
یکپارچه سازی منابع مختلف داده یکی از اولین اقدامات در جهت حل مسئله و پیشبرد فرآیند داده کاوی می باشد. زیرا عموما داده های مورد نیاز در حل یک مسئله در منابع متفاوت جداگانه ثبت و نگهداری می شوند.
توجه: بایستی توجه شود کلیه روش ها و اقداماتی که تاکنون جهت آماده سازی داده ها گفته شده پس از یکپارچه سازی داده ها انجام می شود.
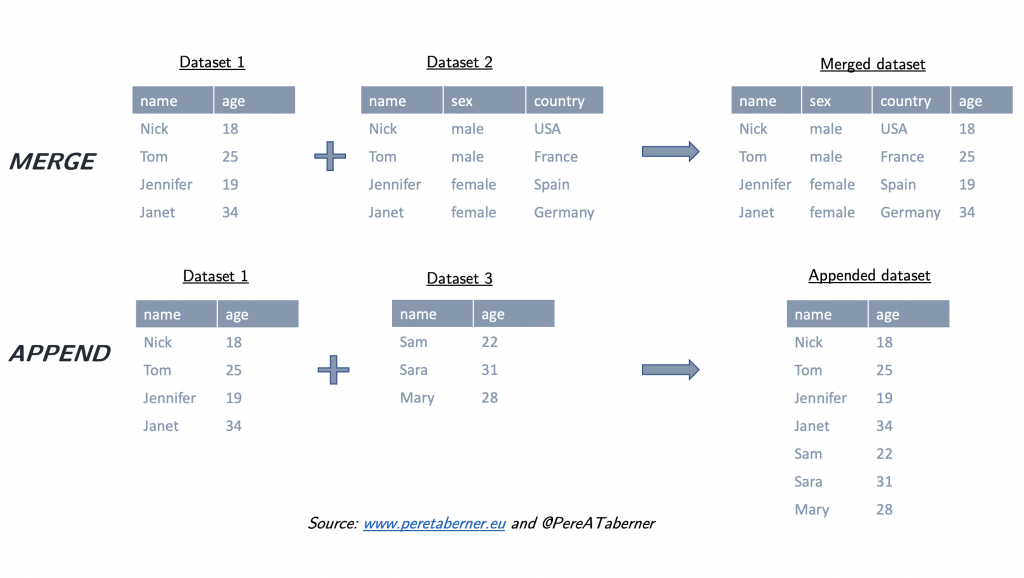
چسباندن داده ها (Append)
زمانی که از گزینه Append استفاده میکنیم به این معنی است که دو دیتاست (یا بیشتر) با شرایط زیر صرفا به هم متصل میشوند و تبدیل به یک دیتاست میشوند:
● ردیف های تمام دیتاست ها به هم متصل میشوند. به این معنی که اگر یک دیتاست 50 ردیف و دیتاست دیگر 100 ردیف داشته باشد، حاصل استفاده از Append برای این دو، 150 ردیف خواهد داشت.
● تعداد ستون ها برای هرکدام از دیتاست ها بعد از عملیات Append تغییر نخواهد داشت.
ادغام کردن داده ها (Merge)
یکی دیگر از شیوه های ترکیب دیتاست ها، استفاده از گزینه Merge یا ادغام دیتاست هاست. در نتیجه ادغام نیز یک دیتاست واحد ایجاد خواهد شد، البته با شرایط زیر:
● برای ادغام (Merge) دو دیتاست می بایست یک معیار مشترک بین دو دیتاست وجود داشته باشد.
● تعداد ردیف ها، بستگی به معیار مشترک بین دیتاست ها خواهد داشت.
انواع روش های Merge
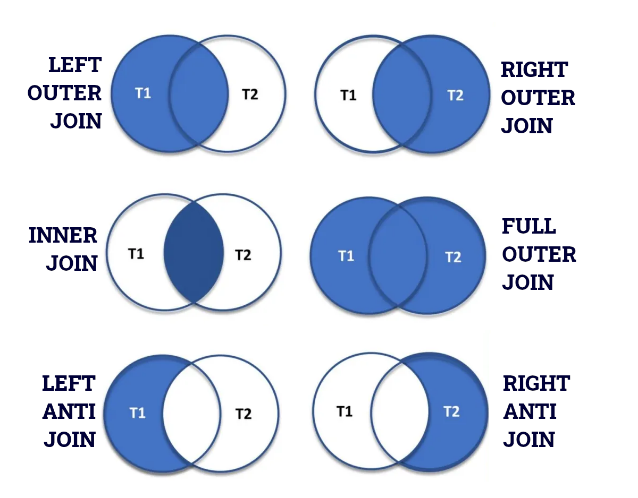
یه نکته کلی که در انواع روش های مرج کردن همواره برقرار است این است که وقتی که 2 تا دیتاست را با هم مرج می کنیم، اگر ریزدانگی آن دیتاست ها با هم متفاوت باشد آنگاه دیتای مرج شده پایین ترین سطح ریزدانگی را برای ما حفظ می کند.
توضیح انواع روش های Merge
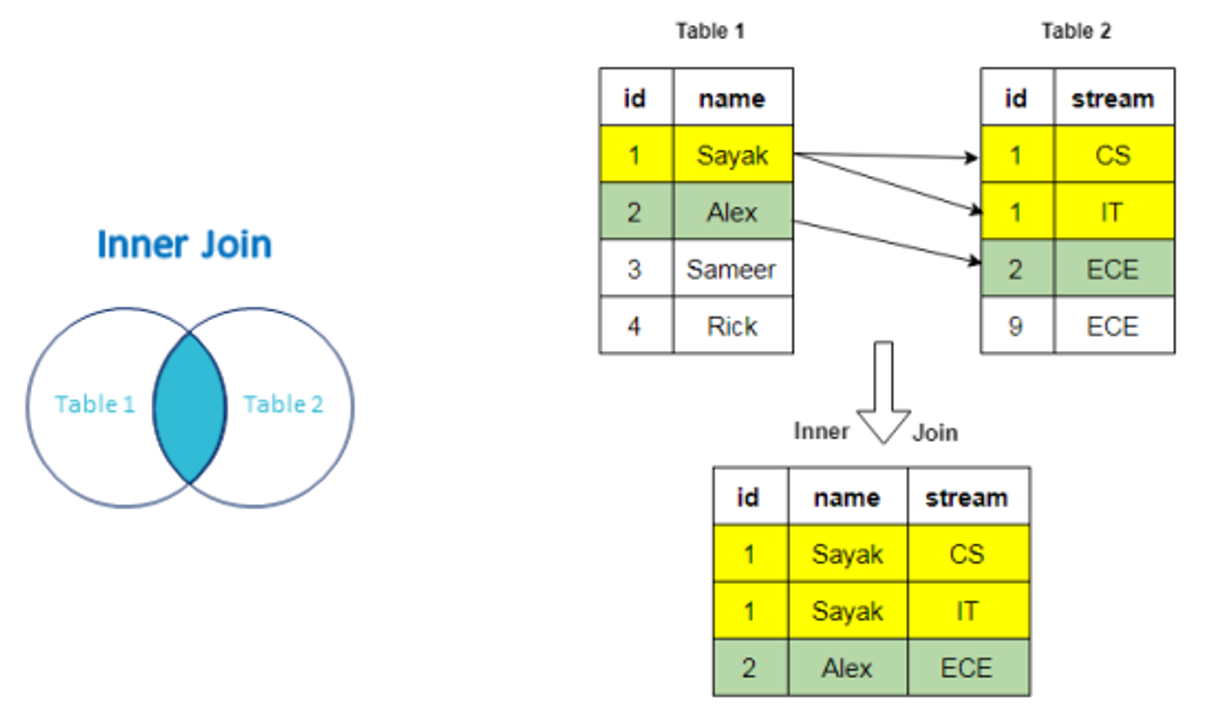
روش اشتراکی یا Inner Join
همه ID هایی که هم در دیتاست 1 و هم در دیتاست 2 باشند را در نظر می گیرد.
اگر فرض کنیم جدول 1 لیست کد ملی افرادی است ک به کرونا مبتلا شده اند و جدول 2 لیست همه افرادی است که تحت پوشش بیمه هستند. در این صورت افرادی که هم کرونا گرفته اند و هم بیمه داشته اند به این صورت خواهد بود:
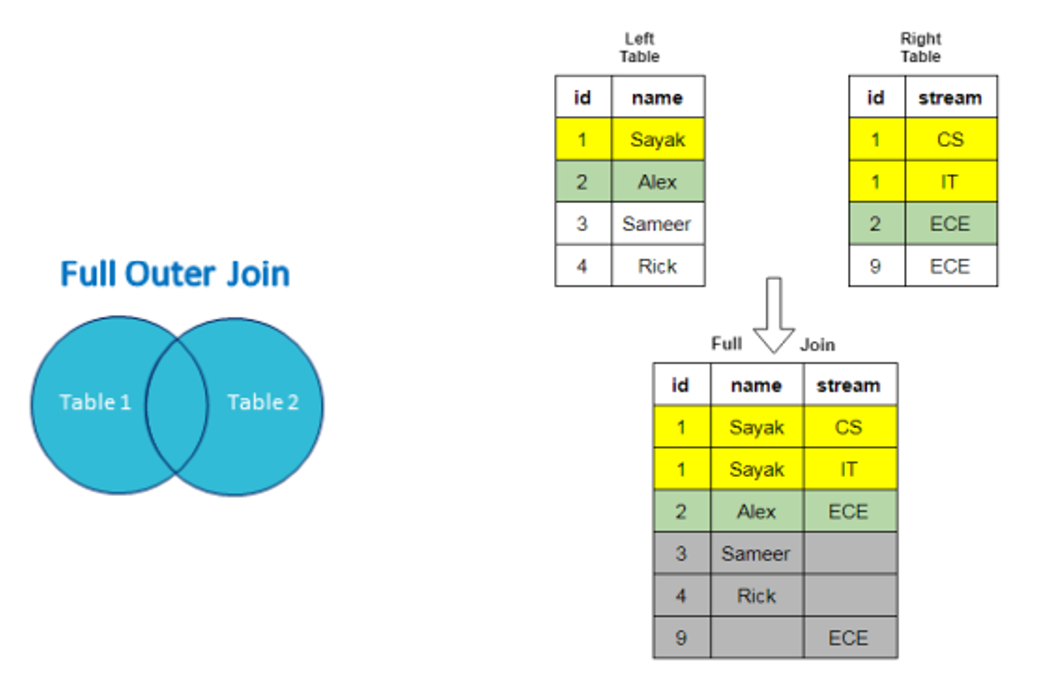
روش اجتماع یا Full outer join
همه ID های موجود در دستاست اول و دوم را با هم در نظر می گیرد.
در مثال ذکر شده در روش قبل، همه افرادی که یا کرونا گرفته اند یا بیمه داشته اند به این صورت خواهد بود:
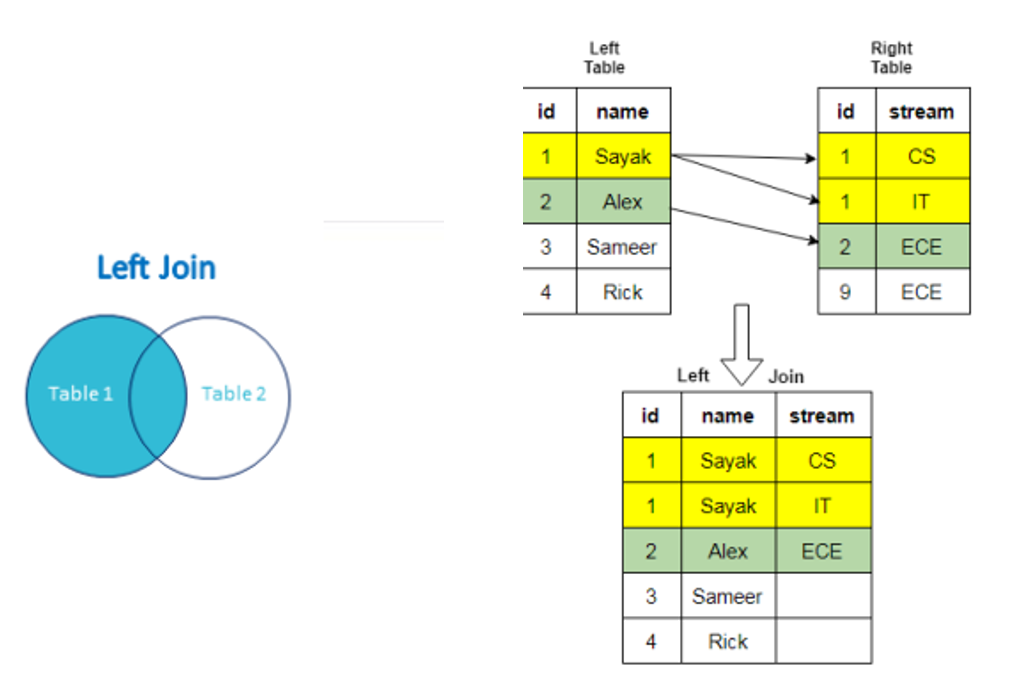
روش Left join
در این روش، دیتاست اول را به عنوان دیتاست اصلی در نظر می گیرد و مرج را فقط برای دیتاهایی انجام می دهد که در دیتاست اول هستند.
در همان مثال، افرادی که به کرونا مبتلا شده اند و بیمه نیز دارند به این صورت است.
روش Right join
این روش مانند حالت قبلی است با این تفاوت که دیتاست دوم را به عنوان دیتاست اصلی در نظر می گیرد و مرج را فقط برای دیتاهایی انجام می دهد که در دیتاست دوم هستند.
باز هم برای همان مثال مذکور، بخشی از افراد تحت پوشش بیمه که دچار کرونا شده اند به این صورت است:

روش Anti join
در این حالت اگر فرض کنید دیتاست اصلی، دیتاست اول باشد، پس از مرج کردن ID هایی را خواهیم داشت که در دیتاست اول هستند ولی در دیتاست دوم نیستند. شبیه حالت A-B
در مثال فرض ما، افرادی که به کرونا مبتلا شده اند اما بیمه نداشتند به این صورت خواهد بود:
