف ویژگی یا انتخاب استراتژی مناسب (تبدیل/استخراج ویژگی/…) اقدام لازم صورت گیرد..
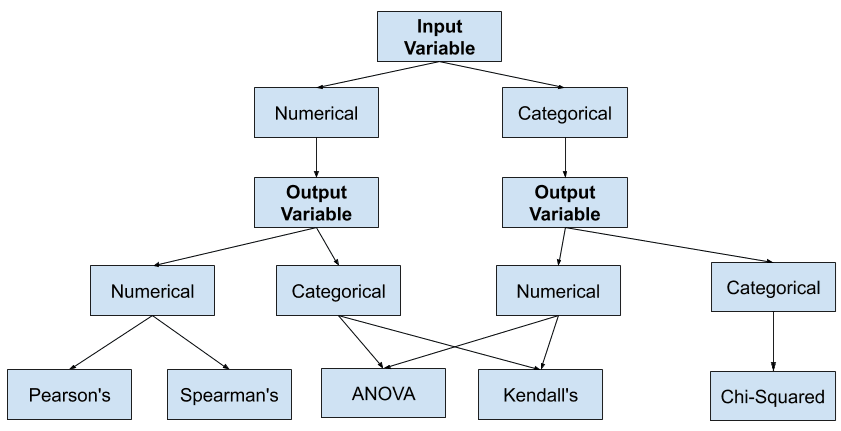
گام چهارم در انتخاب ویژگی بر اساس رابطه با فیلد هدف (رویکرد با نظارت)، استفاده از رویکردهای زیر می باشد:
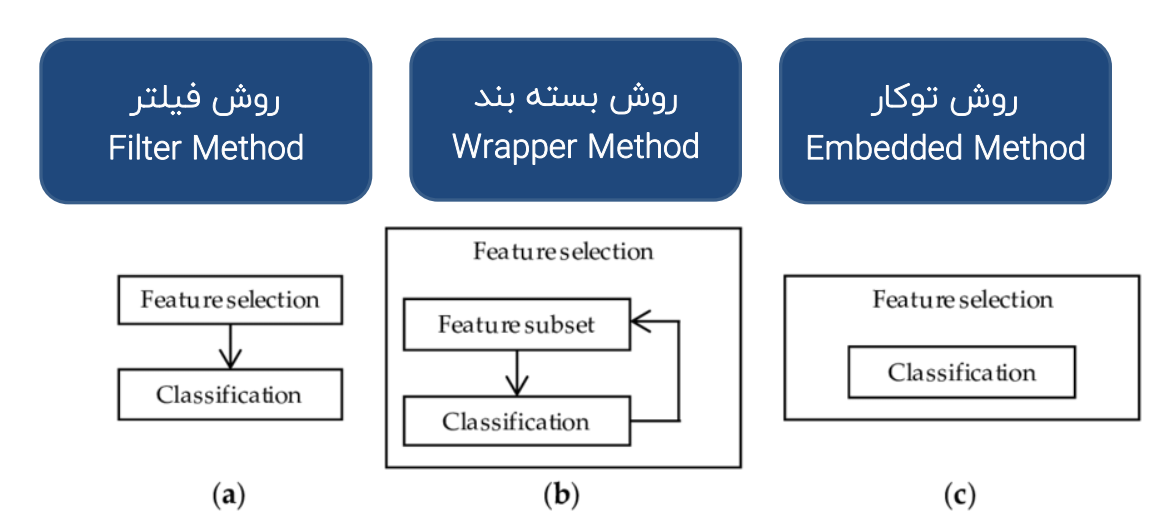
روش فیلتر (Filter Method)
رویکرد اول در این روش، با ارتباط سنجی آماری بین هر کدام از ویژگی ها با فیلد هدف (مستقل از مدل)، به انتخاب زیر مجموعه مناسبی از ویژگی های مرتبط می پردازد.
نقاط قوت:
سادگی محاسباتی و سریع
نقاط ضعف:
مشکلات افزونگی داده راحل نمی کند
اثر متقابل بین ویژگی ها بررسی نمیشود
زمانی که از شاخص های آماری برای انتخاب ویژگی استفاده می نماییم، میتوانیم به جای استفاده از آزمون های فرض از شاخصی به نام شاخص آنتروپی (Entropy) استفاده نماییم.
فرض کنیم مطابق جدول روبرو فیلد هدف این است که بدست آید آیا یک بازی گلف برگزار می شود یا خیر؛ در این حالت می توان محاسبه نمود که احتمال برگزاری بازی چقدر است.
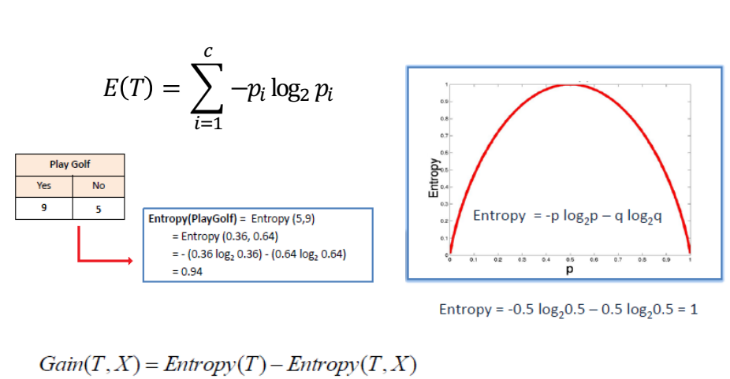
اگر احتمال برگزار شدن و برگزار نشدن بازی را در لگاریتم دوم همان احتمال محاسبه نماییم و جمع را بدست آوریم شاخص آنتروپی را بدست آورده ایم.
در واقع شاخص آنتروپی اختلال یا بی نظمی خلوص داده ها را بیان می کند و هر چقدر این آنتروپی بیشتر باشد به داده های بیشتری برای بدست آوردن نتایج دقیق تر برای تحلیل نیازمندیم.
شاخص بهره اطلاعاتی (Information Gain)
وقتی که از یک فیلد برای کاهش آنتروپی استفاده می نماییم مطابق تصویر مثال زیر عمل نموده ایم.

تحلیل حساسیت (Sensitivity analysis)
این روش مبتنی بر اهمیت ویژگی است و رویکرد دیگر در روش فیلتر، محاسبه و رتبه بندی اهمیت هر ویژگی برای هر مسئله می باشد. اندازه گیری اهمیت هر ویژگی با روش تحلیل حساسیت انجام می شود.
تجزیه و تحلیل یا «آنالیز حساسیت» (Sensitivity Analysis) تعیین میکند که چگونه مقادیر مختلف یک متغیر مستقل بر یک متغیر وابسته تحت مجموعهای از مفروضات تأثیر میگذارد. به عبارت دیگر، تجزیه و تحلیل حساسیت روشی برای بررسی و مطالعه چگونه تاثیر منابع مختلف (در محیط مطلق یا عدم اطمینان) در یک مدل ریاضی است. این تکنیک در حوزههایی استفاده میشود که با یک یا چند متغیر ورودی سرکار داشته و بخواهیم رفتار یک تابع یا رابطه با براساس آنها بسنجیم.
در مرحله اول با ساخت مدل روی همه ویژگی ها میزان خطا محاسبه میشود و سپس در هر مرحله یکی از ویژگی ها حذف شده و با مقایسه میزان خطای جدید با مقدار اولیه، میزان اهمیت آن ویژگی برآورد می شود.
نکته مهم: در روش مبتنی بر اهمیت ویژگی، به علت بررسی اثر متقابل و همبستگی بین ویژگی ها در ساخت مدل ها، اثر افزونگی داده ها توسط مدل ها کنترل می شود
تعریف ساده تحلیل حساسیت:
وقتی رفتار یک سیستم را تحلیل میکنیم، تحلیل حساسیت به این معنا خواهد بود که محاسبه و برآورد کنیم که رفتاری که برای سیستم پیش بینی کردهایم (خروجی آن سیستم) تا چه حد به مقادیر متغیرهای مستقل (ورودی آن سیستم) حساس است.
مثال:
فرض کنید میخواهید یک کسبوکار جدید برای خود شروع کنید. ایده شما این است که تیشرتهای بدون طرح را از یک عمدهفروش خریداری کنید و طرحهای خلاقانهای که فکر میکنید مورد استقبال بازار قرار میگیرد بر روی آنها چاپ کنید و بفروش برسانید. برای این منظور یک دستگاه چاپگر بر روی پارچه نیاز دارید که قسمت عمده هزینه ثابت (FC) شما را تشکیل میدهد.
برآوردی هم از هزینه متغیر (VC) تولید هر تیشرت طرحدار شامل قیمت خرید عمدهفروشی هر تیشرت و هزینههای مربوط به چاپ دارید. با بررسی بازار، به این نتیجه میرسید که میتوانید تیشرتهای خود را با قیمت P بفروش برسانید. برآورد شما این است که بتوانید Q عدد از تیشرتهای خود را بفروشید.
با داشتن این اعداد میتوانید سود خود را محاسبه کنید؛ اما در دنیای واقعی با عدم قطعیتهایی مواجه هستیم. اگر نتوانید با قیمت موردنظر محصولات خود را عرضه کنید چه تأثیری روی سود شما میگذارد؟ اگر به اندازهای که پیشبینی کردید با تقاضا مواجه نشوید چه میشود؟ و یا برعکس اگر با استقبال خریداران مواجه شدید سود شما چه تغییری میکند؟
![]()
روش بسته بند (Wrapper Method)
این روش با ساخت تعداد زیادی مدل پیش بینانه روی زیر مجموعه های مختلفی از ویژگی های ورودی، و ارزیابی عملکرد آنها بهترین زیر مجموعه از ویژگی های ورودی را انتخاب میکند.
این دسته از روش های انتخاب ویژگی، در هر مرحله، زیر مجموعهای از ویژگیها در فضای ویژگی را انتخاب میکند و عملکرد الگوریتم یادگیری ماشین روی این زیر مجموعه سنجیده میشود. از نتیجه عملکرد الگوریتم یادگیری ماشین، برای ارزیابی زیرمجموعه انتخاب شده از فضای ویژگی استفاده میشود.
به عنوان نمونه، مشخص میشود که کدام یک از زیر مجموعههای انتخاب شده، بیشترین تاثیر را در افزایش دقت یک مسأله دستهبندی خواهند داشت. از این روش مدلسازی و جستجوی ویژگی برای انتخاب ویژگی جهت آموزش انواع روشهای یادگیری ماشین استفاده میشود.
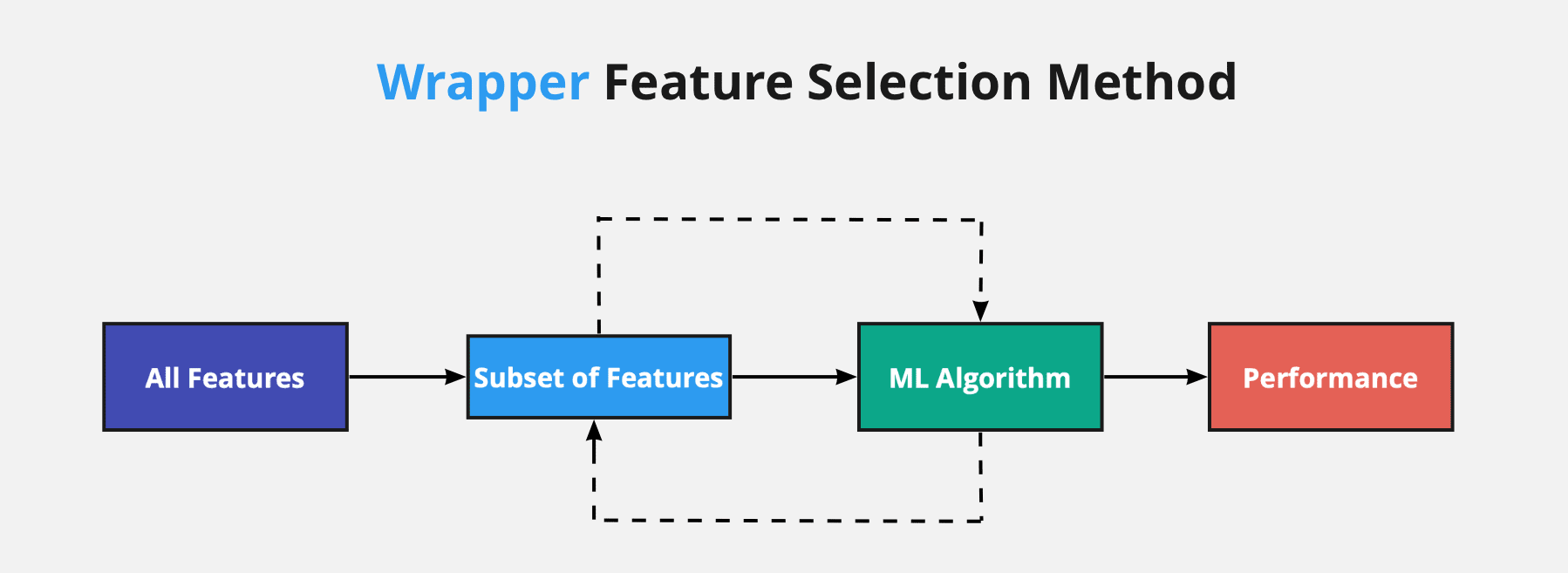
قابلیت بهینه سازی در انتخاب ویژگی های موثر با رویکردهای زیر:
- استفاده از الگوریتم های Search
- رویکرد Forward Selection
- رویکرد Backward Elimination
- رویکردStep-wise Selection (Bidirectional Elimination)
نکات قوت
- بررسی همبستگی و اثر متقابل بین ویژگی ها
- کنترل افزونگی داده ها
- تعیین تعداد بهینه از ویژگی های موثر
نکات ضعف
- پیچیدگی محاسباتی بیشتر نسبت به روش فیلتر
- مستعد بیش برازش به علت استفاده از مدل پیش بینانه
استفاده از الگوریتم های Search
Hill- climbing (Greedy stepwise)
الگوریتم تپهنوردی (Hill climbing) الگوریتمی است که برای یافتن بهترین پاسخ یک مسئله یا برای پیدا کردن پاسخی از مسئله که به اندازهٔ کافی مناسب و بهینه باشد، استفاده میشود.
در اینجا بیشتر مسئلههایی مورد بحث قرار میگیرند که چندین پاسخ با ارزش برابر دارند و هدف ما یافتن یکی از آن هاست.
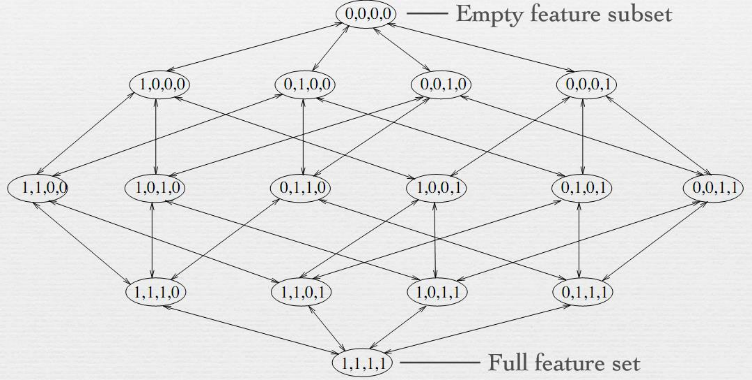
برای بررسی الگوریتم تپهنوردی مسئلهٔ زیر را بررسی میکنیم:
– تابع f به هر یک از اعضای مجموعهٔ متناهی S یک عدد حقیقی نسبت میدهد. هدف ما یافتن عضوی از S است که بیشترین (یا کمترین) مقدار به آن نسبت داده شدهاست.
همان گونه که گفته شد در اینجا فرض بر این است که مقدار تابع f برای چندین عضو مختلف S بیشینه است و هدف ما یافتن تنها یکی از آن هاست. (در غیر این صورت معمولاً الگوریتم تپهنوردی، الگوریتم کار آمدی نیست)

Best-first search
جستجوی ابتدا-بهترین (best-first search) یک الگوریتم جستجو است که یک گراف را با بسط دادن محتملترین راس، که بنابر قوانین خاص انتخاب میشود، پیمایش میکند.
این نوع جستجو را به عنوان تخمین تعهد نود n به وسیلهٔ heuristic evaluation function [۱] توصیف میکند، که به صورت کلی، ممکن است بر پایه توصیف n، توصیف هدف، اطلاعات جمعآوری شده به وسیلهٔ جستجو تا آن نقطه و هر گونه اطلاعات اضافی در زمینهٔ مسئله باشد.
Genetic Algorithm
الگوریتمهای ژنتیک (Genetic algorithm) تکنیک جستجو در علم رایانه برای یافتن راهحل تقریبی برای بهینهسازی مدل، ریاضی و مسائل جستجو است. الگوریتم ژنتیک نوع خاصی از الگوریتمهای تکاملی است که از تکنیکهای زیستشناسی فرگشتی مانند وراثت، جهش زیستشناسی و اصول انتخابی داروین برای یافتن فرمول بهینه جهت پیشبینی یا تطبیق الگو استفاده میشود.
الگوریتمهای ژنتیک اغلب گزینه خوبی برای تکنیکهای پیشبینی بر مبنای رگرسیون هستند. در مدلسازی الگوریتم ژنتیک یک تکنیک برنامهنویسی است که از تکامل ژنتیکی به عنوان یک الگوی حل مسئله استفاده میکند. مسئلهای که باید حل شود دارای ورودیهایی میباشد که طی یک فرایند الگوبرداری شده از تکامل ژنتیکی به راهحلها تبدیل میشود سپس راه حلها به عنوان کاندیداها توسط تابع برازش یا تابع برازندگی (Fitness Function) مورد ارزیابی قرار میگیرند و چنانچه شرط خروج مسئله فراهم شده باشد الگوریتم خاتمه مییابد.
بهطور کلی یک الگوریتم مبتنی بر تکرار است که اغلب بخشهای آن به صورت فرایندهای تصادفی انتخاب میشوند که این الگوریتمها از بخشهای تابع برازش، نمایش، انتخاب و تغییر تشکیل میشوند.
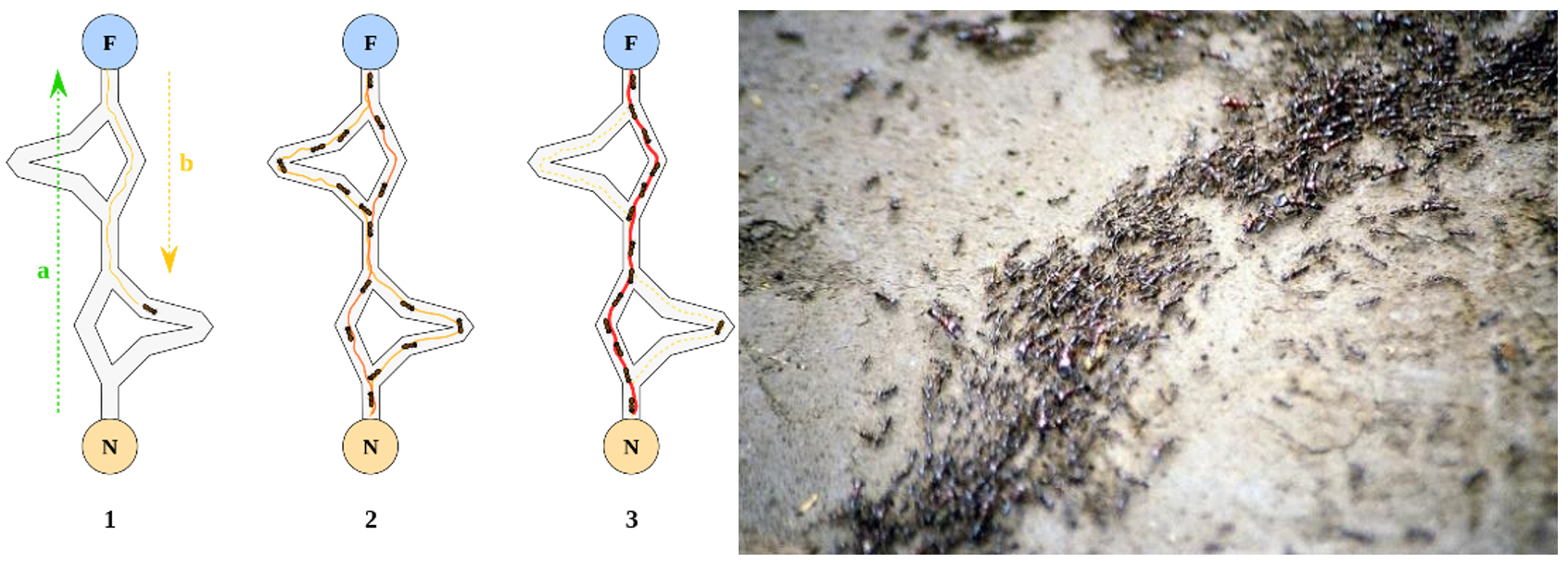
Ant Colony
الگوریتم کلونی مورچه الهام گرفته شده از مطالعات و مشاهدات روی کلونی مورچه هاست. این مطالعات نشان داده که مورچهها حشراتی اجتماعی هستند که در کلونیها زندگی میکنند و رفتار آنها بیشتر در جهت بقاء کلونی است تا در جهت بقاء یک جزء از آن. یکی از مهمترین و جالبترین رفتار مورچهها، رفتار آنها برای یافتن غذا است و به ویژه چگونگی پیدا کردن کوتاهترین مسیر میان منابع غذایی و آشیانه.
این نوع رفتار مورچهها دارای نوعی هوشمندی تودهای است که اخیراً مورد توجه دانشمندان قرار گرفته است در دنیای واقعی مورچهها ابتدا بهطور تصادفی به این سو و آن سو میروند تا غذا بیابند. سپس به لانه بر میگردند و ردّی از فرومون (Pheromone) به جا میگذارند. چنین ردهایی پس از باران به رنگ سفید در میآیند و قابل رویت اند.
مورچههای دیگر وقتی این مسیر را مییابند، گاه پرسه زدن را رها کرده و آن را دنبال میکنند. سپس اگر به غذا برسند به خانه بر میگردند و رد دیگری از خود در کنار رد قبل میگذارند؛ و به عبارتی مسیر قبل را تقویت میکنند. فرومون به مرور تبخیر میشود که از سه جهت مفید است:
باعث میشود مسیر جذابیت کمتری برای مورچههای بعدی داشته باشد. از آنجا که یک مورچه در زمان دراز راههای کوتاهتر را بیشتر میپیماید و تقویت میکند هر راهی بین خانه و غذا که کوتاهتر (بهتر) باشد بیشتر تقویت میشود و آنکه دورتر است کمتر.
● اگر فرومون اصلاً تبخیر نمیشد، مسیرهایی که چند بار طی میشدند، چنان بیش از حد جذّاب میشدند که جستجوی تصادفی برای غذا را بسیار محدود میکردند.
● وقتی غذای انتهای یک مسیر جذاب تمام میشد رد باقی میماند.
لذا وقتی یک مورچه مسیر کوتاهی (خوبی) را از خانه تا غذا بیابد بقیه مورچهها به احتمال زیادی همان مسیر را دنبال میکنند و با تقویت مداوم آن مسیر و تبخیر ردهای دیگر، به مرور همه مورچهها هم مسیر میشوند. هدف الگوریتم مورچهها تقلید این رفتار توسط مورچههایی مصنوعی ست که روی نمودار در حال حرکت اند. مسئله یافتن کوتاهترین مسیر است و حلالش این مورچههای مصنوعی اند.
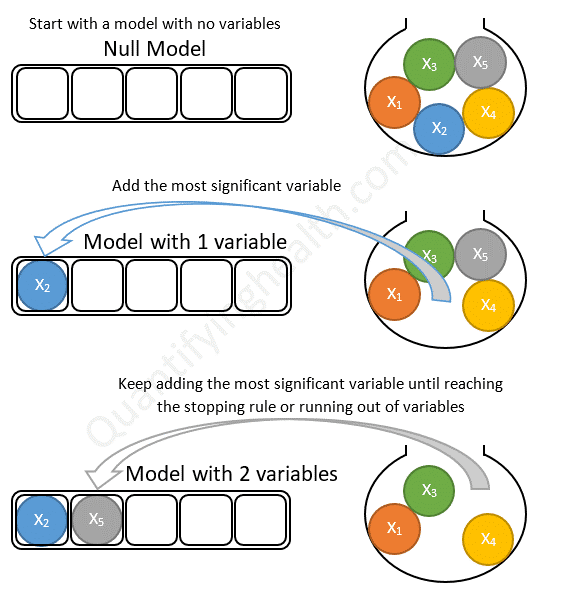
رویکرد Forward Selection
- در این رویکرد، ابتدا مدل اولیه بدون هیچکدام از ویژگی ها در نظر گرفته می شود. سپس در گام بعدی ویژگی دارای بیشترین ارتباط با فیلد هدف وارد مدل می شود و بهبود کیفیت مدل ارزیابی می شود.
- در گام بعدی به شرط حضور ویژگی اول، بهترین ویژگی دوم از نظر ارتباط، به مدل اضافه شده و کیفیت مدل بررسی می شود.
- این گام ها تا شرط توقف (معنادار نبودن ارتباط ویژگی های باقیمانده) و یا ورود تمام ویژگی ها ادامه می یابد.
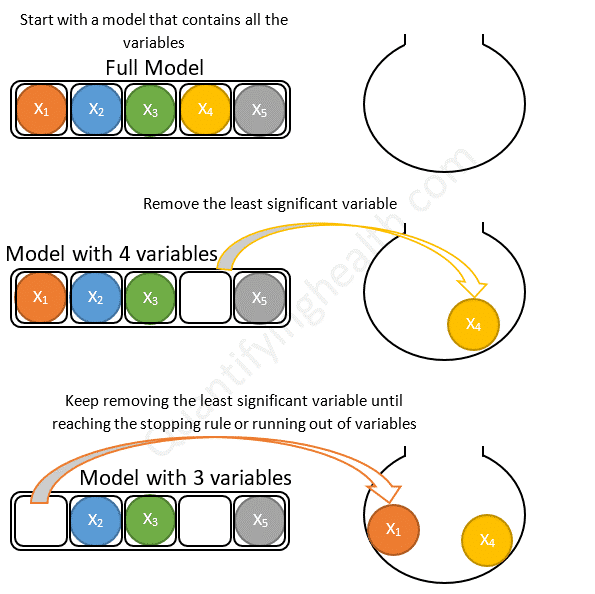
رویکرد Backward Elimination
- در این رویکرد، ابتدا مدل اولیه شامل تمام ویژگی ها در نظر گرفته می شود.
- سپس در گام بعدی ویژگی دارای کمترین ارتباط با فیلد هدف حذف می شود و معنادار نبودن کاهش کیفیت مدل ارزیابی می شود.
- در گام بعدی ضعیف ترین ویژگی دوم از نظر ارتباط، از مدل حذف شده و کیفیت مدل بررسی می شود.
- این گام ها تا شرط توقف (معنادار بودن ارتباط ویژگی های باقیمانده) و یا خروج تمام ویژگی ها ادامه می یابد.
رویکرد Step-wise Selection (Bidirectional Elimination)
این رویکرد به صورت هیبریدی از دو رویکرد قبل استفاده می شود. بدین صورت که در گام اول، یک ویژگی بر اساس رویکرد Forward وارد مدل می شود و در گام دوم بر اساس شرایط رویکرد Backward امکان حذف آن از مدل مورد بررسی قرار می گیرد.
این گام ها تا جایی که ویژگی جدیدی شرایط ورود نداشته باشد و هیچکدام از ویژگیها شرایط حذف از مدل را نداشته باشند ادامه پیدا می کند.
روش توکار (Embedded Method)
در این روش انتخاب ویژگی در فرآیند ساخت مدل ادغام شده است. این روش همانند روش فیلتر، سریع بوده و ویژگی های مرتبط با مسئله را شناسایی می کند و مانند روش بسته بند، با بررسی ویژگی ها در کنار هم از افزونگی داده ها جلوگیری می کند و با تعیین تعداد بهینه از ویژگی های موثر از بیش برازش شدن مدل نیز جلوگیری می کند.
استفاده از این روش در مدلسازی با ابعاد بالا و تعداد ویژگی های زیاد منجر به ساخت مدلهای تنک (Sparse Models) می شود.
جزئیات این روش و متدهای آن در مباحث پیشرفته کورس یادگیری ماشین پوشش داده می شود.
Lasso regression or L1 regularization
Ridge regression or L2 regularization
Elastic nets or L1/L2 regularization