این متن بخش دوم مقاله کاربرد علم داده در ژنتیک و ژنومیک است. بنابراین لازم است که پیش از مطالعه، بخش اول این مقاله را مطالعه نمایید.
کاربرد علم داده در ژنتیک و ژنومیک
در حالی که علم داده نویدبخش پیشبرد قابل توجه تحقیقات در ژنتیک و ژنومیک است، با چالشها و محدودیتهای خاص خود نیز همراه است. یکی از چالشهای اصلی، حجم عظیم و پیچیدگی دادههای ژنتیکی است که محققان با آن روبرو هستند. مجموعه دادههای ژنومی اغلب حجیم بوده و از میلیاردها جفت باز تشکیل شدهاند که پردازش و تحلیل مؤثر آنها میتواند دلهرهآور باشد.

چالش دیگر مربوط به کیفیت و دقت خود دادهها است. دادههای ژنتیکی به دلیل عوامل مختلفی مانند خطاهای تعیین توالی یا آلودگی نمونه، میتوانند مستعد خطا یا ناسازگاری باشند. اطمینان از صحت و یکپارچگی داده برای به دست آوردن بینشهای معنادار حیاتی است.
علاوه بر این، ملاحظات اخلاقی در هنگام کار با اطلاعات ژنتیکی نقش مهمی ایفا میکند. هنگام برخورد با دادههای حساس ژنومی، نگرانیهای مربوط به حفظ حریم خصوصی مطرح میشود، چرا که در صورت عدم مدیریت صحیح، هویت افراد ممکن است در معرض خطر قرار گیرد. دستیابی به تعادل بین استفاده از اطلاعات ارزشمند ژنتیکی برای اهداف تحقیقاتی و احترام به حقوق حریم خصوصی افراد، چالشی دائمی است.
علاوه بر این چالشها، درک فعلی ما از فرآیندهای پیچیدهی بیولوژیکی زمینهای در ژنتیک و ژنومیک نیز محدودیتهایی دارد. با وجود پیشرفتهای صورتگرفته در الگوریتمهای یادگیری ماشین، پیشبینی نتایج فنوتیپی (ویژگیهای قابل مشاهده) صرفاً بر اساس اطلاعات ژنومی، به دلیل تعاملات پیچیدهی ژن با ژن، عوامل محیطی، تغییرات اپیژنتیکی و غیره، همچنان چالشبرانگیز است.

علاوه بر این، اطمینان از قابلیت تکرار و شفافیت در گردش کارهای تحلیل محاسباتی، مانع دیگری است که نیاز به توجه دارد. تکرار نتایج به دست آمده از یک مطالعه توسط سایر محققان برای اعتبار علمی باید امکانپذیر باشد؛ با این حال، تغییرات در ابزارهای نرمافزاری مورد استفاده یا روشهای غیرقابلتکرار، ممکن است تلاشهای تکرارپذیری را با مشکل مواجه کند.
برای غلبه بر این چالشها و پرداختن مؤثر به محدودیتهای آنها، همکاری بین رشتهای میان دانشمندان رشتههای مختلف مانند علوم رایانه، آمار، زیستشناسی و پزشکی ضروری است. تقویت تبادل ایدهها بین رشتههای مختلف به طور قابل توجهی روند پیشرفت را تسریع خواهد کرد.
به طور کلی، علم داده پتانسیل فوقالعادهای را ارائه میدهد، اما برای درک کامل تأثیر آن بر تحقیقات ژنتیک و ژنومیک، باید با دقت از این چالشها عبور کند.
چشماندازهای آینده و تأثیر بر مراقبتهای بهداشتی
آیندهی علم داده در ژنتیک و ژنومیک سرشار از نوید است. با پیشرفت فناوری، توانایی ما برای جمعآوری و تحلیل حجم عظیمی از دادههای ژنتیکی نیز افزایش مییابد. با داشتن این ثروت اطلاعاتی در دسترس، پتانسیل بهبود نتایج مراقبتهای بهداشتی نامحدود میشود.

یک حوزه که علم داده پتانسیل تأثیرگذاری قابل توجهی در آن را دارد، پزشکی شخصیسازیشده است. دانشمندان با کاوش دادههای ژنومی میتوانند جهشها یا تغییرات ژنتیکی خاصی را شناسایی کنند که ممکن است در استعداد فرد برای ابتلا به بیماریهای خاص یا تأثیر آنها بر پاسخ به درمان نقش داشته باشد. این دانش به پزشکان اجازه میدهد تا مداخلات پزشکی را بر اساس ترکیب ژنتیکی منحصر به فرد هر فرد تنظیم کنند که منجر به درمانهای مؤثرتر و هدفمندتری میشود.
یکی دیگر از چشماندازهای هیجانانگیز، استفاده از الگوریتمهای یادگیری ماشین در تشخیص اختلالات ژنتیکی نادر است. محققان با آموزش الگوریتمها روی مجموعه دادههای بزرگی که هم شامل اطلاعات بالینی و هم توالیهای ژنومی است، میتوانند مدلهایی را توسعه دهند که قادر به شناسایی دقیق تغییرات ایجادکنندهی بیماری باشند. این امر میتواند به تشخیص زودهنگامتر، پیشآگهی بهتر و در نهایت نتایج بهتر برای بیماران منجر شود.

علاوه بر این، علم داده با تسریع در شناسایی اهداف درمانی جدید، پتانسیل متحول کردن کشف دارو را دارد. محققان از طریق روشهای پیچیدهی تحلیل محاسباتی مانند تحلیل شبکه و مدلسازی مسیر، میتوانند روابط پنهان بین ژنها و بیماریهایی را که قبلاً ناشناخته بودند، کشف کنند. این دانش مسیرهای جدیدی را برای توسعهی درمانهای هدفمند که بهطور خاص برای این مسیرهای مولکولی تنظیم شدهاند، باز میکند.
علاوه بر این، پیشرفتهای علم داده همچنین زمینهساز پیشرفتهایی در پژوهشهای سرطان شده است. دانشمندان با استفاده از تکنیکهای تحلیل دادههای عظیم مانند شبکههای عصبی یادگیری عمیق، قادر به شناسایی الگوهایی در پروفایلهای ژنومی پیچیدهی تومور هستند که ممکن است میزان پاسخ به گزینههای مختلف درمانی را پیشبینی کنند. این امر به متخصصان انکولوژی اجازه میدهد تا تصمیمات آگاهانهای در مورد اینکه کدام درمانها به احتمال زیاد برای پروفایل سرطان منحصر به فرد هر بیمار مؤثر خواهند بود، اتخاذ کنند.

با ورود به حوزههای ژنتیک و ژنومیک با فناوریهای محاسباتی قدرتمندتر در اختیار، واضح است که فرصتهای بیپایانی برای بهبود مراقبتهای بهداشتی از طریق کاربردهای علم داده وجود دارد. از راهبردهای پزشکی شخصیسازیشده متناسب با ژنومهای فردی گرفته تا انقلابی در کشف دارو و پیشبرد تحقیقات سرطان و تاثیرات آن.
نتیجهگیری
علم داده با ارائهی ابزارهای قدرتمند برای تحلیل و تفسیر حجم عظیمی از اطلاعات ژنتیکی، انقلابی در حوزهی ژنتیک و ژنومیک به پا کرده است. نقش علم داده در پژوهشهای ژنتیکی را نمیتوان نادیده گرفت، زیرا این دانش پژوهشگران را قادر میسازد تا بینشهای حیاتی دربارهی بیماریهای پیچیده و اهداف درمانی بالقوه کشف کنند.

با استفاده از تکنیکهای پیشرفتهی تحلیل داده، مانند الگوریتمهای یادگیری ماشین، محققان میتوانند الگوها و همبستگیهایی را درون مجموعه دادههای ژنومی شناسایی کنند که در غیر این صورت ممکن بود مورد توجه قرار نگیرند. این امر نه تنها سرعت کشف را تسریع میکند، بلکه درک ما از ارتباط پیچیدهی بین ژنها و بیماری را نیز افزایش میدهد.
علاوه بر این، علم داده با توانمندسازی دانشمندان برای استخراج اطلاعات معنادار از ژنومهای فردی، راه را برای پزشکی شخصیسازیشده هموار کرده است. با ادغام دادههای ژنومی با پروندههای پزشکی و سایر متغیرهای مرتبط با سلامت، متخصصان مراقبتهای بهداشتی میتوانند تشخیصهای دقیقتری انجام دهند، پیامدهای بیماری را برای بیماران پیشبینی کنند و برنامههای درمانی هدفمندی را بر اساس ترکیب ژنتیکی منحصر به فرد هر فرد ایجاد نمایند.

با این حال، استفاده از علم داده در ژنتیک و ژنومیک نیز با چالشهای خاص خود همراه است. ملاحظات اخلاقی در مورد مسائل حفظ حریم خصوصی هنگام برخورد با مجموعه دادههای ژنومی در مقیاس بزرگ باید به دقت مورد توجه قرار گیرد. علاوه بر این، اطمینان از صحت و قابلیت اعتماد مدلهای محاسباتی برای جلوگیری از سوءتفاهم یا پیشبینیهای نادرست بر اساس اطلاعات ناقص یا مغرضانه ضروری است.
با نگاهی به آینده، چشماندازهای استفاده از علم داده در این حوزه امیدوارکننده است. با پیشرفت فناوری با سرعتی بیسابقه، میتوانیم انتظار داشته باشیم که الگوریتمهای حتی پیچیدهتری برای استخراج بینشهای ارزشمند از مجموعه دادههای ژنومی به طور فزایندهی پیچیده، توسعه یابند. این امر بدون شک منجر به پیشرفتهای بیشتر در پزشکی دقیق و کمک قابل توجهی به بهبود نتایج مراقبتهای بهداشتی در سراسر جهان خواهد شد.
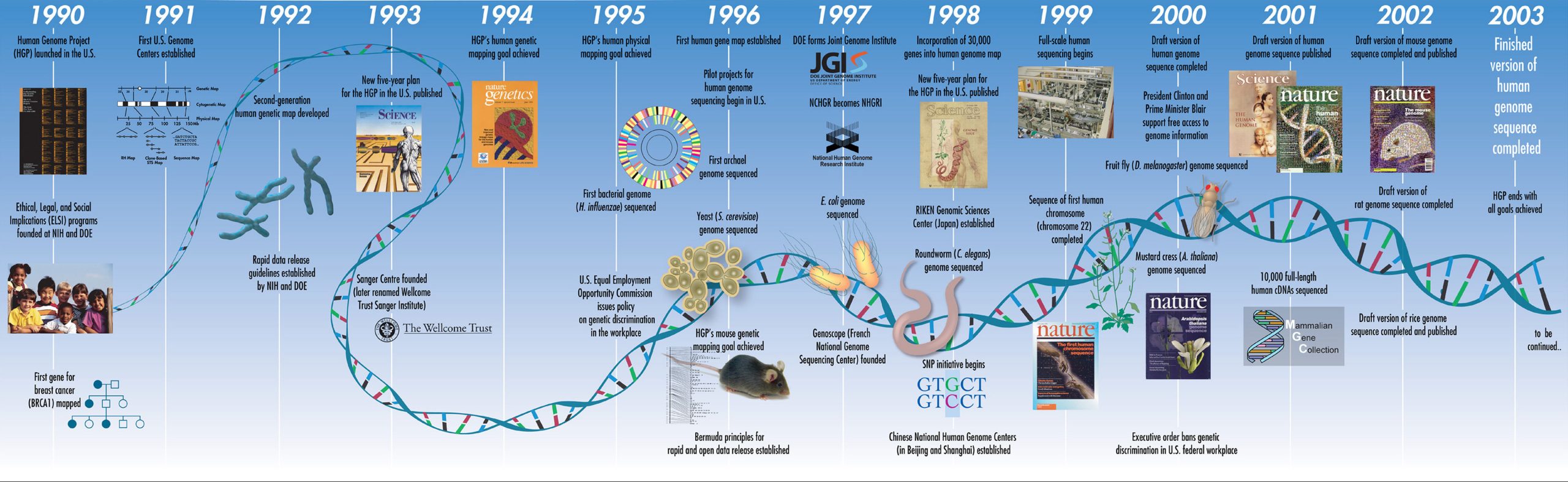
پیوند علم داده و ژنتیک، امکانات جدیدی را برای کشف رمز و رازهای کدگذاریشده در DNA ما گشوده است. دانشمندان با استفاده از ابزارهای تحلیلی پیشرفته مانند الگوریتمهای یادگیری ماشین و اعمال آنها بر روی مجموعههای عظیم اطلاعات ژنتیکی، به درک بیسابقهای از سلامت و بیماری انسان دست مییابند. تأثیر این امر بر مراقبتهای بهداشتی عمیق است – پزشکی شخصیسازیشده در حال تبدیل شدن به یک واقعیت است و در عین حال بیماران را با گزینههای تشخیصی بهتر توانمند میسازد که در نهایت منجر به زندگی سالمتر برای همه میشود.
منبع: صفحه Emerging India Analytics در مدیوم