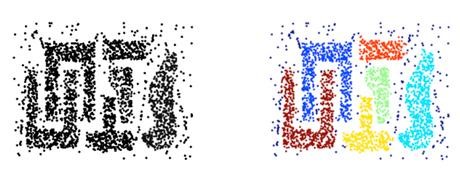
الگوریتم DBSCAN یا همان Density Based Spatial Clustering of Applications with Noise رایج ترین الگوریتم خوشه بندی مبتنی بر تراکم می باشد که در مقابل نویز و داده های پرت مقاوم می باشد. همچنین با توجه به ساختار این الگوریتم، جهت شناسایی الگوهای پیچیده و غیرکروی مورد استفاده قرار می گیرد.
ایده اصلی در این الگوریتم این است که یک رکورد به یک خوشه تعلق دارد در صورتی که به رکوردهای زیادی از آن خوشه نزدیک باشد.
بنابراین تعریف میزان تراکم داده ها، اهمیت اساسی در شناسایی ساختار الگوها دارد.
دو پارامتر اصلی برای اجرای الگوریتم
دو پارامتر اصلی برای اجرای الگوریتم وجود دارد:
eps یا شعاع همسایگی: فاصله ای که برای تعریف همسایگی به کار می رود. اگر دو رکورد دارای فاصله کمتر از آن باشند، نقاط همسایه در نظر گرفته می شود.
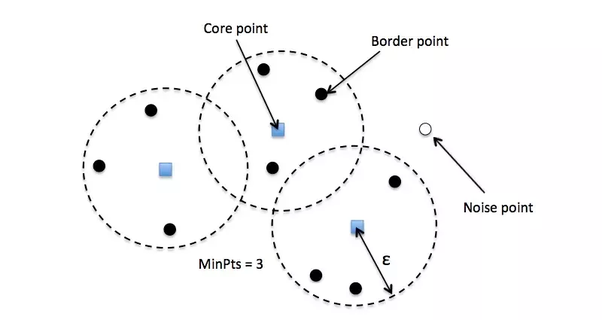
minPts: حداقل تعداد همسایه در محدوده یک شعاع تعریف شده جهت قرار گیری در یک خوشه با توجه به پارامترهای تعریف شده، سه گروه از داده ها قابل تعریف است:
نقاط مرکزی Core Point: نقاطی از داده ها که در شعاع همسایگی آنها حداقل به تعداد minPts همسایه وجود داشته باشد.
Border Points نقاط مرزی: همسایگانی از نقاط مرکزی که قابلیت تبدیل به نقاط مرکزی ندارند.
نقاط پرت Noise Points: نقاطی که در همسایگی هیچ نقطه مرکزی نیستند.
نحوه اجرای الگوریتم
- یک نقطه به تصادف انتخاب می شود و با توجه به پارامترهای eps و minPts نوع داده تعیین می گردد. در صورتی که نویز تشخیص داده شود، کنار گذاشته شده و نقطه دیگری انتخاب می گردد.
- در صورتی که نوع داده، نقطه مرکزی تشخیص داده شود، به همراه تمام همسایه های خود متعلق به خوشه اول در نظر گرفته می شود و سپس نقطه مرکزی بودن همسایه ها مورد بررسی قرار می گیرد. در صورتی که تمام یا برخی از آنها نیز از نوع نقاط مرکزی باشد تمامی همسایه های مربوط به سایر نقاط مرکزی نیز متعلق به خوشه اول در نظر گرفته می شود و این روند ادامه پیدا می کند تا خوشه اول ساخته شود.
- برای شروع ساخت خوشه دوم از بین نقاط داده باقیمانده (از جمله داده های نویزی مرحله قبل)، مجددا نقطه ای به تصادف انتخاب شده و کلیه مراحل قبل تکرار می شود.
- این روند ادامه پیدا کرده تا هیچ نقطه مرکزی بر اساس پارامترهای تعریف شده eps و minPts در مجموعه داده ها وجود نداشته باشد.
تنظیم پارامتر های الگوریتم
- minPts : انتخاب مقادیر کوچک برای این پارامتر معمولا نتایج خوبی نخواهد داشت. بطور مثال انتخاب minPts =1 منجر به این خواهد شد که هر کدام از رکوردها به عنوان یک خوشه انتخاب شود. در صورتی که minPts =2 تنظیم گردد نتیجه خوشه بندی معادل خوشه بندی سلسله مراتبی با روش Single Linkage همراه با مقدار آستانه ای eps برای انتخاب خوشه می باشد. بنابراین مقدار این پارامتر معمولا بزرگتر از 2 و با توجه به ابعاد داده ها تعیین می گردد. به عنوان یک قاعده کلی مقدار این پارامتر بزرگتر از تعداد ویژگی های ورودی به الگوریتم انتخاب می گردد و انتخاب مقادیر بزرگ برای داده های نویزی و پیچیده مناسب تر است.
- eps یا شعاع همسایگی: در صورتی که پارامتر eps خیلی کوچک انتخاب گردد، بسیاری از داده ها در خوشه ها قرار نمی گیرند و در صورت انتخاب مقادیر بزرگ بخش زیادی از داده ها در یک خوشه ادغام می شود. به عنوان یک رویکرد کلی، تنها بخش کوچکی از داده ها بایستی در شعاع همسایگی قرار گیرند و انتخاب مقادیر کوچکتر پارامتر eps ارجحیت دارد.

الگوریتم DBSCAN (Density Based Spatial Clustering of Applications with Noise)
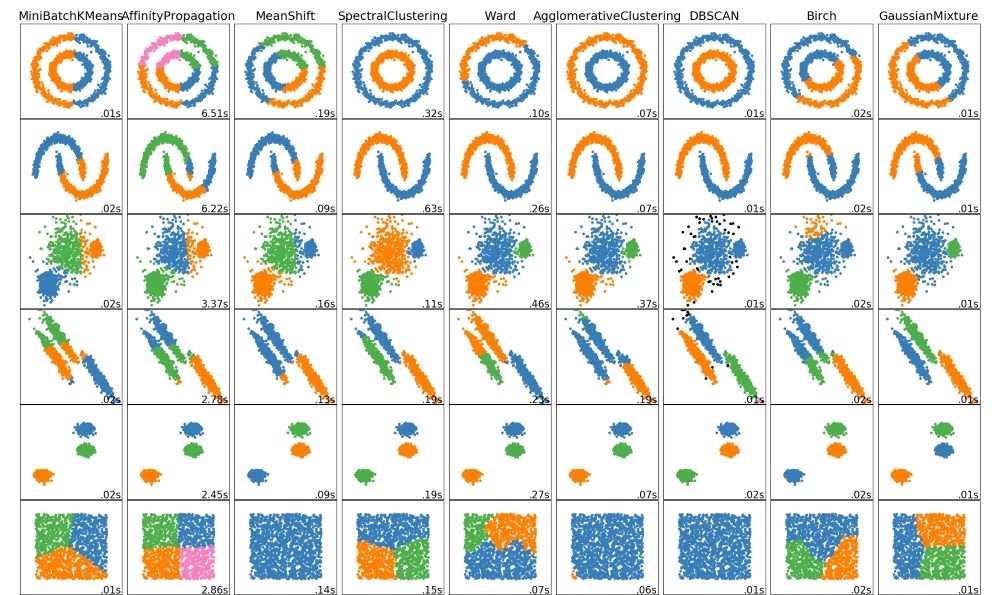
الگوریتم DBSCAN در مقایسه با الگوریتم های افرازی مانند K-Means قابلیت شناسایی الگوهای پیچیده و تودرتو را از طریق تفکیک نواحی پرتراکم و کم تراکم ایجاد می کند.
ولی بایستی توجه داشت در صورتی که تراکم داخلی خوشه ها تفاوت بسیاری داشته باشد، با توجه به نحوه عملکرد این الگوریتم بر اساس پارامترهای eps و minPts این الگوریتم توانایی شناسایی خوشه ها با تراکم های غیر همگن را ندارد. برای این منظور الگوریتم OPTICS معرفی شده است.