هنگامی که صحبت از برنامهنویسی یادگیری ماشین به میان میآید، پایتون (Python) یکی از بهترین انتخابها است. با این حال، بسیاری از توسعهدهندگان و به ویژه افراد تازه وارد به این حوزه به درستی دلیل این مسئله را نمیدانند. در این مقاله به شما خواهیم گفت که چرا پایتون اولین انتخاب در زمینه برنامهنویسی یادگیری ماشین (Machine Learning)، علم داده (Data Science) و دادهکاوی (Data Mining) است.
[lwptoc]
در یادگیری ماشین و به طور کلی برنامهنویسی، معمولاً زبانی که استفاده میکنید، ملاک عمل نیست، زیرا زبانهای برنامهنویسی چیزی جز ابزار نیستند، مهم این است که بتوانید برای مشکلات راهحلهای خلاقانهای ارائه کنید. قبل از آنکه به ذکر دلایل برتری پایتون نسبت به زبانهای دیگر در زمینه یادگیری ماشین بپردازیم، اجازه دهید توضیح کوتاهی در این ارتباط ارائه کنیم.

پایتون چیست؟
پایتون یک زبان برنامهنویسی تفسیر شده (Interpreted language)، شیگرا (OOP)، سطح بالا (High-level) و پویا (Dynamic) است که ترکیب نحوی ساده و کدنویسی مختصر دارد. ترکیب این عوامل با یکدیگر باعث شده تا پایتون در دنیای برنامهنویسی به شهرت بالایی دست پیدا کند.
ساختارهای داده داخلی سطح بالای آن، همراه با تایپ پویا و مقیدسازی پویا (Dynamic Binding)، باعث شدهاند تا توسعهدهندگان این زبان در مقایسه با همتایان خود در مدت زمان کوتاهی برنامههای کاربردی و نمونههای اولیه را آماده کنند. علاوه بر این، پایتون توسط طیف گستردهای از کتابخانهها پشتیبانی میشود که باعث شدهاند این زبان در حوزههای مختلفی قابل استفاده باشد.
به عبارت سادهتر، پایتون یک زبان برنامهنویسی سطح بالا است که به گونهای طراحی شده تا کاربری، درک و اشکالزدایی کدهای آن ساده باشد. به همین دلیل است که مورد توجه برنامهنویسان مبتدی و حرفهای قرار دارد.
یادگیری ماشین چیست؟

یادگیری ماشین، به مطالعه روی الگوریتمهای کامپیوتری اشاره دارد که بهطور خودکار از طریق تجربه و با استفاده از دادهها عملکرد و کیفیت آنها بهبود پیدا میکند. به بیان دقیقتر، یادگیری ماشین شاخهای از هوش مصنوعی (Artificial Intelligence) و علوم کامپیوتر است که بر استفاده از دادهها و الگوریتمها برای تقلید از روشی که انسانها یاد میگیرند متمرکز است و به تدریج و در گذر زمان دقت آن بهبود پیدا میکند.
بر مبنای این تعریف متوجه میشویم که یادگیری ماشین هنر ساخت ماشینهای هوشمندی است که توانایی انجام یک کار خاص را دارند. این توانایی انجام کار از طریق دادههای محیطی که به عنوان ورودی یا خوراک (Feed) در اختیار الگوریتم قرار میگیرد و نظارت عامل انسانی به دست میآید.
نکتهای که باید در ارتباط با یادگیری ماشین به آن اشاره داشته باشیم به زیرشاخههای آن باز میگردد که عبارتند از یادگیری ماشین با نظارت، بدون نظارت و تقویتی. دادههای مورد نیاز الگوریتم یادگیری ماشین در قالب مجموعهای که کلان دادهها (Big Data) نام دارند بر مبنای ساختار مشخصی (دادههای دارای برچسب یا بدون برچسب) در اختیار مدل قرار میگیرند.

از آنجایی که یادگیری عمیق (Deep Learning) و یادگیری ماشین به جای یکدیگر مورد استفاده قرار میگیرند، ارزشش را دارد تا به تفاوتهای ظریف بین این دو فناوری اشارهای داشته باشیم. یادگیری ماشین، یادگیری عمیق و شبکههای عصبی همگی زیر شاخههای هوش مصنوعی هستند. با این حال، یادگیری عمیق در واقع یک زیر شاخه از یادگیری ماشین است و شبکههای عصبی یک زیر شاخه از یادگیری عمیق هستند.
تفاوت یادگیری عمیق و یادگیری ماشین در نحوه یادگیری هر الگوریتم است. یادگیری عمیق بخش عمدهای از فرآیند استخراج ویژگی را خودکار میکند، برخی از مداخلات دستی عامل انسانی را حذف میکند و امکان استفاده از مجموعه دادههای بزرگتر را فراهم میکند.
همانطور که لکس فریدمن در سخنرانی خود در MIT به آن اشاره کرد، میتوانید یادگیری عمیق را به عنوان “یادگیری ماشین مقیاسپذیر” در نظر بگیرید. یادگیری ماشین کلاسیک یا “غیر عمیق” بیشتر به مداخله انسان برای یادگیری وابسته است. متخصصان انسانی مجموعهای از ویژگیها را برای درک تفاوت بین ورودیهای دادهای تعیین میکنند که معمولاً برای یادگیری به دادههای ساختاریافته بیشتری نیاز دارند.
یادگیری ماشین «عمیق» میتواند از مجموعه دادههای برچسبگذاریشده، که به عنوان یادگیری نظارتشده نیز شناخته میشود، برای هویت و معنا بخشیدن به الگوریتم استفاده کند، اما لزوماً به یک مجموعه داده برچسبدار نیاز ندارد. میتواند دادههای بدون ساختار را به شکل خام (مثلاً متن، تصاویر) دریافت کند و میتواند به طور خودکار مجموعهای از ویژگیهایی را تعیین کند که دستههای مختلف دادهها را از یکدیگر متمایز میکنند.
برخلاف یادگیری ماشین، برای پردازش دادهها نیازی به مداخله انسانی نیست و به ما امکان میدهد یادگیری ماشین را به روشهای جالبتری مقیاسبندی کنیم. یادگیری عمیق و شبکههای عصبی در درجه اول باعث تسریع پیشرفت در زمینههایی مانند بینایی کامپیوتر، پردازش زبان طبیعی و تشخیص گفتار میشوند.

شبکههای عصبی یا شبکههای عصبی مصنوعی (ANN) سرنام artificial neural networks از یک لایه گره تشکیل شدهاند که شامل یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی است. هر گره یا نورون مصنوعی به دیگری متصل میشود و دارای وزن و آستانه مرتبط است. اگر خروجی هر گره منفرد بالاتر از مقدار آستانه مشخص شده باشد، آن گره فعال میشود و دادهها را به لایه بعدی شبکه ارسال میکند. در غیر این صورت، هیچ دادهای به لایه بعدی شبکه منتقل نمیشود. “عمیق” در یادگیری عمیق فقط به عمق لایهها در یک شبکه عصبی اشاره دارد.
یک شبکه عصبی که از بیش از سه لایه تشکیل شده است که شامل ورودیها و خروجیها است، میتواند یک الگوریتم یادگیری عمیق یا یک شبکه عصبی عمیق در نظر گرفته شود. یک شبکه عصبی که فقط دو یا سه لایه دارد، تنها یک شبکه عصبی اولیه است.
چرا پایتون در تعامل با یادگیری ماشین استفاده میشود؟

از مهمترین دلایل به موارد زیر باید اشاره کرد:
سادگی و سازگاری
دنیای یادگیری ماشین از الگوریتمهای پیچیده و گردشهای کاری چند منظوره تشکیل شده است. به همین دلیل نیازمند یک زبان برنامهنویسی هستیم که ترکیب نحوی پیچیدهای نداشته باشد، کدهای مختصر داشته باشد و بالاترین سطح از خوانایی را ارائه کند. پایتون تمامی این ویژگیها را دارد، در نتیجه به توسعهدهندگان یادگیری ماشین کمک میکند تا به جای درگیر شدن در پیچیدگیهای ترکیب نحوی زبان برنامهنویسی، روی راهکارهای خلاقانه برای حل مسائل تمرکز کنند. پایتون یک زبان بسیار شهودی است که همین موضوع باعث میشود، توسعهدهندگان یادگیری ماشین برای ساخت مدلهای پیچیده مشکلی با پایتون نداشته باشند.
اکوسیستم کتابخانههای گسترده
ساخت مدلهای یادگیری ماشین میتواند به سرعت پیچیده و دشوار شود. برای کاهش این پیچیدگی، کتابخانههای منبع باز ساخته شدهاند تا فرآیند ساخت مدلهای یادگیری ماشین را آسانتر کنند.
لازم به توضیح است که کتابخانههای نرمافزاری کدهای از پیش نوشته شدهای هستند که برای حل مشکلات رایج استفاده میشوند. برای درک بهتر عملکرد کتابخانهها باید بدانید که زندگی یک توسعهدهنده نرمافزار سرشار از کدنویسی است، اما گاهی اوقات برخی از کدهای نوشته شده آنقدر رایج هستند که برای توسعهدهندگان نرمافزار منطقی نیست که کدهای مشابهی را بارها و بارها بنویسند.
رویکرد فوق درست مثل این حالت است که یک نویسنده برای هر خواننده کتابی جداگانه بنویسد و اقدام به چاپ و توزیع آنیها کند. کتابخانهها ماژولها و قطعه کدهایی هستند که به طور مداوم در هنگام توسعه نرمافزار استفاده میشوند. در این حالت توسعهدهندگان تنها تصمیم میگیرند از چه کتابخانه یا تابعی در برنامه خود استفاده کنند.
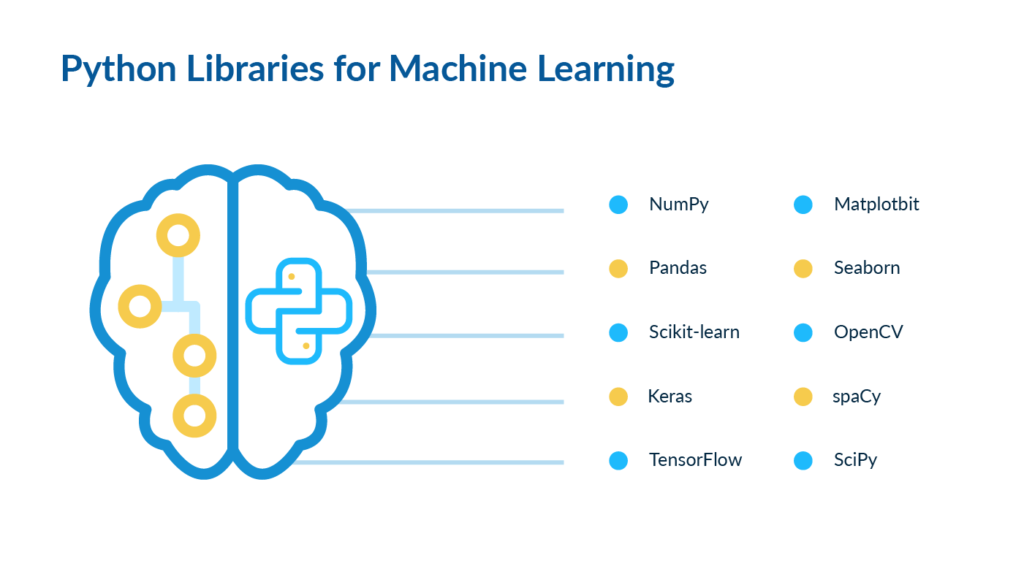
پایتون به دلیل وجود کتابخانههای کارآمدی که دارد، نزد مهندسان یادگیری ماشین محبوب است، زیرا بسیاری از کتابخانههای نرمافزاری نوشته شده برای پایتون قادر به انجام محاسبات پیچیدهای هستند که برای کدنویسی آنها زمان قابل توجهی را باید صرف کرد. از کتابخانههای معروفی که برای این منظور وجود دارد به موارد زیر باید اشاره کرد:
پانداس (Pandas): مناسب برای تجزیه و تحلیل دادهها و پیادهسازی گذرگاه انتقال دادهها.
کراس (Keras): مناسب برای ساخت مدلهای یادگیری عمیق.
matplotlib: مناسب برای تجسمسازی یا همان مصورسازی دادهها.
نامپای (Numpy): مناسب برای ساخت و دستکاری آرایهها و پشتیبانی کارآمد توسط آناکواندا.
اسکیلرن (Sklearn): مناسب برای ساخت مدلهای یادگیری ماشین.
تنسورفلو (Tensorflow): مناسب برای ساخت شبکههای عصبی.
کتابخانههای دیگری مثل Seaborn نیز وجود دارند که کاربردهای خاصمنظوره دارند.
فارغ از سکو (Platform Independence)
فارغ از سکو در سادهترین تعریف به معنای توانایی یک زبان برنامهنویسی است که به توسعهدهندگان اجازه میدهد کدهای مشابهی را در سیستم عاملهای مختلفی مثل ویندوز، لینوکس و مک اجرا کنند. زبان دیگری که فارغ از سکو است و به توسعهدهندگان اجازه میدهد بدون نیاز به اعمال تغییر در کدها، در سیستم عاملهای مختلف برنامهای که نوشتهاند را اجرا کنند جاوا است. جاوا به لطف ماشین مجازی جاوا که فرآیند تبدیل بایتکدها را بر عهده دارد، به توسعهدهندگان اجازه میدهد از مزایای فارغ از سکو بودن به بهترین شکل استفاده کنند.
کد پایتون را میتوان برای ایجاد برنامههای اجرایی مستقل برای اکثر سیستم عاملهای رایج استفاده کرد، به این معنا که کدهای پایتون را میتوان به راحتی بدون مفسر پایتون در سیستم هدف استفاده کرد.
مزیت مهم دیگری که پایتون دارد این است که امروزه بیشتر شرکتها به دنبال جذب متخصصان یادگیری ماشین و مهندسان دادهای هستند که مسلط به زبان پایتون هستند. پایتون به لطف کتابخانههای قدرتمندی که برای این منظور ارائه شدهاند، توانایی کار با واحدهای پردازش گرافیکی قدرتمند (GPU) را برای آموزش مدلهای یادگیری ماشین دارد. این واقعیت که پایتون مستقل از پلتفرم است، فرآیند آموزش آنرا ارزانتر و آسانتر میکند.
جامعهای فعال از متخصصان
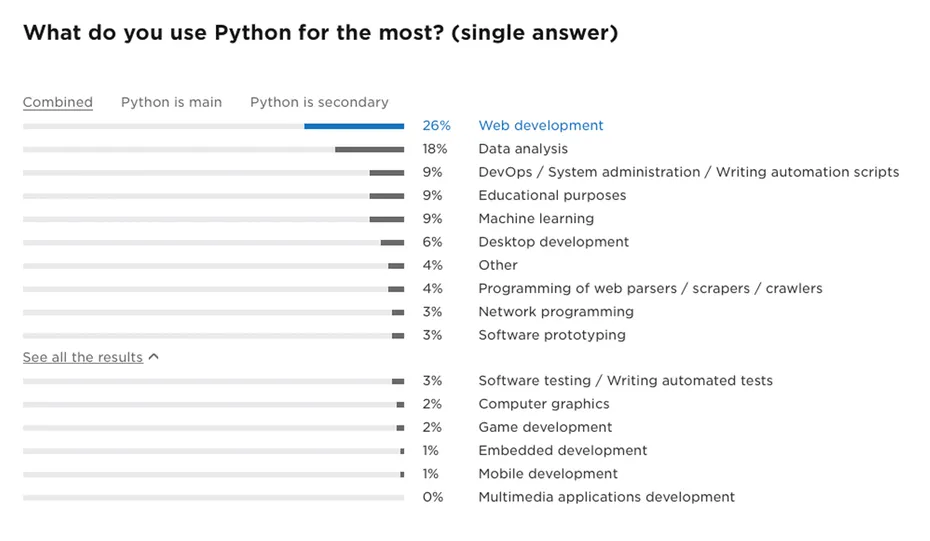
نظرسنجی که سایت StackOverflow، از توسعهدهندگان به عمل آورده، نشان میدهد، پایتون در میان 5 زبان محبوب جهان است، در حالی که بالغ بر 700 زبان برنامهنویسی یا بیشتر وجود دارند که هر یک حرفهای زیادی برای گفتن دارند.
این نظرسنجی، نشان داد که 26٪ توسعهدهندگان پایتون از این زبان برای توسعه وب استفاده میکنند، بنابراین 26٪ از جامعه پایتون را توسعهدهندگان وب تشکیل میدهند، یادگیری ماشین و تجزیه و تحلیل دادهها با مقدار ترکیبی 27٪ در رتبه دوم قرار دارند. انجمن و فرمهای یادگیری ماشین پایتون بسیار بزرگ هستند و این بدان معنا است که شما به راحتی میتوانید هر زمان با مشکلی روبرو شدید، از کمک این توسعهدهندگان استفاده کنید. در شکل زیر نتایج نظرسنجی انجام شده توسط StackOverflow از توسعهدهندگان را مشاهده میکنید.
پایتون به واسطه کتابخانه قدرتمند جنگو گزینه مناسبی برای توسعه وب است. علاوه بر این، کتابخانههایی مثل تنسورفلور، پایتورچ، اسکیتلرن و نمونههای مشابه نقش مهمی در انتخاب پایتون به عنوان گزینه اصلی در حوزه یادگیری ماشین داشتهاند.
اکنون که متوجه شدیم، چرا پایتون مناسبترین گزینه در تعامل با یادگیری ماشین است، به این پرسش مهم میرسیم که آیا جایگزینهای دیگری نیز وجود دارند یا خیر.
سایر زبانهای مورد استفاده برای یادگیری ماشین
حوزه هوش مصنوعی و یادگیری ماشین هنوز هم در حال رشد است و اگرچه پایتون زبان اصلی برای یادگیری ماشین است و ممکن است در سالهای آتی نیز همین روال ادامه پیدا کند، اما گزینههای کاربردی دیگری نیز وجود دارند که در این مقاله به طور خلاصه به آنها اشاره میکنیم.
آر (R)

زبان برنامهنویسی آر زمانی استفاده میشود که شما نیاز به تجزیه و تحلیل و دستکاری دادهها برای اهداف آماری دارید. R دارای بستههایی مانند Models ،Class ،Tm و RODBC است که معمولا برای ساخت پروژههای یادگیری ماشین استفاده میشود. این بستهها به توسعهدهندگان اجازه میدهد تا الگوریتمهای یادگیری ماشین را بدون دردسر اضافی پیادهسازی کنند و به آنها اجازه میدهد تا به سرعت منطق تجاری را پیادهسازی کنند.
R توسط آماردانان برای رفع نیازهای متخصصان این رشته توسعه پیدا کرد. این زبان میتواند تجزیه و تحلیل آماری عمیقی را به شما ارائه دهد، چه در حال مدیریت دادههای یک دستگاه اینترنت اشیا یا تجزیه و تحلیل مدلهای مالی باشید.
اسکالا (Scala)

وقتی صحبت از کلان داده به میان میآید اسکالا گزینه ارزشمندی خواهد بود. این زبان برنامهنویسی توسط مجموعهای از ابزارها مانند Saddle، Scala-lab و Breeze از دانشمندان داده پشتیبانی میکند. اسکالا، از مکانیزم همزمان به بهترین شکل پشتیبانی میکند که نقش مهمی در پردازش حجم زیادی از دادهها دارد.
از آنجایی که اسکالا روی ماشین مجازی جاوا (JVM) اجرا میشود، در تعامل با هدوپ (Hadoop) که یک چارچوب پردازش توزیعشده منبع باز است، میتواند برای پردازش و ذخیرهسازی دادهها در ارتباط با برنامههای کلان داده که روی سیستمهای خوشهای اجرا میشوند، مورد استفاده قرار گیرد. با اینحال، در مقایسه با پایتون و آر، ابزارهای یادگیری ماشین کمتری برای این زبان ارائه شده است.
جولیا (Julia)

اگر نیاز به تعریف راهحلی برای محاسبات و تحلیلهای با کارایی بالا دارید، جولیا گزینه خوبی است. جولیا ترکیبی مشابه پایتون دارد و برای انجام وظایف محاسبات عددی طراحی شده است. جولیا از طریق بسته TensorFlow.jl و چارچوب Mocha از یادگیری عمیق پشتیبانی میکند. با این حال، کتابخانههای کمی از این زبان پشتیبانی میکنند و هنوز جامعه قوی مانند پایتون برای این زبان وجود ندارد.
جاوا (Java)

زبان دیگری که حرفهای زیادی برای گفتن در دنیای یادگیری ماشین دارد، جاوا است. جاوا شیگرا، قابل حمل، همهمنظوره، با قابلیت نگهداری بالا است که دستورات آن ترکیب نحوی شفافی دارند. این زبان توسط کتابخانههای متعدد و قدرتمندی مثل WEKA و Rapidminer پشتیبانی میشود. جاوا زمانی که صحبت از پردازش زبان طبیعی، الگوریتمهای جستوجو و شبکههای عصبی به میان میآید، انتخاب مناسبی است. در نتیجه به شما امکان میدهد به سرعت سیستمهای در مقیاس بزرگ با عملکرد عالی بسازید. اگر میخواهید مدلسازی و تجسم آماری انجام دهید، جاوا در مقایسه با زبانهای ذکر شده، چندان کارآمد نیست.
اگرچه برخی از بستههای جاوا از مدلسازی و تجسم آماری پشتیبانی میکنند، اما قدرت و توانایی زبانهایی مثل پایتون را ندارد. در نقطه مقابل، پایتون ابزارهای پیشرفتهای در اختیار دارد که به توسعهدهندگان در این زمینه کمک میکند.
کلام آخر
در این مقاله سعی کردیم، به طور اجمالی دید روشنی در ارتباط با دلایل استفاده از پایتون در یادگیری ماشین، تفاوت یادگیری ماشین و یادگیری عمیق و زبانهایی که برای برنامهنویسی یادگیری ماشین مناسب هستند در اختیارتان قرار دهیم. اگر نظر یا انتقادی نسبت به این مقاله دارید، خوشحال میشویم با ما به اشتراک بگذارید.
این مطلب برگرفته از سایت سکان آکادمی است.