
عبارت بیگ دیتا به اصطلاحی رایج تبدیل شده است. قبلا در این پست بیان کردیم که بیگ دیتا چیست و چه کاربردهایی دارد. و در این پست به مقایسه برخی از داده های بسیار بزرگ پرداختیم.
با وجود اینکه در روزگار ما حجم عظیمی از بیگ دیتا وجود دارد و همچنان در حال تولید شدن است، اما همچنان بزرگترین دادههای بزرگ اطراف ما دادههای ژنومی هستند.
دادههای ژنومی به اطلاعات ژنتیکی درون ۳ میلیارد باز در انسان اشاره دارد. توالی ژنومی بدن برای اهداف مختلفی خوانده میشود، مانند آزمایشهایی برای تجویز درمانهای سفارشی، تعیین خطر ژنتیکی بیماری و یا تشخیص بیماریهای ژنتیکی نادر. گفته میشود حجم دادههای ژنومی که به این روش تولید میشود حدود ۲۲۰ میلیون ژنوم (۴۰ اگزابایت) در سال است. این عدد ۴۰ برابر بیشتر از دادههای تولید شده توسط یوتیوب است.
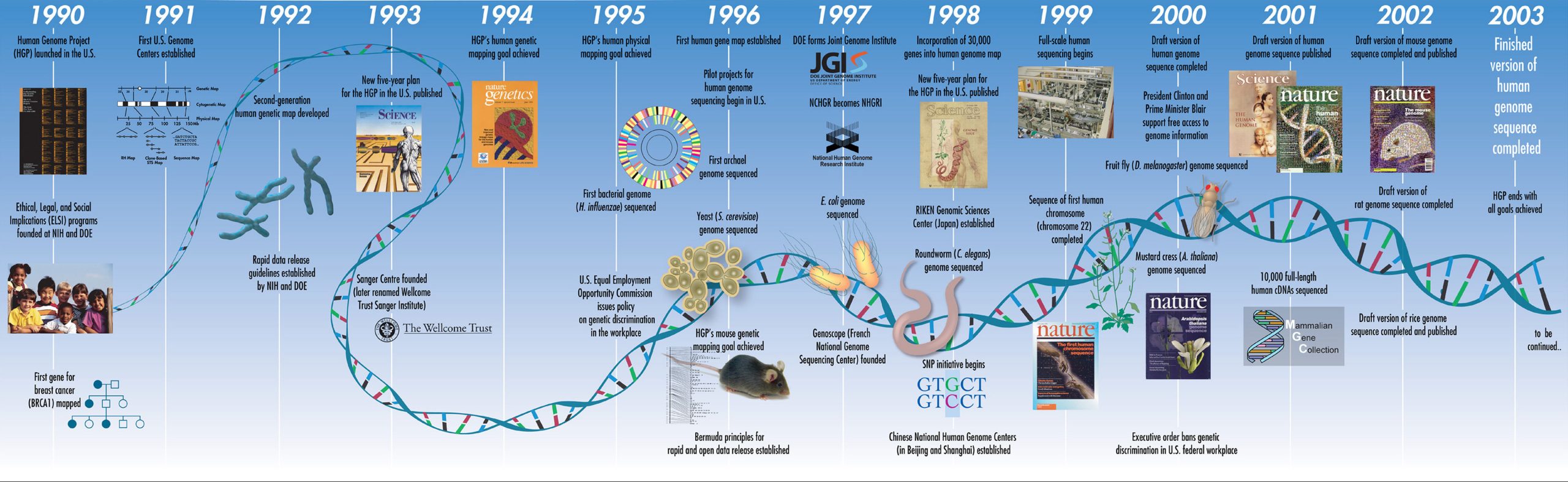
در سال ۲۰۰۳، پروژه ژنوم انسان ۳ میلیارد قطعهای را که پازل بدن انسان را تشکیل میدهند، پیدا کرد. از طریق این پروژه، بشر آیندهای درخشان را ترسیم کرد که در آن همه بیماریها قابل غلبه بودند، اما حل کردن رازهای تک تک ۳ میلیارد قطعه پازل کار آسانی نبود.
با پیشرفت سریع تکنولوژی، هزینه خواندن کل ژنوم فرد به شدت کاهش یافته است و در حال حاضر خواندن کل توالی نوکلئوتیدی فرد حدود ۱۰۰۰ دلار هزینه دارد. با این حال، توالییابی سریع و ارزان، راهحل نهایی نبود. از پایان پروژه ژنوم انسان، بیست سال میگذرد، اما همچنان مشکلاتی وجود دارد. این مشکلات چه هستند؟
۱. زمان محاسبه
خواندن دادههای ژنوم همه ماجرا نیست. پس از آن، باید این دادهها را پردازش کنیم.
در حال حاضر، خواندن ژنوم از موقعیت ۱ تا انتها به طور همزمان امکان پذیر نیست، بلکه ژنوم به قطعات کوتاه حدود ۴۰۰ جفت باز (bp) بریده میشود و هر دو انتها با طول تقریباً ۱۵۰ جفت باز خوانده میشود. این فایلها با نام FASTQ شناخته میشوند.

سپس این فایلهای FASTQ با تراز کردن آنها با توالی مرجع، دوباره به توالیهای بلند مونتاژ میشوند. این فایلها بام (BAM) نامیده میشوند.
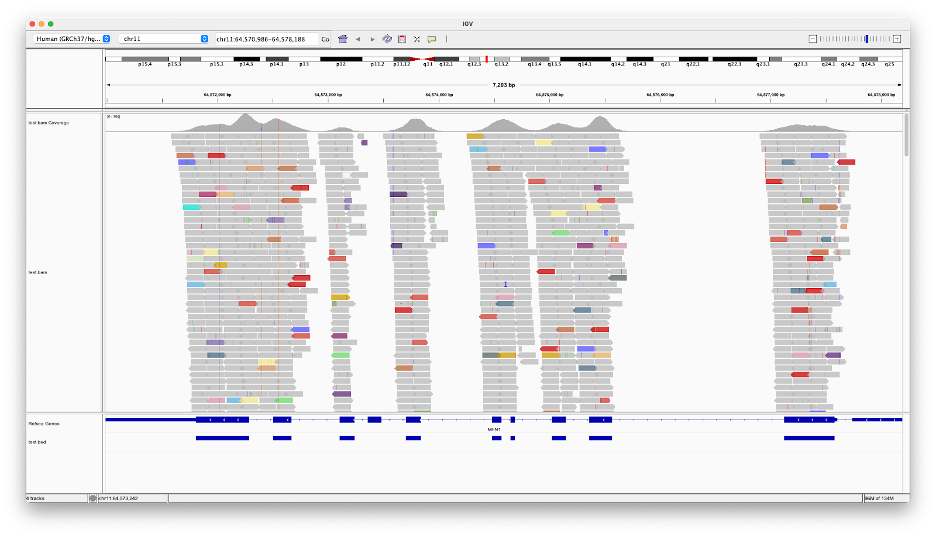
سپس از میان ۳ میلیارد موقعیت در ژنوم، میتوان موقعیتی به نام واریانت (variant) را که با توالی مرجع متفاوت است، یافت.
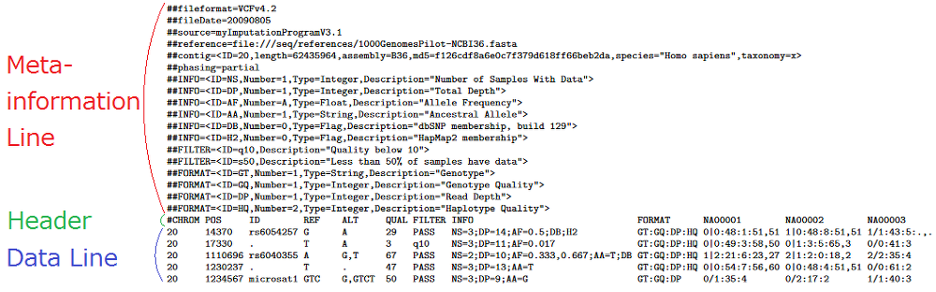
در اینجا، خواندن کل ۳ میلیارد جفت باز ژنوم توالییابی کل ژنوم (WGS) نامیده میشود، خواندن تمام اگزونهای کدکننده پروتئین توالییابی کل اگزوم (WES ) و خواندن فقط موقعیتهای ژنی خاص، توالییابی هدفمند (Target Sequencing) نامیده میشود.
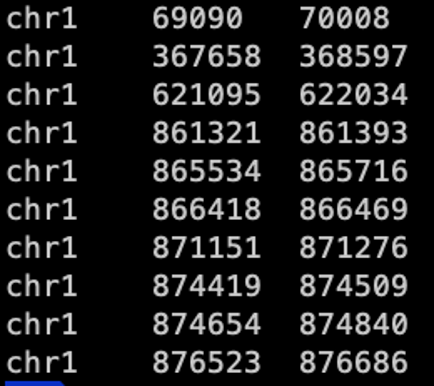
هنگام توالییابی فقط یک ناحیه خاص، فرایند فراخوانی واریانت تنها جهشها (mutation) را در آن ناحیه خاص پوشش میدهد. فایلهایی که به این مناطق خاص اشاره میکنند، فایلهای BED نامیده میشوند.
در فایل VCF توالییابی کل ژنوم (WGS) حدود ۵ میلیون جهش به ازای هر فرد وجود دارد که معادل ۰.۱۶ درصد از کل ۳ میلیارد جفت باز است. اگرچه به آن جهش گفته میشود، اما برخی جهشها از بیرون قابل مشاهده هستند و مشکلی ایجاد نمیکنند، مانند رنگ پوست یا موی انسان، در حالی که برخی جهشها میتوانند باعث بیماری شوند و زندگی را دشوار کنند.

برای ایجاد یک فایل VCF (Variant Call Format) از داده خام کل ژنوم (FASTQ) که با فرمت BAM (Binary Alignment Map) میانی پردازش شده است، حداقل به یک روز کامل (حدود 24 ساعت) زمان بر روی تجهیزات سرور نیاز است. آنالیز این دادهها همچنین میتواند بر روی رایانههای شخصی معمولی که معمولاً استفاده میکنیم انجام شود، اما مشخصات سختافزاری مورد نیاز حداقل ۱۶ گیگابایت رم است و حدود دو هفته طول میکشد!
تجزیه و تحلیل دادههای توالییابی اگزوم (Exome sequencing) که مجموعهای از نواحی اگزون (ناحیه کدکننده پروتئین) است، حدود ۲ ساعت زمان میبرد. این در حالی است که توالییابی اگزوم دادههای کل ژنوم را پوشش نمیدهد و فقط بر روی نواحی کدکننده پروتئین تمرکز دارد.
۲. ذخیرهسازی
هنگام توالییابی دادههای ژنوم یک فرد و استخراج اطلاعات جهش، فایلهای FASTQ، BAM و VCF که قبلاً در مورد آنها صحبت کردیم، تولید میشوند.
با محاسبات ساده، خواندن حداقل ۳۰ بار توالی ۳ میلیارد بازی یک فرد، حدود ۹۰ میلیارد کاراکتر طول میکشد. شکل زیر این را از نظر اندازه فایل کامپیوتری نشان میدهد.
| Type (Mean depth) | FASTQ | BAM | VCF | SUM |
|---|---|---|---|---|
| WES (100x) | 5GB | 8GB | 0.1GB | 13GB |
| WGS (30x) | 80GB | 100GB | 1GB | 180GB |
به طور کلی، یک فیلم با مدت زمان ۱۳۵ دقیقه تقریباً ۳ گیگابایت است. بنابراین، میتوان گفت که ژنوم یک فرد تقریباً به اندازه ۶۰ فیلم است.
حالا چه میشود اگر آن را ذخیره کنیم؟ میتوانید یک هارد دیسک اکسترنال ۱ ترابایتی خریداری کنید و دادههای ژنوم حدود ۵ نفر را ذخیره کنیم.
اما در مورد فضای ابری چطور؟ هزینه فضای ابری AWS (سرویسهای وب آمازون) که به طور گسترده استفاده میشود، حدود ۰.۰۲۵ دلار به ازای هر گیگابایت در ماه است. اگر برای ژنوم یک نفر محاسبه کنید، ماهانه ۴.۵ دلار هزینه دارد، اما اگر ۱۰۰۰ نفر را در نظر بگیرید، حداقل تعداد نمونه در یک جمعیت برای فیلتر کردن واریانتهای رایج، حتی با هزینه ماهیانه ۴۵۰۰ دلار برای صرفاً ذخیرهسازی، مقدار قابل توجهی است.
| Provider | Service name | Price | Price per one WGS sample |
|---|---|---|---|
| AWS | S3 Standard | $0.025/GB | $4.5 |
| Google cloud | Cloud storage | $0.023/GB | $4.14 |
| Microsoft Azure | Premium | $0.15/GB | $27.0 |
۳. انتقال داده ها
به طور کلی، وقتی می گوییم از شبکه سریع استفاده می کنیم، منظورمان اینترنت گیگابیتی است. اینترنت گیگابیتی به سرعتی در حدود ۱ گیگابیت (گیگابایت) در ثانیه یا ۱۲۵ مگابایت بر ثانیه هنگام تبدیل به بایت هایی که برای ما آشنا هستند، اشاره دارد. این به حداکثر سرعت تئوری اشاره می کند.
برای راحتی، فرض کنیم به حداکثر سرعت دست یافته ایم و سرعت انتقال را با استفاده از داده های ژنوم ذکر شده در بالا محاسبه کنیم. با حجم FASTQ + BAM + VCF = ۱۸۰ گیگابایت، زمان انتقال آن ۱۸۰ گیگابایت / ۱۲۵ مگابایت بر ثانیه = ۱۴۴۰ ثانیه = ۲۴ دقیقه طول می کشد.

در نگاه اول، ممکن است به نظر زمان کمی برسد. اما در واقع، شبکه ای که ما استفاده می کنیم، سرعت را در زمان ترافیک سنگین تنظیم می کند. به همین منظور، محدودیت سرعت (QoS) اعمال می شود و این ترافیک بسته به محصول، حدود ۱۰۰ گیگابایت است. اگر ۱۰۰ گیگابایت تمام شود، به ۱۰۰ مگابایت بر ثانیه کاهش می یابد که ۱/۱۰ اینترنت گیگابیتی است. یعنی، ۱۸۰ گیگابایت / ۱۲۵ مگابایت بر ثانیه + ۸۰ گیگابایت / ۱۲.۵ مگابایت بر ثانیه = ۲ ساعت.
اگر تعداد نمونه ها بیش از یک باشد، نمونه دوم باید با سرعت ۱۰۰ مگابایت بر ثانیه دریافت شود، بنابراین ۱۸۰ گیگابایت / ۱۲.۵ مگابایت بر ثانیه = ۴ ساعت طول می کشد. نه تنها دریافت داده مشکل است، بلکه ارسال آن نیز مشکل است. ۱۸۰ گیگابایت با یک فایلی که به سادگی به عنوان پیوست ایمیل ارسال می شود بسیار متفاوت است. به اشتراک گذاشتن این داده ها با همکاران چالش برانگیز است، بنابراین در عمل، داده ها اغلب در یک هارد دیسک اکسترنال ذخیره می شوند و به طور کامل منتقل می شوند.
۴. تفسیر واریانت
خواندن، ذخیره و انتقال داده های ژنوم دشوار است، اما مهمترین مرحله برای تجزیه و تحلیل داده های ژنوم همچنان باقی مانده است. خواندن داده های خام و تجزیه و تحلیل آن روی یک کامپیوتر شخصی دشوار یا غیرممکن است. هر چه مشخصات سرور برای تجزیه و تحلیل بهتر باشد، سریعتر خواهد بود، اما به طور کلی، اگر از یک CPU ۴۰ رشته ای و ۲۵۰ گیگابایت رم استفاده کنید، حدود ۲۴ ساعت طول می کشد تا داده های واریانت را از داده های کل ژنوم ایجاد کنید.
اگر از رایانش ابری استفاده می کنید، همانطور که در بالا نشان داده شد، می توانید آن را محاسبه کنید. VCF خود حاوی اطلاعاتی در مورد حدود ۵ میلیون جهش است و در میان این جهش های متعدد، باید با توجه به اطلاعات بالینی، جهشی را پیدا کرد که با بیماری مرتبط باشد.
| Provider | Service name* | CPU (thread) | RAM (GB) | Price | Price per one WGS sample analysis (24h)** |
|---|---|---|---|---|---|
| AWS | r5.8xlarge | 32 | 256 | $2.016/h | $48.384 |
| Google Cloud | c2-standard-60 | 60 | 240 | $2.51/h | $60.24 |
| Microsoft Azure | E32a v4 | 32 | 256 | $3.712/h | $89.088 |
نتیجهگیری
همانطور که قبلاً دیدیم، در برخورد با حجم زیادی از داده در یک محیط محاسباتی کوچک، مشکلات زیادی وجود دارد. کسانی که داده های ژنتیکی را از شرکتهای توالییابی دریافت کردهاند، میدانند که یافتن اطلاعات معنیدار در خود دادههای خام ژنتیکی کار آسانی نیست. بنابراین، برای تفسیر دادههای ژنتیکی، توصیه میکنیم گزارشی از شرکتی دریافت کنید که تجربه زیادی در مدیریت دادهها، بهروزرسانیروزانه پایگاه داده خود با آخرین دادهها و تنظیم دقیق الگوریتم تشخیصی داشته باشد.
منبع: سایت 3billion.io