« Data Types and Structures »
سوالات :
- تفاوت نوع داده ها در R چیست ؟
- تفاوت ساختار داده ها در R چیست ؟
- چگونه می توانم به داده ها در ساختار داده های مختلف دسترسی پیدا کنم؟
اهداف :
- به زبان آموزان انواع داده ها در R را نمایش می دهد.
- یاد بگیرید بردارهایی از انواع مختلف ایجاد کنید.
- بررسی نوع بردار ها.
- اطلاعات در مورد داده های گم شده و سایر مقادیر خاص.
-
آشنایی با ساختارهای داده های مختلف (لیست ها، ماتریس ها، فریم های داده و…)
درک انواع داده ها در R
- در هر زبان برنامه نویسی برای ذخیره اطلاعات شما نیاز به متغییرهایی جهت ذخیره اطلاعات دارید . شما ممکن است اطلاعاتی از انواع داده ها ذخیره کنید ، که براساس نوع داده سیستم عامل حافظه ای را برای ذخیره سازی اختصاص میدهد.
- برای این که به زبان R مسلط باشید شما نیاز به درک قوی از اساس نوع داده ، ساختار داده و نحوه کار با آن ها را دارید.
- در زبان R برخلاف زبان های برنامه نویسی دیگر نوع داده در تعریف داده نوشته نمی شود .درک داده در این زبان بسیار مهم می باشد زیرا اشیاء روز به روز در R دستکاری میشوند.
نکته : همه چیز در R یک شیء می باشد . زبان R بر خلاف زبان های برنامه نویسی دیگر با متغییرهایی که تعریف میشود به عنوان variable برخورد نمیکند و آن ها را به عنوان objects می شناسد.
R دارای 6 نوع متغییر یا به عبارتی اشیاء پایه(atomic) را شامل می شود.
انواع داده ها عبارتند از :
- logical
- numeric (real or decimal)
- integer
- character
- complex
- raw
در جدول زیر به بررسی مختصر این نوع داده ها پرداخته که جهت آشنایی اولیه شما می باشد ، که در ادامه مطالب به صورت کاربردی تر از آن ها استفاده می کنیم.
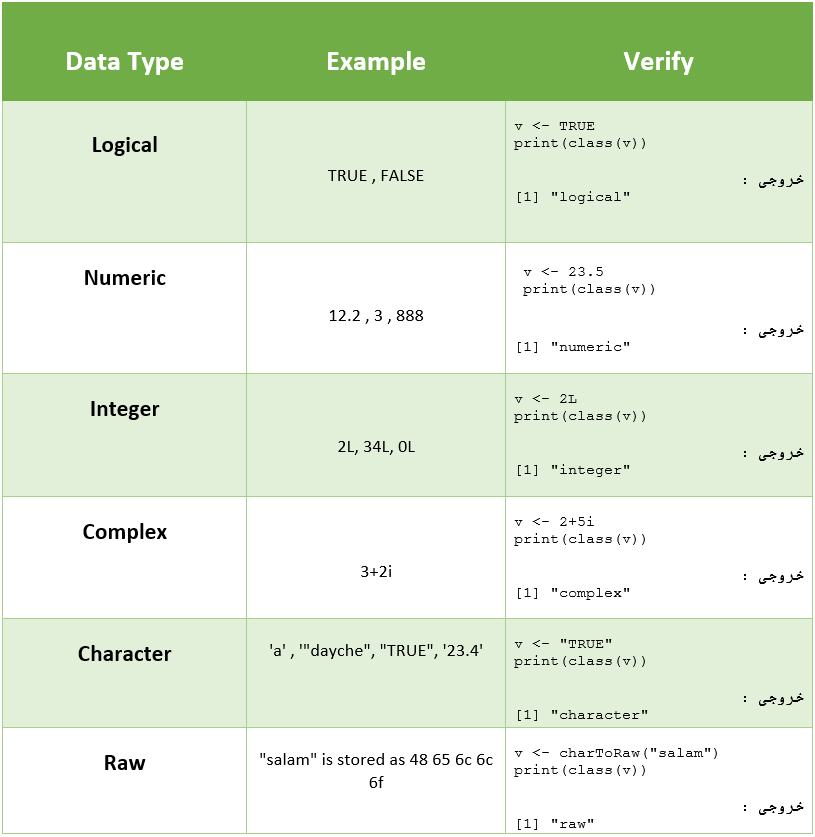
•نکته : حرف L کنار اعداد در مثال Integer به این معنی می باشد که اعداد را از نوع Integer بشناسد.
R یک سری توابع را در نظر گرفته جهت بررسی بردار ها یا دیگر شئ ها که عبارتند از :
- () class : مشخص میکند شئ چه نوعی می باشد .
- () typeof : همانند () class عمل میکند اما در سطحی پایین تر .
- () length : طول شئ را مشخص میکند .
- () attributes : این زبان به کاربر اجازه می دهد اگر بخواهند attribute غیر از ویژگی های قبلی به یک شئ منتصب کند، که R آن ها را به عنوان کلاس کلی metadata می شناسد.
به مثال زیر توجه کنید
> d <- "Dayche" > class(d) #high level [1] "character" > typeof(d) #low level [1] "character" > length(d) [1] 1 > attributes(d) NULL
نکات قابل توجه :
ویژگی length به شما تعداد اعضا را برمیگرداند و شئ تعریف شده ما دارای یک عضو می باشد.در ادامه مطلب مثالی در این خصوص می باشد.
در خط آخر مشاهده می کنید که مقدار NULL را برگرداند این بدین معنی میباشد که هیچ ویژگی به شئ نسبت داده نشده
R شامل ساختار های داده بسیاری می باشد .
انواع ساختار داده
- vector
- matrix
- array
- factor
- list
- data frames
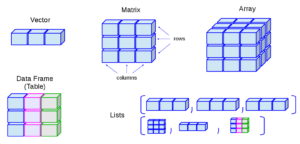
بردار (Vector)
شایع ترین و اساسی ترین ساختار داده در R است ، به اصطلاح کارگر R . که شامل چند داده با نوع یکسان می باشد.
برای ساختن بردار از تابع () Vector استفاده می کنیم . بدین صورت :
vector() #an empty Vector logical(0)
مثالی دیگر :
vector("character",length=5) #a vector of mode 'character' with 5 elements
[1] "" "" "" "" ""
برای ساخت بردار از توابع ساده تر نیز میتوان استفاده کرد به عنوان مثال :
character(5) [1] "" "" "" "" ""
شما همچنین می توانید بردار ها را با تعیین دقیق محتوا ایجاد کنید که R نوع داده را تشخیص میدهد و نیاز به نوشتن نوع آن نیست برای این کار از تابع () c استفاده کنید.
> numb <- c (1,2,3,4) > print (numb) [1] 1 2 3 4
•عملیات همیشه بر روی تمام عناصر آرایه عددی انجام می شود:
> 1/numb [1] 1.0000000 0.5000000 0.3333333 0.2500000 > b = numb-1 > b [1] 0 1 2 3
نکته : اگر در کد بالا دقت کرده باشید برای انتساب دادن مقداری به متغییر b از ” = ” به جای ” -> ” استفاده کرده ایم ، که در واقع هردو یک عمل را انجام میدهند. و همچنین به جای استفاده از تابع () print جهت نمایش محتویات متغییر نام آن را نوشته ایم یا به اصطلاح صدایش زده ایم که باز هم هردو یک عمل را انجام میدهند.
•خیلی وقت ها ممکن است ما بخواهیم دنباله ای از اعداد را در یک متغییر ذخیره کنیم ، به مثال زیر توجه کنید:
> 2:10 # generate a sequence from n1=2 to n2=10 using n1:n2 [1] 2 3 4 5 6 7 8 9 10 > 5:1 # generate an inverse sequence if n2 < n1 [1] 5 4 3 2 1
•جهت تکرار دنباله به صورتی که هر عنصر تکرار شود یا دنباله چندین بار تکرار شود به مثال زیر توجه کنید:
a <- 1:3 ; b <- rep(a, times=3) ; C <- rep(a, each=3) > a [1] 1 2 3 > b [1] 1 2 3 1 2 3 1 2 3 > c [1] 1 1 1 2 2 2 3 3 3
نکته : در مثال بالا ما سه دستور را در همان خط اجرا کردیم. که آن ها توسط یک ‘؛’ جدا شده اند.
•اگر ما بخواهیم بدانیم کدام اشیا در حال حاضر تعریف شده اند، می توانیم آن ها را لیست کنیم:
> ls() [1] "a" "b" "c" "d"
•با استفاده از تابع () rm می توان اشیاء مورد نظر را حذف کرد:
> rm(a,c) # remove objects 'a' and 'b' > ls() # list current objects [1] "b" "d"
•برای حذف همه چیز در محیط کاری:
> rm(list=ls()) # Use this with caution > ls() # (you'll receive no warning!) character(0)
بردار های منطقی (Logical Vectors)
> a <- seq(1:10) # generate a sequence > a [1] 1 2 3 4 5 6 7 8 9 10 # show values in screen > b <- (a>5) # assign values from an inequality > b # show values in screen [1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE > a[b] [1] 6 7 8 9 10 > a[a>5] # the same, but avoiding intermediate variable [1] 6 7 8 9 10
توجه : از علامت «#» در زبان R برای قرار دادن جملات توضیحی یا همان comment استفاده می شود.
ماتریس (matrix)
آرایه های دو بعدی برای ذخیره مجموعه ای از داده ها با نوع داده یکسان می باشد.
> a <- matrix(1:12, nrow=3, ncol=4) # define a matrix with 3 rows and 4 columns > a [,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12 > dim(a) # return matrix dimensions (rows,columns) [1] 3 4
نکته : تابع () dim در مثال بالا برای برگرداندن ابعاد ماتریس می باشد یا به عبارتی تعداد سطر و ستون را بازمیگرداند
راه دیگر برای برای تعیین سطر و ستون استفاده از توابع () cbind و () rbind می باشد:
> a <- 1:3 > b <- 10:12 > cbind (a,b) a b [1,] 1 10 [2,] 2 11 [3,] 3 12 > rbind (a,b) [,1] [,2] [,3] a 1 2 3 b 10 11 12
و همچنین شما می توانید با استفاده از آرگومان byrow که مقدار FALSE یا TRUE تعیین میکنید که ماتریس شما چگونه پر شود
> m <- matrix( c(1:12) ,nrow=3 , ncol=4 , byrow = TRUE)
> m
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
> m <- matrix( c(1:12) ,nrow=3 , ncol=4 , byrow = FALSE)
> m
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
محاسبات ماتریس
عملیات ریاضی مختلف بر روی ماتریس با استفاده از اپراتورهای R انجام می شود. نتیجه عملیات نیز یک ماتریس است. ابعاد (تعداد ردیف ها و ستون ها) باید برای ماتریس های درگیر در عملیات یکسان باشد.
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
# Add the matrices.
result <- matrix1 + matrix2
print(result)
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
# Subtract the matrices
result <- matrix1 - matrix2
print(result)
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2
دسترسی به عناصر یک ماتریس
عناصر یک ماتریس را می توان با استفاده از ستون و ردیف عنصر مشاهده کرد:
> m <- matrix( c(1:12) ,nrow=3 , ncol=4 , byrow = TRUE) > print (m[2.3]) [1] 5
آرایه ها (Array)
آنها شبیه به ماتریسها هستند، هرچند که آن ها می توانند ابعاد بیشتری داشته باشند.به عنوان مثال – اگر ما آرایه ای از ابعاد (2,3,4 ) ایجاد کنیم، آنگاه 4 ماتریس مستطیل شکل با دو ردیف و 3 ستون ایجاد می شود. آرایه ها می توانند تنها نوع داده را ذخیره کنند.
> z <- array(1:24, dim=c(2,3,4))
> z
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
, , 3
[,1] [,2] [,3]
[1,] 13 15 17
[2,] 14 16 18
, , 4
[,1] [,2] [,3]
[1,] 19 21 23
[2,] 20 22 24
نام ستون ها و ردیف ها
ما می توانیم با استفاده از پارامتر dimnames نام ها را به ردیف ها، ستون ها و ماتریس ها در آرایه دهیم.
# Create two vectors of different lengths.
> vector1 <- c(5,9,3)
> vector2 <- c(10,11,12,13,14,15)
> column.names <- c("COL1","COL2","COL3")
> row.names <- c("ROW1","ROW2","ROW3")
> matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
> result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,
matrix.names))
> print(result)
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
دسترسی به عناصر آرایه
> z <- array(1:12, dim=c(2,3,2))
> z
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
# Print the second row of the second matrix of the array.
print(z[2,,2])
[1] 8 10 12
# Print the element in the 1st row and 3rd column of the 1st matrix.
print(z[1,3,1])
[1] 5
# Print the 2nd Matrix.
print(z[,,2])
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
تابع () factor
بعضی از متغییر ها به صورت دسته ای بیان می شوند که R آن ها را با factor نشان می دهند. این متغییر ها به دو صورت بیان می شوند : مرتب و غیر مرتب
# Create a vector as input.
data <- c("East","West","East","North","North","East","West","West","West","East","North")
print(data)
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North"
# Apply the factor function.
factor_data <- factor(data)
print(factor_data)
[1] East West East North North East West West West East North
Levels: East North West
lists (لیست ها)
لیست ها مجموعه ای از اشیا هستند که در آن عناصر می توانند از نوع دیگری باشند (لیست می تواند ترکیبی از ماتریس ها، بردارها، لیست های دیگر، و غیره باشد) آن ها با استفاده از تابع () list ایجاد می شوند:
# Create a list containing strings, numbers, vectors and a logical
# values.
list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
print(list_data)
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1
نامگذاری عناصر فهرست
به عناصر لیست می توان نامی را اختصاص داد که توسط آن به عناصر دسترسی پیدا کرد
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Show the list.
print(list_data)
$`1st Quarter`
[1] "Jan" "Feb" "Mar"
$A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$`A Inner list`
$`A Inner list`[[1]]
[1] "green"
$`A Inner list`[[2]]
[1] 12.3
ادغام لیست ها (Merging Lists)
شما می توانید لیست های زیادی را با قرار دادن همه لیست ها در داخل یک تابع () list ادغام کنید .
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
# Print the merged list.
print(merged.list)
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "Sun"
[[5]]
[1] "Mon"
[[6]]
[1] "Tue"
داده های چار چوب دار (data frame)
داده های چارچوب دار دارای ستون هایی با انواع مختلف هستند و مناسب ترین ساختار داده ها در تجزیه و تحلیل در R می باشد. هر ستون حاوی مقادیر یک متغیر است و هر ردیف حاوی یک مجموعه از مقادیر از هر ستون است. , و با استفاده از تابع () data.frame ایجاد می شود.
مشخصات data frames
- نام ستون نباید خالی باشد.
- نام ردیف باید منحصر به فرد باشد.
- داده ذخیره شده در data frame می تواند از نوع عددی ، صحیح و فاکتور باشد.
- تعداد آیتم های هر ستون باید برابر باشد.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)
emp_id emp_name salary start_date
1 1 Rick 623.30 2012-01-01
2 2 Dan 515.20 2013-09-23
3 3 Michelle 611.00 2014-11-15
4 4 Ryan 729.00 2014-05-11
5 5 Gary 843.25 2015-03-27
نکته : در data frame بردارهای از نوع کاراکتر به صورت خودکار به factors تبدیل می شوند و تعداد سطوح نیز به عنوان تعدادی از مقادیر مختلف در یک بردار تعیین شود، جهت جلوگیری از بروز این اتفاق stringsAsFactors = FALSE از این دستور استفاده می کنیم.
جهت دریافت ساختارdata frame از تابع () str استفاده میکنیم. ( جهت کوتاهی کد ها در مثال های بعدی کد های ساخت data frame را نمینویسیم)
# Get the structure of the data frame. str(emp.data) 'data.frame': 5 obs. of 4 variables: $ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ... $ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" ...
خلاصه آماری و ماهیت داده ها را می توان با استفاده از تابع summary () بدست آورد.
> print(summary(emp.data))
emp_id emp_name salary
Min. :1 Length:5 Min. :515.2
1st Qu.:2 Class :character 1st Qu.:611.0
Median :3 Mode :character Median :623.3
Mean :3 Mean :664.4
3rd Qu.:4 3rd Qu.:729.0
Max. :5 Max. :843.2
start_date
Min. :2012-01-01
1st Qu.:2013-09-23
Median :2014-05-11
Mean :2014-01-14
3rd Qu.:2014-11-15
Max. :2015-03-27
استخراج اطلاعات از data frame
# Extract Specific columns. result <- data.frame(emp.data$emp_name,emp.data$salary) print( result) emp.data.emp_name emp.data.salary 1 Rick 623.30 2 Dan 515.20 3 Michelle 611.00 4 Ryan 729.00 5 Gary 843.25
مثال: چاپ تمام ستون های دو ردیف اول:
# Extract first two rows. result <- emp.data[1:2,] print(result) emp_id emp_name salary start_date 1 1 Rick 623.3 2012-01-01 2 2 Dan 515.2 2013-09-23
مثال : چاپ دومین و چهارمین ستون سطر های سوم و پنجم:
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)
emp_name start_date
3 Michelle 2014-11-15
5 Gary 2015-03-27
گسترش data frame
# Add the "dept" coulmn.
emp.data$dept <- c("IT","Operations","IT","HR","Finance")
v <- emp.data
print(v)
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
ادغام دو data frame باهم
نکته : یک data frame دیگر اضافه میکنیم سپس ادغام میکنیم .
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c("Rasmi","Pranab","Tusar"),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
dept = c("IT","Operations","Fianance"),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
6 6 Rasmi 578.00 2013-05-21 IT
7 7 Pranab 722.50 2013-07-30 Operations
8 8 Tusar 632.80 2014-06-17 Fianance