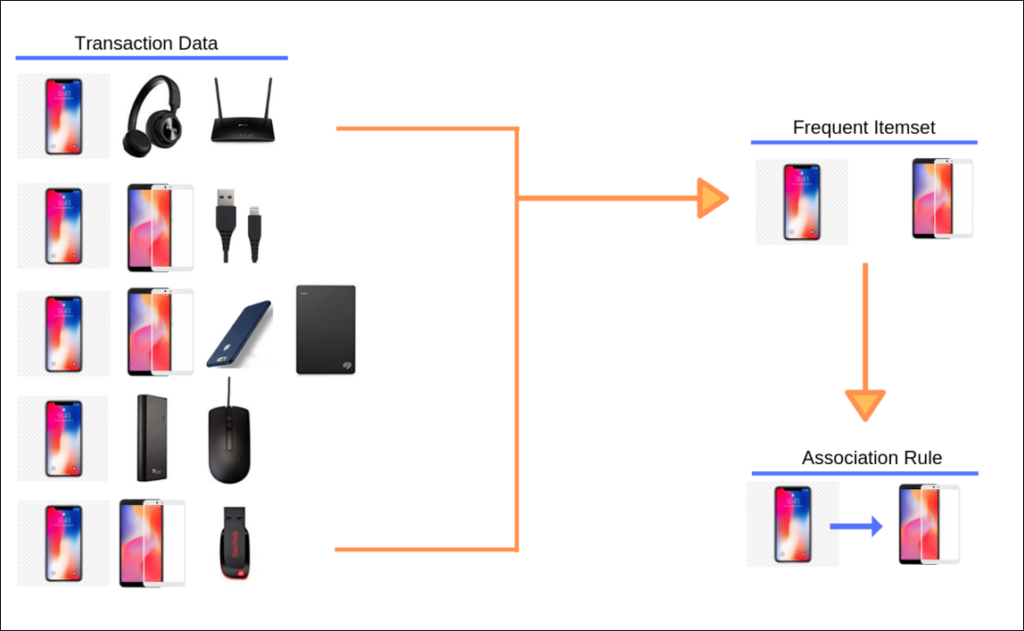
معرفی الگوریتم Apriori
الگوریتم Apriori با هدف تولید قوانین انجمنی، در دو مرحله شناسایی مجموعه اقلام مکرر و تولید قوانین توسعه یافته است. در گام اول، به منظور شناسایی مجموعه اقلام مکرر، نیازمند دانستن پارامتر حداقل پشتیبانی (min Support) می باشد. پشتیبانی (Support) : نسبتی از تمامی تراکنش ها که در آنها یک قلم یا ترکیبی از اقلام […]
معرفی الگوریتم Apriori Read More »