داده های پرت:
داده های پرت الزاما داده های اشتباه نیستند بلکه از توزیع آماری بدنه اصلی داده ها پیروی نمی کنند.
داده های پرت اغلب سه یا بیش از سه واحد انحراف معیار (± 3SD) از میانگین مربوط به خودشان فاصله دارند که از مشکلات احتمالی در ابزار اندازه گیری، شیوه ثبت یا ضبط پاسخ ها یا عضویت شرکت کنندگان در جامعه های که فرض می شود از آن نمونه گیری شده است، ناشی می شود. حضور داده های پرت می تواند نتایج تحلیل را به گونه های نامطلوب تحت تأثیر قرار دهد(تحریف کند). به همین دلیل بیشتر متخصصان پیشنهاد می کنند که اندازه های پرت قبل از تحلیل داده ها باید حذف شوند.
به طور مثال:
- مقدار درآمد ثبت شده 60 میلیونی در یک گروه تصادفی از کارمندان بانک
- وجود یک لکه متمایز در تصویر سی تی اسکن ریه
- سن 48 سال در داده های دانشجویان ترم اول کارشناسی

داده های پرت به علت فاصله زیاد با سایر داده ها، در اغلب الگوریتم ها منجر به ایجاد اختلال در شناسایی الگوها می شوند. بنابراین شناسایی و برخورد مناسب با آنها از اهمیت بالایی برخوردار می باشد.
انواع داده های پرت
داده های پرت را می توان در دو دسته داده های پرت تک متغیری و داده های پرت چند متغیری تقسیم کرد:
1- داده های پرت تک متغیره: عمدتا با استفاده از روش های توصیفی آماری و مفاهیم توزیع آماری روی یک ویژگی مقادیر پرت شناسایی میشوند. داده های پرت تک متغیری مربوط به یک متغیر می شوند.
به عنوان مثال وقتی که در یک پژوهش دانشجویی در زمینه میزان رضایت مردم از عملکرد شهرداری تهران؛ ما در متغیر سن افراد با عدد 150 روبرو می شویم!، به احتمال زیاد با داده پرت مواجه شده ایم. چرا که می دانیم احتمال وجود فردی با چنین سن و سالی بسیار بعید است!
و یا وقتی که در متغیر درآمد، شخصی درآمد ماهانه خود را از یک کار تمام وقت 65 هزار تومان اعلام می کند و یا وقتی که در پاسخ سوالی که از فرد می پرسیم تا چه اندازه به آینده امیدوار است و او باید میزان رضایت خود را از عدد 1 (به معنای خیلی کم) تا عدد 5 (به معنی خیلی زیاد) اعلام کند، در فایل داده ها با عدد 6 روبرو می شویم (به دلیل اشتباه در ورود داده)، همگی نشان از وجود داده های پرت تک متغیری دارد که نخست باید آنها را شناسایی کرد و سپس در مورد آنها چاره ای اندیشید.
شناسایی داده پرت تک متغیره:
بر اساس توزیع نرمال (روش تک متغیره – پارامتری)
این روش، در حالت هایی که تعداد فیلد های کیفی کم باشد کاربرد زیادی دارد.
اگر توزیع داده ها از توزیع نرمال فاصله خاصی نداشته باشد می توان از این روش استفاده نمود.
این روش از این شرایط استفاده می کند که وقتی توزیع نرمال باشد 99.7% داده ها در بازه σ±3 µ (یا به عبارت دیگر شش سیگما) قرار دارند. یعنی اگر به عنوان مثال 1000 تا داده داشته باشیم 997 تا از این داده ها در این بازه قرار میگیرند و 3 تای آن در خارج این بازه قرار خواهند گرفت.
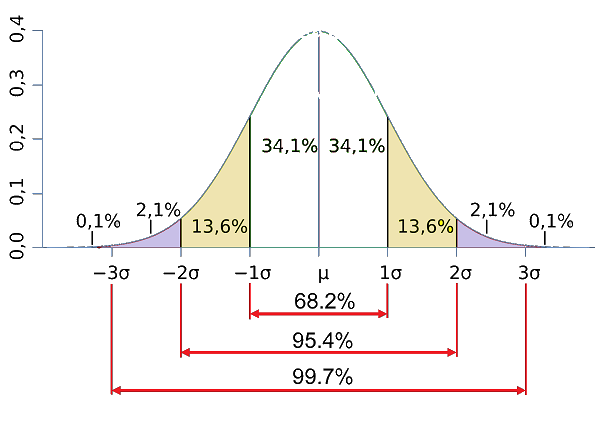
در نتیجه اگر داده ای بیشتر یا کمتر از 3 سیگما بود به آن داده پرت یا outlier گفته می شود. همچنین به داده هایی که به اندازه 5 سیگما با بدنه اصلی داده ها اختلاف داشته باشند اکستریم یا غایی گفته می شود.
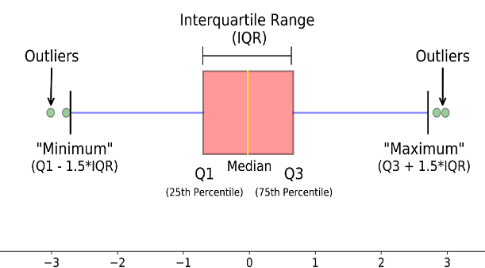
در صورتیکه توزیع داده ها نرمال نباشد از روش دامنه میان چارکی استفاده می شود.
بر اساس دامنه میان چارکی (روش تک متغیره- ناپارامتری)
به سمت جلو رفته و از Q1 به اندازه 1.5 IQR عقب رفته و داده هایی که خارج از این دو بازه باشند داده پرت گفته می شود.
همچنین به داده هایی که به اندازه 3 IQR از Q3 جلوتر باشند و یا 3 IQR از Q1 عقب تر باشند داده اکستریم گفته می شود.
- این روش نیز برای داده هایی که فیلد های کیفی آن کم باشد و تعداد داده های پرت آن نیز زیاد نباشد (بیش از 2% نباشد) کاربرد دارد و به پیش فرض توزیع نرمال نیاز ندارد.
2– داده های پرت چند متغیره: عمدتا با استفاده از روش های تحلیل چند متغیره و در فضای -nبعدی رکوردهای پرت شناسایی میشوند.
شناسایی داده های پرت چند متغیره:
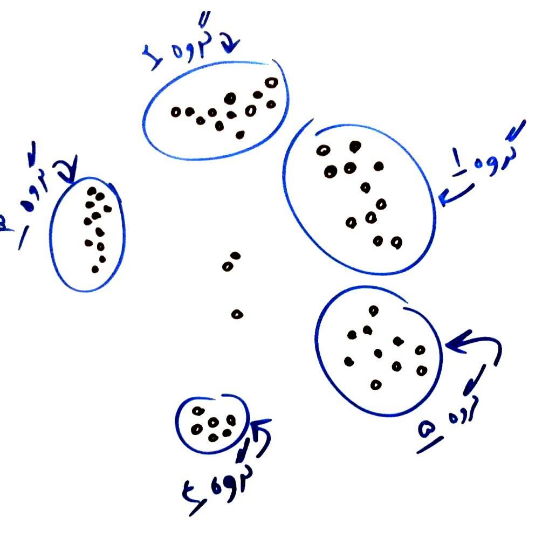
شناسایی داده های پرت چند متغیره بر اساس خوشه بندی
در این روش باید داده های مشابه را گروه بندی کرد و داده هایی که در هیچ یک از خوشه ها قرار نمی گیرند داده پرت فرض خواهند شد.
نقاط ضعف و قوت
- قابل استفاده در داده های با تعداد ویژگی های زیاد
- استفاده از الگو ها و روابط بین ویژگی ها در تشخیص رکوردهای پرت
- پیچیدگی اجرایی و نیاز به دانش در خصوص بهینه سازی پارامترها و اجرای الگوریتم ها
روش های برخورد با داده های پرت:
- برخورد با داده های پرت به هدف مسئله و موضوع زمینه آن وابسته است.
- در برخی از مسائل، هدف اصلی کشف الگوهای نادر و آنومالی ها می باشد.
بطور مثال:
- مدل تشخیص غده بدخیم در تصاویر پزشکی
- شناسایی الگوهای تخلف در پرونده های خسارتی یک شرکت بیمه
- ولی در اغلب مسائل به دنبال الگوی بدنه اصلی داده ها هستیم و وجود داده های پرت منجر به کاهش کارایی مدلها می شوند.
روش های برخورد با مقادیر پرت
روش جایگزینی
یکی از رایج ترین روشهای اصلاح در مقادیر پرت، جایگزینی مقادیر پرت با مقادیر آستانه ای قابل قبول در توزیع داده ها می باشد.
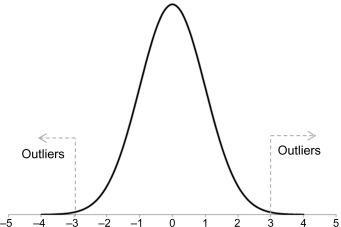
به طور مثال در تصویر روبرو، با استفاده از روش مبتنی بر توزیع نرمال، کلیه مقادیر خارج از محدوده سه انحراف معیار، با نقاط آستانه ای جایگزین می شوند. این تغییر منجر به تغییر در توزیع داده میشود.
بنابراین با تغییر پارامترهای توزیع، تکرار این روش می تواند مجددا داده های دیگری را به عنوان نقاط پرت شناسایی کند.
روش حذف
روش حذفی در برخورد با مقادیر پرت عموما به معنای پاک کردن مقدار پرت یک ویژگی می باشد.
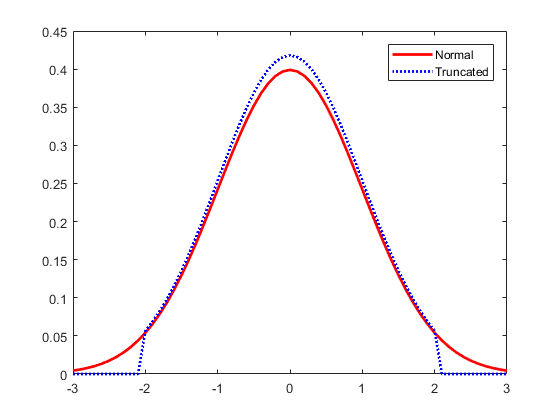
بطور مثال در تصویر روبرو، با استفاده از روش مبتنی بر توزیع نرمال، کلیه مقادیر خارج از محدوده دو انحراف معیار، حذف میشوند. این تغییر منجر به تغییر در توزیع داده میشود.
بنابراین با تغییر پارامترهای توزیع، تکرار این روش می تواند مجددا داده های دیگری را به عنوان نقاط پرت شناسایی کند
حفظ رکوردهای پرت
این استراتژی در مسائلی از نوع شناسایی آنومالی ها که هدف اصلی می باشد بکار میرود. در واقع هدف کشف الگوی رکوردهای پرت است.
حذف رکوردهای پرت
در اغلب مسائل رایج ترین استراتژی در مواجهه با رکوردهای پرت، حذف آنها پس از بررسی علل و چرایی آنهاست.
جداسازی رکوردهای پرت و مدلسازی جداگانه
در مواقعی که تعداد رکوردهای پرت شناسایی شده به اندازه کافی بزرگ باشد، در صورت اهمیت موضوع می توان بصورت جداگانه اقدام به مدلسازی بر روی آنها کرد.