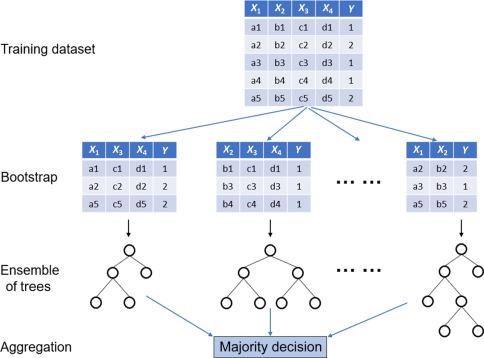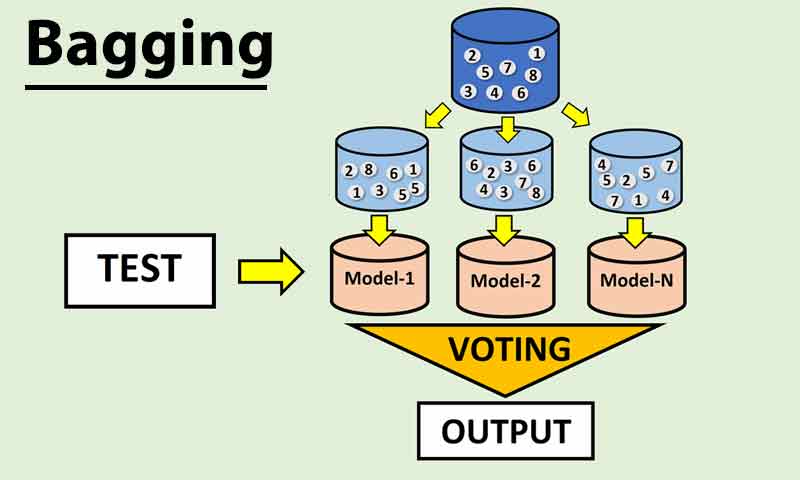
روش رایج در رویکرد Bagging در یادگیری گروهی ساخت مدل های پایه با استفاده از الگوریتم یکسان در داده های آموزشی متفاوت می باشد. بطوریکه نمونه ها آزمایشی متعددی با روش بوت استرپ از داده های آموزشی ساخته شده و یک الگوریتم یکسان با استفاده از آنها آموزش داده می شود.
روش بوت استرپ (Bootstrap)
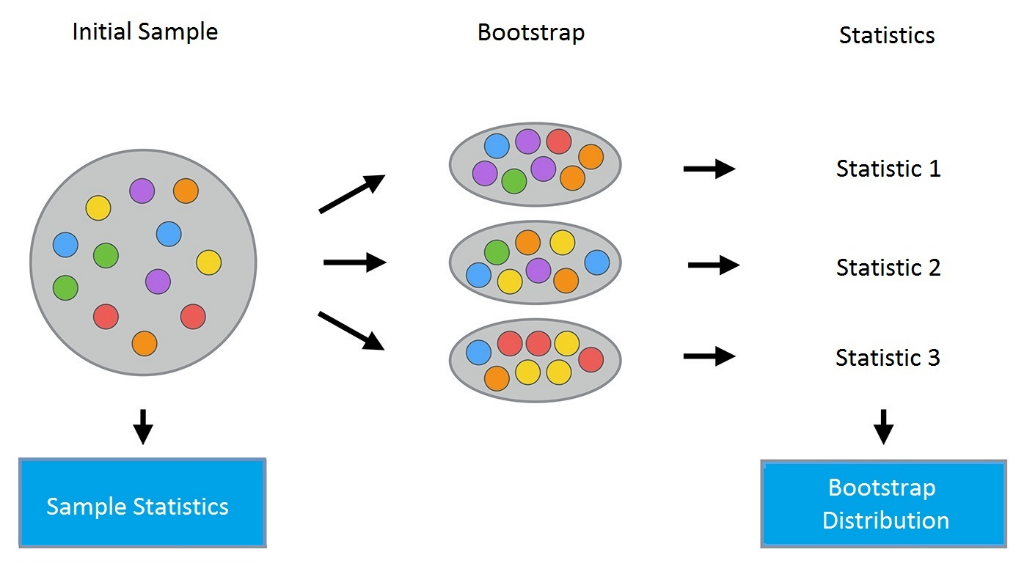
یک روش آماری برای محاسبه پارامترهای جامعه از طریق نمونه گیری با جایگذاری می باشد. در تخمین پارامترهای آماری می توان با ایجاد نمونه های متعدد از طریق نمونه گیری با جایگذاری و میانگین گرفتن از برآوردهای هر نمونه به برآورد پارامتر مجهول دست یافت.
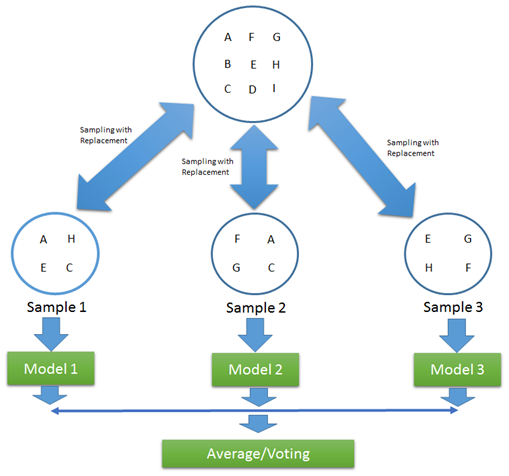
در رویکرد Bagging، با این روش مجموعه داده های آزمایشی متعددی ایجاد شده و در ساخت مدل های پایه استفاده می شود.
کارکرد اصلی روش Bagging در کنترل و کاهش واریانس خطای پیش بینی است. بنابراین در مواقعی از این رویکرد استفاده می شود که بایاس مدل های پایه کم و واریانس آنها زیاد باشد. (مدل های با پیچیدگی زیاد و دارای بیش برازش)
افزایش تعداد مدل های پایه در این رویکرد، به علت استفاده از میانگین یا مد در نتیجه نهایی منجر به بیش برازش نمی شود و عموما تا جایی که منجر به بهبود در نتایج نگردد، تعداد مدل ها افزایش می یابد.
رویکرد Bagging نیز در چارچوب یادگیری گروهی مستقل قرار می گیرد و از ویژگی های آن در پیاده سازی، موازی سازی آموزش مدل های پایه می باشد. به همین دلیل در آموزش مدل های رویکرد Bagging از حداکثر CPU استفاده شده و زمان آن برابر با آموزش یک مدل پایه می باشد.
الگوریتم جنگل تصادفی (Random Forest)
این الگوریتم یکی از محبوب ترین و رایج ترین الگوریتم های یادگیری گروهی با رویکرد Bagging می باشد که در دامنه وسیعی از مسائل رده بندی و رگرسیون، عملکرد بسیار خوبی داشته است.
الگوریتم جنگل تصادفی در چارچوب رویکرد Bagging با در نظر گرفتن الگوریتم درخت تصمیم هرس نشده (با عمق زیاد) به عنوان مدل پایه، تعداد بسیار زیادی مدل بیش برازش شده دارای بایاس کم ایجاد نموده و با رای گیری یا میانگین گیری از پیش بینی مدل های پایه از بیش برازش کلی مدل جلوگیری می کند.
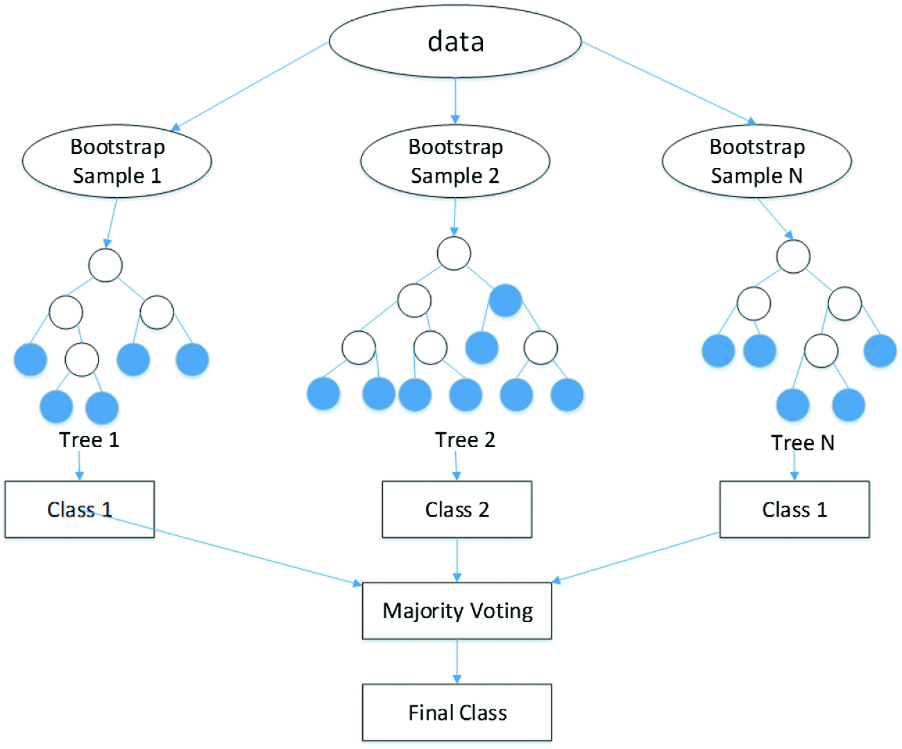
یک تفاوت مهم در الگوریتم جنگل تصادفی نسبت به رویکرد کلی Bagging استفاده از زیرمجموعه ای از ویژگی های ورودی در آموزش و ساخت مدل های پایه می باشد. این موضوع منجر به تفاوت بیشتر بین مدل های پایه و کاهش همبستگی نتایج آنها می شود.
معمولا در مسائل رگرسیون تعداد ویژگی های ورودی هر مدل پایه، در حدود یک سوم ویژگی های ورودی اصلی و در مسائل رده بندی، جذر تعداد ویژگی های ورودی در نظر گرفته می شود.